

Introducción a Python Pandas DataFrame
Múltiples expansiones para la Biblioteca Python, Pandas, se pueden encontrar en línea. Uno de ellos es Panel (pan) Data (das). Esta palabra, * Panel * insinúa sutilmente una estructura de datos bidimensional presente en esta biblioteca, lo que empodera inmensamente a sus usuarios. Esta misma estructura se llama DataFrame.
Es esencialmente una matriz de filas y columnas, que contiene todo su conjunto de datos, con opciones muy elaboradas de indexar el mismo. El DataFrame (DF) se puede imaginar pictóricamente muy similar a una hoja de Excel. Pero lo que lo hace poderoso es la facilidad con la que se pueden realizar operaciones analíticas y transformacionales sobre los datos almacenados en un DataFrame.
¿Qué es exactamente un marco de datos de Python Pandas?
La página de Pydata se puede referir a una definición oficial.
Si se entiende correctamente, menciona DataFrame como una estructura columnar, capaz de almacenar cualquier objeto de Python (incluido un DataFrame) como un valor de celda. (Una celda se indexa usando una combinación única de fila y columna)
DataFrames consta de tres componentes esenciales: datos, filas y columnas.
- Datos: se refiere a los objetos / entidades reales almacenados en una celda en el DataFrame y los valores representados por estas entidades. Un objeto es de cualquier tipo de datos de Python válido, ya sea incorporado o definido por el usuario.
- Filas: las referencias utilizadas para identificar (o indexar) un conjunto particular de observaciones de los datos completos almacenados en un DataFrame se denominan Filas. Solo para que quede claro, representa los índices utilizados y no solo los datos en una observación particular.
- Columnas: referencias utilizadas para identificar (o indexar) un conjunto de atributos para todas las observaciones en un DataFrame. Como en el caso de las filas, se refieren al índice de la columna (o los encabezados de las columnas) en lugar de solo los datos de la columna.
Entonces, sin más preámbulos, intentemos algunas formas de crear estas estructuras increíblemente poderosas.
Pasos para crear marcos de datos de Python Pandas
Se puede crear un DataFrame de Python Pandas utilizando la siguiente implementación de código,
1. Importar pandas
Para crear DataFrames, la biblioteca de pandas debe importarse (no es sorprendente aquí). Lo importaremos con un pd de alias para hacer referencia a objetos en el módulo convenientemente.
Código:
import pandas as pd
2. Crear el primer objeto DataFrame
Una vez que se importa la biblioteca, todos los métodos, funciones y constructores están disponibles en su espacio de trabajo. Entonces, intentemos crear un DataFrame de vainilla.
Código:
import pandas as pd
df = pd.DataFrame()
print(df)
Salida:
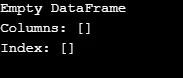
Como se muestra en la salida, el constructor devuelve un DataFrame vacío.
Centrémonos ahora en crear DataFrames a partir de datos almacenados en algunas de las representaciones probables.
- DataFrame de un diccionario: Digamos que tenemos un diccionario que almacena una lista de empresas en Software Domain y la cantidad de años que han estado activas.
Código:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Veamos la representación del objeto DataFrame devuelto imprimiéndolo en la consola.
Salida:

Como puede verse, cada clave del diccionario se trata como una columna en el DataFrame, y los índices de fila se generan automáticamente a partir de 0. Bastante fácil, ¿eh?
Ahora supongamos que desea darle un índice personalizado en lugar de 0, 1, .. 4. Solo necesita pasar la lista deseada como parámetro al constructor y los pandas harán lo necesario.
Código:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Salida:
Edad de la empresa
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Ahora puede establecer índices de fila a cualquier valor deseado.
- DataFrame de un archivo CSV: creemos un archivo CSV que contenga los mismos datos que en el caso de nuestro diccionario. Llamemos al archivo CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
El archivo se puede cargar en un marco de datos (suponiendo que esté presente en el directorio de trabajo actual) de la siguiente manera.
Código:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Salida:
Edad de la empresa
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Establecer los nombres de los parámetros , omitiendo una lista de valores, los asigna como encabezados de columna en el mismo orden en que están presentes en la lista. Del mismo modo, los índices de fila se pueden establecer pasando una lista al parámetro de índice, como se muestra en la sección anterior. El encabezado = Ninguno indica que faltan encabezados de columna en el archivo de datos.
Ahora digamos que los nombres de las columnas eran parte del archivo de datos. Luego, configurar header = False hará el trabajo requerido.
3. CompanyAgeWithHeader.csv
Empresa, edad
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
El código cambiará a
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Salida:
Edad de la empresa
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame de un archivo de Excel: a menudo los datos se comparten en archivos de Excel, ya que sigue siendo la herramienta más popular utilizada por la gente común para el seguimiento de Adhoc. Por lo tanto, no debería ser ignorado por nuestra discusión.
Supongamos que los datos, al igual que en CompanyAgeWithHeader.csv ahora se almacenan en CompanyAgeWithHeader.xlsx, en una hoja con el nombre Company Age. El mismo código creará el mismo DataFrame que el anterior.
Código:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Salida:
Edad de la empresa
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Como puede ver, se puede crear el mismo DataFrame pasando el nombre del archivo y el nombre de la hoja.
Lecturas adicionales y próximos pasos
Los métodos mostrados constituyen un subconjunto muy pequeño en comparación con todas las diferentes formas en que se pueden crear DataFrames. Estos fueron creados con la intención de comenzar uno. Definitivamente, debe explorar las referencias enumeradas e intentar explorar otras formas, incluida la conexión a una base de datos para leer datos directamente en un DataFrame.
Conclusión
Pandas DataFrame ha demostrado ser un cambio de juego en el mundo de la ciencia de datos y el análisis de datos, así como es conveniente para proyectos ad-hoc a corto plazo. Viene con un ejército de herramientas capaces de cortar y cortar el conjunto de datos con extrema facilidad. Con suerte, esto servirá como un trampolín en su viaje por delante.
Artículos recomendados
Esta es una guía de Python-Pandas DataFrame. Aquí discutimos los pasos para crear el marco de datos de python-pandas junto con su implementación de código. También puede consultar los siguientes artículos para obtener más información:
- Las 15 características principales de Python
- Diferentes tipos de conjuntos de Python
- Los 4 tipos principales de variables en Python
- Los 6 mejores editores de Python
- Matrices en estructura de datos