

Introducción a los comandos de Spark
Apache Spark es un marco construido sobre Hadoop para cálculos rápidos. Extiende el concepto de MapReduce en el escenario basado en clúster para ejecutar una tarea de manera eficiente. Spark Command está escrito en Scala.
Hadoop puede ser utilizado por Spark de las siguientes maneras (ver más abajo):
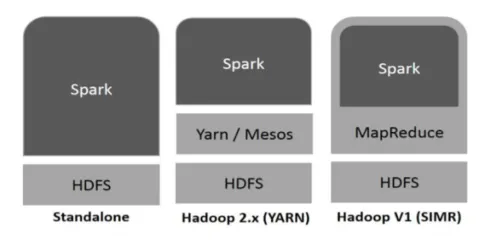
Figura 1
https://www.tutorialspoint.com/
- Independiente: Spark desplegado directamente sobre Hadoop. Los trabajos de Spark se ejecutan paralelamente en Hadoop y Spark.
- Hadoop YARN: Spark se ejecuta en Yarn sin necesidad de ninguna instalación previa.
- Spark en MapReduce (SIMR): Spark en MapReduce se utiliza para iniciar el trabajo de chispa, además de la implementación independiente. Con SIMR, uno puede iniciar Spark y puede usar su shell sin ningún acceso administrativo.
Componentes de chispa:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- GraphX
Los conjuntos de datos distribuidos resilientes (RDD) se consideran la estructura de datos fundamental de los comandos de Spark. RDD es inmutable y de solo lectura. Todo tipo de cálculos en los comandos spark se realiza a través de transformaciones y acciones en RDD.
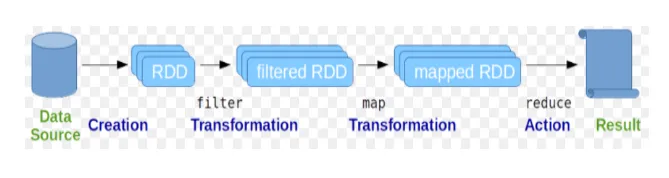
Figura 2
Imagen de Google
Spark Shell proporciona un medio para que los usuarios interactúen con sus funcionalidades. Los comandos de Spark tienen muchos comandos diferentes que se pueden usar para procesar datos en el shell interactivo.
Comandos básicos de chispa
Echemos un vistazo a algunos de los comandos básicos de Spark que se proporcionan a continuación:
-
Para iniciar el shell Spark:

Fig. 3
-
Leer el archivo del sistema local:

Aquí "sc" es el contexto de chispa. Teniendo en cuenta que "data.txt" está en el directorio de inicio, se lee así, de lo contrario hay que especificar la ruta completa.
-
Crear RDD a través de la paralelización

NewData es el RDD ahora.
-
Contar elementos en RDD

-
Recoger
Esta función devuelve todo el contenido del RDD al programa del controlador. Esto es útil para depurar en varios pasos del programa de escritura.
-
Lea los primeros 3 elementos de RDD

-
Guardar datos de salida / procesados en el archivo de texto

Aquí la carpeta de "salida" es la ruta actual.
Comandos intermedios de chispa
1. Filtro en RDD
Creemos un nuevo RDD para los elementos que contienen "sí".

El filtro de transformación debe llamarse en el RDD existente para filtrar la palabra "sí", lo que creará un nuevo RDD con la nueva lista de elementos.
2. Operación de la cadena

Aquí la transformación del filtro y la acción de recuento actuaron juntas Esto se llama operación en cadena.
3. Lea el primer artículo de RDD

4. Contar particiones RDD
Como sabemos, RDD está hecho de múltiples particiones, ocurre la necesidad de contar el no. de particiones. Como ayuda en el ajuste y la resolución de problemas mientras se trabaja con comandos de Spark.

Por defecto, el mínimo no. La partición pf es 2.
5. unirse
Esta función une dos tablas (el elemento de tabla está en pares) en función de la clave común. En RDD por pares, el primer elemento es la clave y el segundo elemento es el valor.
6. Caché de un archivo
El almacenamiento en caché es una técnica de optimización. El almacenamiento en caché de RDD significa que RDD residirá en la memoria y todos los cálculos futuros se realizarán en esos RDD en la memoria. Ahorra el tiempo de lectura del disco y mejora el rendimiento. En resumen, reduce el tiempo de acceso a los datos.

Sin embargo, los datos no se almacenarán en caché si ejecuta la función anterior. Esto se puede probar visitando la página web:
http: // localhost: 4040 / almacenamiento
RDD se almacenará en caché, una vez que se realice la acción. Por ejemplo:

Una función más que funciona de manera similar a cache () es persistir (). Persist brinda a los usuarios la flexibilidad de dar el argumento, lo que puede ayudar a que los datos se almacenen en la memoria caché, el disco o la memoria fuera del montón. Persistir sin ningún argumento funciona igual que cache ().
Comandos avanzados de chispa
Echemos un vistazo a algunos de los comandos avanzados de Spark que se proporcionan a continuación:
-
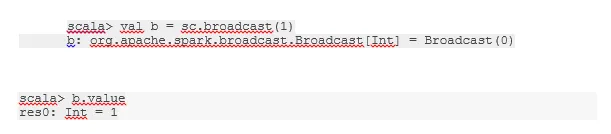
Transmitir una variable
La variable de difusión ayuda al programador a seguir leyendo la única variable almacenada en caché en cada máquina del clúster, en lugar de enviar una copia de esa variable con las tareas. Esto ayuda a reducir los costos de comunicación.
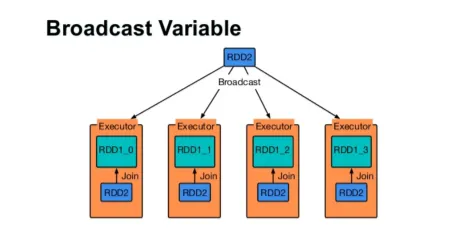
Higo 4
imagen de Google
En resumen, hay tres características principales de la variable Broadcast:
- Inmutable
- Encajar en la memoria
- Distribuido en clúster
-
Acumuladores
Los acumuladores son las variables que se agregan a las operaciones asociadas. Hay muchos usos para acumuladores como contadores, sumas, etc.

El nombre del acumulador en el código también se puede ver en Spark UI.
-
Mapa
La función de mapa ayuda a iterar sobre cada línea en RDD. La función utilizada en el mapa se aplica a cada elemento en RDD.
Por ejemplo, en RDD (1, 2, 3, 4, 6) si aplicamos “rdd.map (x => x + 2)” obtendremos el resultado como (3, 4, 5, 6, 8).
-
Mapa plano
El mapa plano funciona de manera similar al mapa, pero el mapa solo devuelve un elemento, mientras que el mapa plano puede devolver la lista de elementos. Por lo tanto, dividir las oraciones en palabras necesitará un mapa plano.
-
Juntarse
Esta función ayuda a evitar la combinación de datos. Esto se aplica en la partición existente para que se mezclen menos datos. De esta manera, podemos restringir el uso de nodos en el clúster.
Consejos y trucos para usar los comandos de chispa
A continuación se presentan los diferentes consejos y trucos de los comandos de Spark: -
- Los principiantes de Spark pueden usar Spark-shell. Como los comandos Spark están construidos en Scala, definitivamente usar scala spark shell es genial. Sin embargo, python spark shell también está disponible, por lo que incluso eso es algo que uno puede usar, que está bien versado en python.
- Spark Shell tiene muchas opciones para administrar los recursos del clúster. El siguiente comando puede ayudarlo con eso:

- En Spark, trabajar con conjuntos de datos largos es lo habitual. Pero las cosas salen mal cuando se toman datos incorrectos. Siempre es una buena idea eliminar filas incorrectas utilizando la función de filtro de Spark. El buen conjunto de aportes será una gran oportunidad.
- Spark elige una buena partición propia para sus datos. Pero siempre es una buena práctica vigilar las particiones antes de comenzar su trabajo. Probar diferentes particiones lo ayudará con el paralelismo de su trabajo.
Conclusión - Comandos Spark:
El comando Spark es un motor de big data revolucionario y versátil, que puede funcionar para el procesamiento por lotes, el procesamiento en tiempo real, el almacenamiento en caché de datos, etc. Aplicaciones rápidas.
Artículos recomendados
Esta ha sido una guía para los comandos de Spark. Aquí hemos discutido los comandos básicos y avanzados de Spark y algunos comandos inmediatos de Spark. También puede consultar el siguiente artículo para obtener más información:
- Comandos de Adobe Photoshop
- Comandos importantes de VBA
- Comandos de Tableau
- Cheat sheet SQL (comandos, consejos gratuitos y trucos)
- Tipos de combinaciones en Spark SQL (ejemplos)
- Componentes de chispa | Descripción general y los 6 componentes principales