

Introducción a la arquitectura HBase
HBase es un sistema de almacenamiento de datos de valor clave distribuido de código abierto y una base de datos orientada a columnas con alto rendimiento de escritura y rendimiento de lectura aleatoria de baja latencia. Al usar HBase, podemos realizar análisis en línea en tiempo real. La arquitectura HBase tiene una legibilidad aleatoria fuerte. En HBase, los datos se dividen físicamente en lo que se conoce como regiones. Cada región está alojada por un único servidor de región, y una o más regiones son responsables de cada servidor de región. La arquitectura HBase está compuesta por servidores maestro-esclavo. El clúster HBase tiene un nodo maestro llamado HMaster y varios servidores de región llamados HRegion Server (HRegion Server). Hay varias regiones: regiones en cada servidor regional.
Mecanismo de almacenamiento HDFS

En HDFS, los datos se almacenan en la tabla como se muestra arriba.
Cada fila tiene una clave.
Columna: es una colección de datos que pertenece a una familia de columnas y se incluye dentro de la fila.
Familia de columnas: cada familia de columnas consta de una o más columnas.
Cada tabla contiene una colección de familias de columnas. Estas columnas no son parte del esquema.
HBase tiene columnas dinámicas. Las diferentes celdas pueden tener diferentes columnas porque los nombres de las columnas están codificados dentro de las celdas
Calificador de columna: el nombre de columna se conoce como calificador de columna.
Componentes de la arquitectura HBase
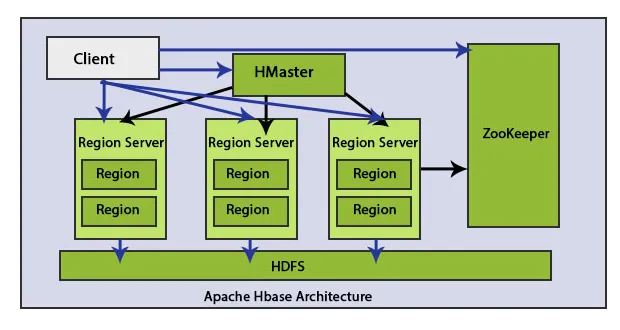
Hay elementos principales en la arquitectura de HBase: HMaster y Region Server. Datos regionales de ahorro de HBase.
1. HMaster
El nodo HMaster es liviano y se usa para asignar la región a la región del servidor.
Hay algunas responsabilidades principales de Hmaster que son:
- Llevar a cabo algunas tareas de administración, incluidas la carga, el equilibrio, la creación de datos, la actualización, la eliminación, etc.
Responsable de cambios en el esquema o modificaciones en los datos META de acuerdo con la dirección de la aplicación del cliente
- HMaster maneja gran parte del trabajo DDL en las tablas HBase.
Algunos de los métodos que expone la interfaz HMaster son principalmente. META métodos orientados a datos.
- Tabla (crear, eliminar, habilitar, deshabilitar, eliminar tabla)
- ColumnFamily (agregar columna, modificar columna)
- Región (mover, asignar)
El cliente se comunica con HMaster y ZooKeeper bidireccionalmente. Se pone en contacto con servidores HRegion directamente para leer y escribir operaciones. HMaster asigna regiones a los servidores de la región y, a su vez, verifica el estado de los servidores regionales.
2. Servidor de región
Podemos obtener una idea aproximada sobre el servidor de la región mediante un diagrama que se muestra a continuación.

Los servidores de región son nodos de trabajo que manejan las solicitudes de los clientes para leer, escribir, actualizar y eliminar. El servidor de región es ligero, se ejecuta en todos los nodos del clúster Hadoop. La tarea principal del servidor regional es guardar los datos en áreas y realizar las solicitudes de los clientes. Otra tarea importante de HBase Region Server es utilizar el método de Auto-Sharding para realizar el equilibrio de carga distribuyendo dinámicamente la tabla HBase cuando se vuelve demasiado grande después de insertar datos.
HMaster puede contactar con varios servidores HRegion y realizar las siguientes funciones:
- Hosting de gestión y regiones
- Regiones divididas automáticamente
- Manejo de solicitudes de lectura y escritura.
- Comunicación directa con el cliente
3. HDFS
HDFS significa el sistema de archivos distribuidos de Hadoop. Almacena cada archivo en varios bloques y replica bloques en un clúster de Hadoop para mantener la tolerancia a fallas. HDFS ofrece alta tolerancia a fallas y funciona con materiales de bajo costo. Al usar hardware de bajo costo para agregar nodos al clúster y procesarlo y guardarlo, le dará al cliente mejores resultados que el hardware existente. HDFS contacta los componentes de HBase y guarda muchos datos de forma distribuida.
4. Zookeeper
Zookeeper es un proyecto de código abierto. HMaster y HRegionServers se registran en ZooKeeper.
Proporciona varios servicios, como mantener información de configuración, nombrar, proporcionar sincronización distribuida, etc. La sincronización distribuida es el proceso de proporcionar servicios de coordinación entre nodos para acceder a las aplicaciones en ejecución. Tiene nodos efímeros que representan servidores de región. Los servidores maestros usan estos nodos para buscar servidores disponibles.
Estos nodos también se utilizan para rastrear particiones de red y fallas del servidor. Zookeeper es el medio de interacción entre el servidor de la región del Cliente. Si un cliente quiere comunicarse con el servidor de la región, entonces zookeeper es el medio de comunicación entre ellos.
Cómo se inicializa la búsqueda en la arquitectura HBase
Como sabes, Zookeeper guarda la ubicación de la tabla META. Cada vez que un cliente se acerca o escribe solicitudes para HBase, el procedimiento es el siguiente.
El cliente descubre en ZooKeeper cómo colocarlos en la mesa META. Luego, el cliente solicita la clave de fila apropiada de la tabla META para acceder a la ubicación del servidor de la región. Con la ubicación de la tabla META, el cliente almacena en caché esta información. El cliente no deberá referirse a la tabla META hasta y si el área se mueve o cambia. Luego se volverá a solicitar el servidor META y se actualizará el caché. Como siempre, los clientes no pierden el tiempo buscando la ubicación del Servidor de Región en META Server, por lo que ahorra tiempo y acelera el proceso de búsqueda.
Caracteristicas
Es fácil de integrar desde el origen y el destino con Hadoop.
El almacenamiento distribuido como HDFS es compatible.
Tiene una función de acceso aleatorio mediante el uso de una tabla hash interna para almacenar datos para búsquedas más rápidas en archivos HDFS.
Ventajas de la arquitectura HBase
- Estos pueden almacenar grandes conjuntos de datos
- Podemos compartir la base de datos
- Gigabytes a petabytes rentable
- Alta disponibilidad a través de replicación y falla
Desventajas de la arquitectura HBase
- La estructura SQL no es compatible
- No admite transacciones
- Solo con llave ordenada
- Problemas de memoria de clúster
Conclusión
HBase es una de las bases de datos distribuidas orientadas a columnas no SQL en apache. Al comparar con Hadoop o Hive, HBase funciona mejor para recuperar menos registros. Entonces, en este artículo, discutimos la arquitectura HBase y sus componentes importantes.
Artículos recomendados
Esta ha sido una guía de HBase Architecture. Aquí discutimos el Concepto, Componentes, Características, Ventajas y Desventajas. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- ¿Qué es la tecnología Big Data?
- HDFS vs HBase ¿Cuál es mejor?
- ¿Qué es el lenguaje ensamblador?
- Introducción a HTML