
Introducción a los modelos de aprendizaje automático
Una visión general de varios modelos de aprendizaje automático utilizados en la práctica. Según la definición, un modelo de aprendizaje automático es una configuración matemática obtenida después de aplicar metodologías específicas de aprendizaje automático. Usando la amplia gama de API, construir un modelo de aprendizaje automático es bastante sencillo hoy en día con menos líneas de códigos. Pero la verdadera habilidad de un profesional de la ciencia de datos aplicados radica en elegir el modelo correcto basado en la declaración del problema y la validación cruzada en lugar de arrojar datos a algoritmos sofisticados al azar. En este artículo, discutiremos varios modelos de aprendizaje automático y cómo usarlos de manera efectiva en función del tipo de problemas que abordan.
Tipos de modelos de aprendizaje automático
Según el tipo de tareas, podemos clasificar los modelos de aprendizaje automático en los siguientes tipos:
- Modelos de clasificación
- Modelos de regresión
- Agrupamiento
- Reducción de dimensionalidad
- Aprendizaje profundo, etc.
1) Clasificación
Con respecto al aprendizaje automático, la clasificación es la tarea de predecir el tipo o clase de un objeto dentro de un número finito de opciones. La variable de salida para la clasificación es siempre una variable categórica. Por ejemplo, predecir que un correo electrónico es spam o no es una tarea de clasificación binaria estándar. Ahora tomemos nota de algunos modelos importantes para problemas de clasificación.
- Algoritmo de vecinos K-Nearest: simple pero computacionalmente exhaustivo.
- Bayes ingenuos - Basado en el teorema de Bayes.
- Regresión logística: modelo lineal para clasificación binaria.
- SVM: se puede utilizar para clasificaciones binarias / multiclase.
- Árbol de decisión: clasificador basado en ' If Else ', más robusto para los valores atípicos.
- Conjuntos: combinación de varios modelos de aprendizaje automático agrupados para obtener mejores resultados.
2) regresión
En la máquina, la regresión de aprendizaje es un conjunto de problemas donde la variable de salida puede tomar valores continuos. Por ejemplo, predecir el precio de la aerolínea puede considerarse como una tarea de regresión estándar. Anotemos algunos modelos de regresión importantes utilizados en la práctica.
- Regresión lineal: el modelo de línea de base más simple para la tarea de regresión, funciona bien solo cuando los datos son linealmente separables y hay muy poca o ninguna multicolinealidad presente.
- Regresión de lazo - Regresión lineal con regularización L2.
- Regresión de cresta: regresión lineal con regularización L1.
- Regresión SVM
- Regresión del árbol de decisiones, etc.
3) Agrupación
En palabras simples, la agrupación es la tarea de agrupar objetos similares. Los modelos de aprendizaje automático ayudan a identificar objetos similares automáticamente sin intervención manual. No podemos construir modelos de aprendizaje automático supervisados efectivos (modelos que necesitan ser entrenados con datos seleccionados o etiquetados manualmente) sin datos homogéneos. La agrupación nos ayuda a lograr esto de una manera más inteligente. Los siguientes son algunos de los modelos de agrupación más utilizados:
- K significa - Simple pero sufre de alta varianza.
- K significa ++ - Versión modificada de K significa.
- K medoides.
- Agrupación aglomerativa: un modelo de agrupación jerárquica.
- DBSCAN: algoritmo de agrupación basado en densidad, etc.
4) Reducción de dimensionalidad
La dimensionalidad es el número de variables predictoras utilizadas para predecir la variable independiente o el objetivo. A menudo, en los conjuntos de datos del mundo real, el número de variables es demasiado alto. Demasiadas variables también traen la maldición del sobreajuste a los modelos. En la práctica, entre estos grandes números de variables, no todas las variables contribuyen igualmente a la meta y, en un gran número de casos, podemos preservar las variaciones con un menor número de variables. Hagamos una lista de algunos modelos de uso común para la reducción de dimensionalidad.
- PCA: crea un menor número de nuevas variables a partir de un gran número de predictores. Las nuevas variables son independientes entre sí pero menos interpretables.
- TSNE: proporciona incrustación de menor dimensión de puntos de datos de mayor dimensión.
- SVD: la descomposición de valores singulares se utiliza para descomponer la matriz en partes más pequeñas para un cálculo eficiente.
5) aprendizaje profundo
El aprendizaje profundo es un subconjunto del aprendizaje automático que se ocupa de las redes neuronales. Basado en la arquitectura de las redes neuronales, enumeremos modelos importantes de aprendizaje profundo:
- Perceptrón multicapa
- Redes neuronales de convolución
- Redes neuronales recurrentes
- Máquina Boltzmann
- Autoencoders etc.
¿Qué modelo es el mejor?
Arriba tomamos ideas sobre muchos modelos de aprendizaje automático. Ahora nos viene a la mente una pregunta obvia: ¿Cuál es el mejor modelo entre ellos? Depende del problema en cuestión y otros atributos asociados, como valores atípicos, el volumen de datos disponibles, la calidad de los datos, la ingeniería de características, etc. En la práctica, siempre es preferible comenzar con el modelo más simple aplicable al problema y aumentar la complejidad gradualmente mediante el ajuste adecuado de los parámetros y la validación cruzada. Existe un proverbio en el mundo de la ciencia de datos: "La validación cruzada es más confiable que el conocimiento del dominio".
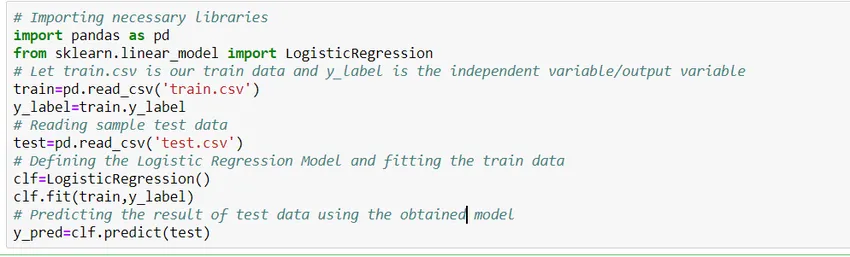
¿Cómo construir un modelo?
Veamos cómo construir un modelo de regresión logística simple usando la biblioteca Scikit Learn de python. Por simplicidad, estamos asumiendo que el problema es un modelo de clasificación estándar y 'train.csv' es el tren y 'test.csv' es el tren y los datos de prueba respectivamente.
Conclusión
En este artículo, discutimos los importantes modelos de aprendizaje automático utilizados con fines prácticos y cómo construir un modelo simple de aprendizaje automático en Python. Elegir un modelo adecuado para un caso de uso particular es muy importante para obtener el resultado adecuado de una tarea de aprendizaje automático. Para comparar el rendimiento entre varios modelos, se definen métricas de evaluación o KPI para problemas comerciales particulares y se elige el mejor modelo para la producción después de aplicar la verificación estadística del rendimiento.
Artículos recomendados
Esta es una guía de modelos de aprendizaje automático. Aquí discutimos los 5 tipos principales de modelos de aprendizaje automático con su definición. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Métodos de aprendizaje automático
- Tipos de aprendizaje automático
- Algoritmos de aprendizaje automático
- ¿Qué es el aprendizaje automático?
- Aprendizaje automático de hiperparámetros
- KPI en Power BI
- Algoritmo de agrupamiento jerárquico
- Agrupación jerárquica | Agrupamiento Aglomerativo y Divisivo