

Introducción a la técnica de aprendizaje profundo
La técnica de aprendizaje profundo se basa en redes neuronales artificiales que actúan como un cerebro humano. Imita la forma en que el cerebro humano piensa y actúa. En este modelo, el sistema aprende y realiza la clasificación a partir de imágenes, texto o sonido. Los modelos de Deep Learning están entrenados por grandes datos etiquetados y de múltiples capas para lograr una alta precisión en el resultado, incluso más que el nivel humano. El automóvil sin conductor aplica esta tecnología para identificar señales de alto, peatones, etc. en locomoción. Los dispositivos electrónicos como teléfonos móviles, altavoces, TV, computadoras, etc. tienen una función de control de voz debido a Deep Learning. Esta técnica es nueva y eficiente para consumidores y organizaciones.
Trabajo de aprendizaje profundo
Los métodos de aprendizaje profundo utilizan redes neuronales. Por lo tanto, a menudo se les conoce como Redes neuronales profundas. Las redes neuronales profundas u ocultas tienen múltiples capas ocultas de redes profundas. Deep Learning entrena a la IA para predecir la salida con la ayuda de ciertas entradas o capas de red ocultas. Estas redes están formadas por grandes conjuntos de datos etiquetados y aprenden características de los datos en sí. Tanto el aprendizaje supervisado como el no supervisado funcionan para entrenar los datos y generar características.
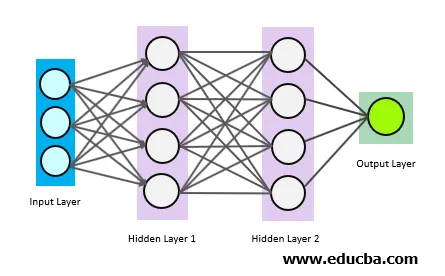
Los círculos anteriores son neuronas que están interconectadas. Hay 3 tipos de neuronas:
- Capa de entrada
- Capa (s) oculta (s)
- Capa de salida
La capa de entrada obtiene los datos de entrada y pasa la entrada a la primera capa oculta. Los cálculos matemáticos se realizan sobre los datos de entrada. Finalmente, la capa de salida da los resultados.
CNN o redes neuronales convencionales, una de las redes neuronales más populares involucra características aprendidas de los datos de entrada y utiliza capas convolucionales 2D para que sea adecuado para procesar datos 2D como imágenes. Entonces, CNN reduce el uso de extracción manual de características en este caso. Extrae directamente las características requeridas de las imágenes para su clasificación. Debido a esta característica de automatización, CNN es un algoritmo en su mayoría preciso y confiable en Machine Learning. Cada CNN aprende las características de las imágenes de la capa oculta y estas capas ocultas aumentan la complejidad de las imágenes aprendidas.
La parte importante es entrenar la IA o las redes neuronales. Para hacerlo, damos información del conjunto de datos y finalmente hacemos una comparación de las salidas con la ayuda de la salida del conjunto de datos. Si la IA no está entrenada, la salida puede estar equivocada.
Para descubrir qué tan equivocada está la salida de la IA de la salida real, necesitamos una función para el cálculo. La función se llama función de costo. Si la función de costo es cero, tanto la salida de AI como la salida real son iguales. Para reducir el valor de la función de costo, cambiamos los pesos entre las neuronas. Para un enfoque conveniente, se puede utilizar una técnica llamada Descenso de gradiente. GD reduce el peso de las neuronas a un mínimo después de cada iteración. Este proceso se realiza automáticamente.
Técnica de aprendizaje profundo
Los algoritmos de aprendizaje profundo se ejecutan a través de varias capas de las capas ocultas o redes neuronales. Entonces, aprenden profundamente sobre las imágenes para una predicción precisa. Cada capa aprende y detecta características de bajo nivel como bordes y, posteriormente, la nueva capa se combina con las características de la capa anterior para una mejor representación. Por ejemplo, una capa intermedia puede detectar cualquier borde del objeto, mientras que la capa oculta detectará el objeto completo o la imagen.
Esta técnica es eficiente con datos grandes y complejos. Si los datos son pequeños o incompletos, DL se vuelve incapaz de trabajar con datos nuevos.
Hay algunas redes de aprendizaje profundo de la siguiente manera:
- Red pre-entrenada no supervisada : es un modelo básico con 3 capas: capa de entrada, oculta y de salida. La red está capacitada para reconstruir la entrada y luego las capas ocultas aprenden de las entradas para recopilar información y, finalmente, las características se extraen de la imagen.
- Red neuronal convencional : como red neuronal estándar, tiene una convolución interna para la detección de bordes y el reconocimiento preciso de objetos.
- Red neuronal recurrente : en esta técnica, la salida de la etapa anterior se utiliza como entrada para la etapa siguiente o actual. RNN almacena la información en nodos de contexto para aprender los datos de entrada y producir la salida. Por ejemplo, para completar una oración necesitamos palabras. es decir, para predecir la siguiente palabra, se requieren palabras previas que deben recordarse. RNN básicamente resuelve este tipo de problema.
- Redes neuronales recursivas : es un modelo jerárquico donde la entrada es una estructura en forma de árbol. Este tipo de red se crea aplicando el mismo conjunto de pesos sobre el conjunto de entradas.
Deep Learning tiene una variedad de aplicaciones en los campos financieros, visión por computadora, reconocimiento de audio y voz, análisis de imágenes médicas, técnicas de diseño de medicamentos, etc.
¿Cómo crear modelos de aprendizaje profundo?
Los algoritmos de aprendizaje profundo se crean conectando capas entre ellos. El primer paso anterior es la capa de entrada seguida de la (s) capa (s) oculta (s) y la capa de salida. Cada capa está compuesta de neuronas interconectadas. La red consume una gran cantidad de datos de entrada para operarlos a través de múltiples capas.
Para crear un modelo de aprendizaje profundo, se necesitan los siguientes pasos:
- Entendiendo el problema
- Identificar datos
- Selecciona el algoritmo
- Entrenar a la modelo
- Prueba el modelo
El aprendizaje ocurre en dos fases
- Aplique una transformación no lineal de los datos de entrada y cree un modelo estadístico como salida.
- El modelo se mejora con un método derivado.
Estas dos fases de operaciones se conocen como iteración. Las redes neuronales repiten los dos pasos hasta que se genere la salida y la precisión deseadas.
1. Capacitación de redes: para capacitar una red de datos, recopilamos una gran cantidad de datos y diseñamos un modelo que aprenderá las características. Pero el proceso es más lento en el caso de una gran cantidad de datos.
2. Transferir el aprendizaje: Transferir el aprendizaje básicamente modifica un modelo pre-entrenado y luego se realiza una nueva tarea. En este proceso, el tiempo de cálculo se vuelve menor.
3. Extracción de características: después de que todas las capas reciben capacitación sobre las características del objeto, las características se extraen de él y la salida se predice con precisión.
Conclusión
Deep Learning es un subconjunto de ML y ML es un subconjunto de IA. Las tres tecnologías y modelos tienen un gran impacto en la vida real. Las entidades comerciales, gigantes comerciales están implementando modelos de aprendizaje profundo para obtener resultados superiores y comparables para la automatización que está inspirada en el cerebro humano.
Artículos recomendados
Esta es una guía de la técnica de aprendizaje profundo. Aquí discutimos cómo crear modelos de aprendizaje profundo junto con las dos fases de operación. También puede consultar los siguientes artículos para obtener más información:
- ¿Qué es el aprendizaje profundo?
- Carreras en Aprendizaje Profundo
- 13 preguntas y respuestas útiles para la entrevista de aprendizaje profundo
- Aprendizaje automático de hiperparámetros