
Introducción a Hive Group By
Agrupar por, como su nombre indica, agrupará el registro que satisfaga ciertos criterios. En este artículo, veremos al grupo por HIVE. En RDBMS heredados como MySQL, SQL, etc., group by es una de las cláusulas más antiguas que se están utilizando. Ahora ha encontrado su lugar de manera similar en el almacenamiento de datos basado en archivos conocido como HIVE.
Sabemos que Hive ha superado muchos RDBMS heredados en el manejo de grandes datos sin gastar un centavo en proveedores para mantener las bases de datos y los servidores. Solo necesitamos configurar HDFS para manejar la colmena. En general, pasamos a las tablas porque el usuario final puede interpretar desde su estructura y puede consultar porque los archivos serán torpes para ellos. Pero teníamos que hacer esto pagando a los proveedores para proporcionar servidores y mantener nuestros datos en el formato de tablas. Por lo tanto, Hive proporciona el mecanismo rentable donde aprovecha las ventajas de los sistemas basados en archivos (la forma en que la colmena guarda sus datos), así como las tablas (estructura de tablas para que los usuarios finales consulten).
Agrupar por
Agrupar por utiliza las columnas definidas de la tabla Hive para agrupar los datos. Como, considere que tiene una tabla con los datos del censo de cada ciudad de todos los estados donde el nombre de la ciudad y el nombre del estado es una de las columnas. Ahora en la consulta, si agrupamos por estados, todos los datos de diferentes ciudades de un estado particular se agruparán y uno puede visualizar fácilmente los datos mejor ahora antes de la forma en que se aplicó el grupo.
Sintaxis de Hive Group By
La sintaxis general del grupo por cláusula es la siguiente:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
o para consultas más simples,
from Group By
Select department, count(*) from the university.college Group By department;
Aquí el departamento se refiere a una de las columnas de la tabla de la universidad que está presente en la base de datos de la universidad y su valor es diferente en departamentos como artes, matemáticas, ingeniería, etc. Ahora veamos algunos ejemplos para demostrar el grupo.
He creado una tabla de muestra deck_of_cards para demostrar el grupo. Su declaración de crear tabla es la siguiente:
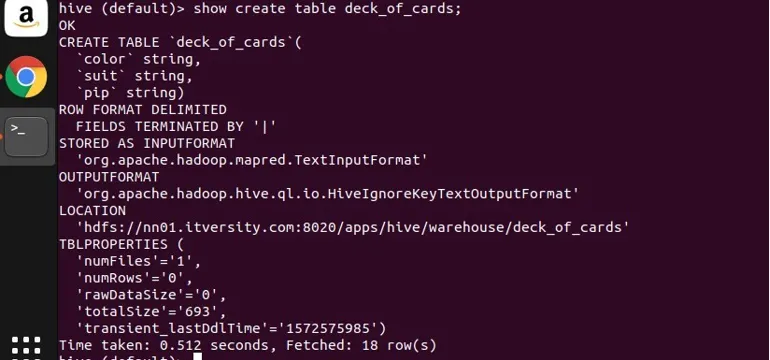
Puede ver desde arriba que tiene tres columnas de color, cadena y color. Permítanme escribir una consulta para agrupar los datos por su color y obtener su recuento.
select color, count(*) from deck_of_cards group by color;
Hive básicamente toma la consulta anterior para convertirla al programa map-reduce generando el código java correspondiente y el archivo jar y luego se ejecuta. Este proceso puede llevar un poco de tiempo, pero definitivamente puede manejar los grandes datos en comparación con el RDBMS tradicional. Vea la captura de pantalla a continuación con el registro detallado para ejecutar la consulta anterior.
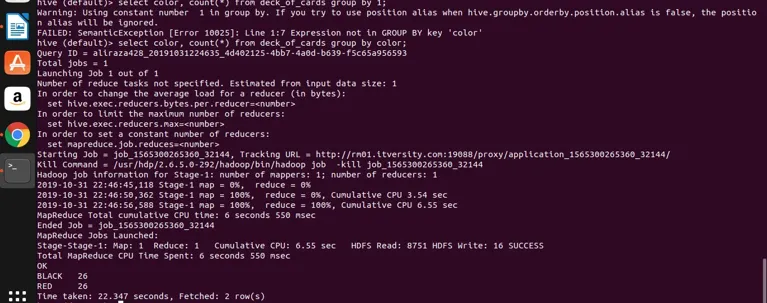
puedes ver que NEGRO es 26 y ROJO es 26.
ahora apliquemos la agrupación en dos columnas (color y traje y obteniendo el recuento de grupos) y veamos el resultado a continuación.
Select color, suit, count(*) from deck_of_cards group by color, suit
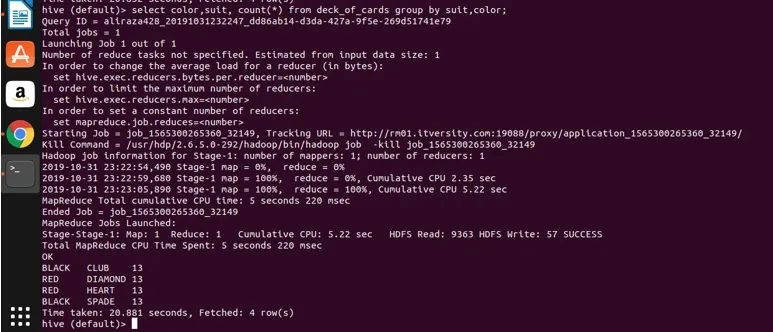
Básicamente, hay cuatro grupos distintos sobre Club, Spade que tienen color negro y Diamond y corazón que son de color rojo.
Almacenar el resultado del grupo por causa en otra tabla
Hive también, como cualquier otro RDBMS, proporciona la característica de insertar los datos con instrucciones de creación de tablas. Veamos cómo almacenar el resultado de una expresión select usando un grupo por en otra tabla. Permítanme usar la consulta anterior en la que he usado dos columnas en grupo por.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
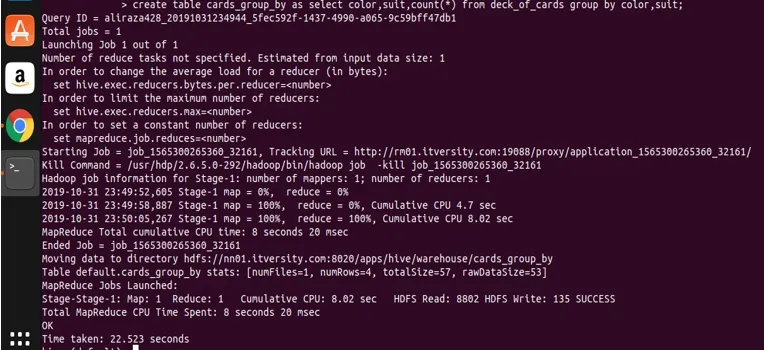
ahora vamos a consultar la tabla creada para ver y validar los datos.

Ahora restrinjamos el resultado del grupo usando la cláusula have. Como se muestra en la sintaxis genérica, podemos aplicar restricciones en el grupo mediante el uso de have. Aquí estoy usando la tabla ordser_items y su estructura es la siguiente de la declaración describe.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
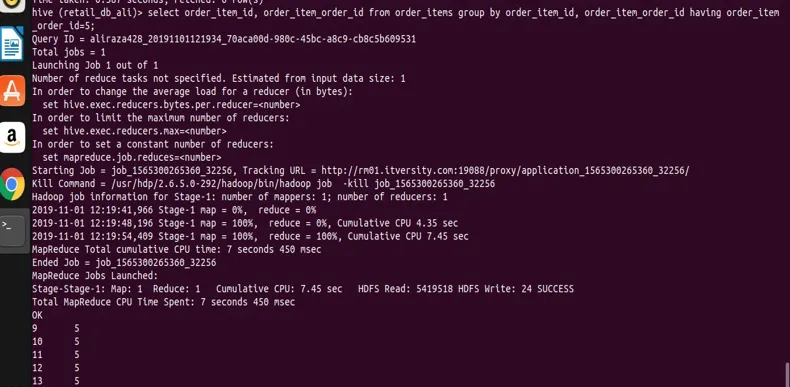
Puede ver en el resultado la captura de pantalla de que tenemos registros solo con el valor order_item_order_id 5.
Agrupar por junto con la declaración del caso
Ahora veamos consultas poco complejas que involucran las declaraciones CASE con el grupo by. Aplicaremos esto a la tabla order_items. A continuación veremos que podemos categorizar las columnas que no se encuentran en regiones en las que no podemos aplicar el grupo por cláusula directamente.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
vamos a ejecutarlo en la colmena para obtener resultados
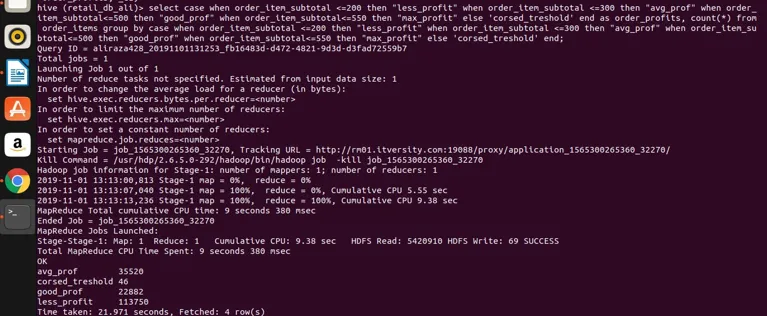
Conclusión - Hive Group By
así que podemos ver que hemos agrupado el order_item_subtotal en cuatro categorías diferentes (si observa que order_item_subtotal es una columna no agregada y no se puede aplicar el grupo directo por él) y los hemos agrupado y hemos obtenido sus recuentos también para los valores que satisfacen el rango tal como se define en la expresión de selección. Aquí, la regla simple si la columna no se registra y nuestra expresión select es compleja, lo que sea que haya en la expresión select que también debería estar presente en el grupo por expresión de cláusula. Así que hemos visto cómo un grupo de cláusulas RDBMS de cláusula famosa también se puede aplicar en la sección sin restricciones. Se puede aplicar a expresiones de selección simples. Expresiones agregadas y de filtrado, expresiones de unión y expresiones CASE complejas también.
Artículos recomendados
Esta es una guía para Hive Group By. Aquí discutimos el grupo por, sintaxis, ejemplos del grupo de colmenas con diferentes condiciones e implementación. También puede consultar los siguientes artículos para obtener más información:
- Se une en colmena
- ¿Qué es una colmena?
- Arquitectura de la colmena
- Función de la colmena
- Orden de la colmena por
- Instalación de colmena
- Los 6 tipos principales de combinaciones en MySQL con ejemplos