
Descripción general de los algoritmos de red neuronal
- Primero, ¿qué significa una red neuronal? Las redes neuronales están inspiradas en las redes neuronales biológicas en el cerebro o podemos decir el sistema nervioso. Ha generado mucha emoción y todavía se está investigando este subconjunto de Machine Learning en la industria.
- La unidad computacional básica de una red neuronal es una neurona o nodo. Recibe valores de otras neuronas y calcula la salida. Cada nodo / neurona está asociado con el peso (w). Este peso se da según la importancia relativa de esa neurona o nodo particular.
- Entonces, si tomamos f como la función de nodo, entonces la función de nodo f proporcionará la salida como se muestra a continuación:
Salida de neurona (Y) = f (w1.X1 + w2.X2 + b)
- Donde w1 y w2 son peso, X1 y X2 son entradas numéricas, mientras que b es el sesgo.
- La función anterior f es una función no lineal también llamada función de activación. Su propósito básico es introducir la no linealidad ya que casi todos los datos del mundo real no son lineales y queremos que las neuronas aprendan estas representaciones.
Diferentes algoritmos de red neuronal
Veamos ahora cuatro algoritmos de red neuronal diferentes.
1. Pendiente de gradiente
Es uno de los algoritmos de optimización más populares en el campo del aprendizaje automático. Se usa mientras se entrena un modelo de aprendizaje automático. En palabras simples, se usa básicamente para encontrar valores de los coeficientes que simplemente reducen la función de costo tanto como sea posible. En primer lugar, comenzamos definiendo algunos valores de parámetros y luego, usando el cálculo, comenzamos a ajustar iterativamente los valores para que La función perdida se reduce.
Ahora, pasemos a la parte ¿qué es el gradiente? Entonces, un gradiente significa que la salida de cualquier función cambiará mucho si disminuimos la entrada un poco o, en otras palabras, podemos llamarla a la pendiente. Si la pendiente es empinada, el modelo aprenderá más rápido de manera similar, un modelo deja de aprender cuando la pendiente es cero. Esto se debe a que es un algoritmo de minimización que minimiza un algoritmo dado.
Debajo de la fórmula para encontrar la siguiente posición se muestra en el caso de descenso de gradiente.
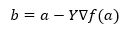
Donde b es la siguiente posición
a es la posición actual, gamma es una función de espera.
Entonces, como puede ver, el descenso de gradiente es una técnica muy sólida, pero hay muchas áreas donde el descenso de gradiente no funciona correctamente. A continuación se proporcionan algunos de ellos:
- Si el algoritmo no se ejecuta correctamente, podemos encontrar algo como el problema de la desaparición del gradiente. Esto ocurre cuando el gradiente es demasiado pequeño o demasiado grande.
- Los problemas surgen cuando la disposición de los datos plantea un problema de optimización no convexo. El degradado decente funciona solo con problemas que son el problema convexo optimizado.
- Uno de los factores muy importantes a tener en cuenta al aplicar este algoritmo son los recursos. Si tenemos menos memoria asignada para la aplicación, debemos evitar el algoritmo de descenso de gradiente.
2. Método de Newton
Es un algoritmo de optimización de segundo orden. Se llama un segundo orden porque hace uso de la matriz de Hesse. Entonces, la matriz de Hesse no es más que una matriz cuadrada de derivadas parciales de segundo orden de una función de valor escalar. En el algoritmo de optimización del método de Newton, se aplica a la primera derivada de una función doble diferenciable f para que pueda encontrar las raíces / puntos estacionarios. Pasemos ahora a los pasos requeridos por el método de Newton para la optimización.
Primero evalúa el índice de pérdida. Luego verifica si el criterio de detención es verdadero o falso. Si es falso, calcula la dirección de entrenamiento de Newton y la velocidad de entrenamiento y luego mejora los parámetros o los pesos de la neurona y nuevamente el mismo ciclo continúa. Entonces, ahora puede decir que se necesitan menos pasos en comparación con el descenso del gradiente para obtener el mínimo valor de la función. Aunque toma menos pasos en comparación con el algoritmo de descenso de gradiente, todavía no se usa ampliamente ya que el cálculo exacto de hessian y su inverso son computacionalmente muy caros.
3. Gradiente conjugado
Es un método que puede considerarse como algo entre el descenso de gradiente y el método de Newton. La principal diferencia es que acelera la convergencia lenta que generalmente asociamos con el descenso del gradiente. Otro hecho importante es que se puede usar tanto para sistemas lineales como no lineales y es un algoritmo iterativo.
Fue desarrollado por Magnus Hestenes y Eduard Stiefel. Como ya se mencionó anteriormente, produce una convergencia más rápida que el descenso de gradiente. La razón por la que puede hacerlo es que en el algoritmo de gradiente conjugado, la búsqueda se realiza junto con las direcciones conjugadas, por lo que converge más rápido que los algoritmos de descenso de gradiente. Un punto importante a tener en cuenta es que γ se llama parámetro conjugado.
La dirección de entrenamiento se restablece periódicamente al negativo del gradiente. Este método es más efectivo que el descenso por gradiente en el entrenamiento de la red neuronal, ya que no requiere la matriz de Hesse que aumenta la carga computacional y también converge más rápido que el descenso por gradiente. Es apropiado usar en grandes redes neuronales.
4. Método cuasi-Newton
Es un enfoque alternativo al método de Newton, como sabemos ahora que el método de Newton es computacionalmente costoso. Este método resuelve esos inconvenientes hasta el punto de que, en lugar de calcular la matriz de Hesse y luego calcular el inverso directamente, este método genera una aproximación al inverso de Hesse en cada iteración de este algoritmo.
Ahora, esta aproximación se calcula utilizando la información de la primera derivada de la función de pérdida. Entonces, podemos decir que probablemente sea el método más adecuado para manejar redes grandes, ya que ahorra tiempo de cálculo y también es mucho más rápido que el método de descenso de gradiente o gradiente conjugado.
Conclusión
Antes de finalizar este artículo, comparemos la velocidad computacional y la memoria de los algoritmos mencionados anteriormente. Según los requisitos de memoria, el descenso de gradiente requiere menos memoria y también es el más lento. Al contrario de eso, el método de Newton requiere más potencia computacional. Entonces, teniendo en cuenta todo esto, el método Cuasi-Newton es el más adecuado.
Artículos recomendados
Esta ha sido una guía de algoritmos de redes neuronales. Aquí también discutimos la visión general del algoritmo de red neuronal junto con cuatro algoritmos diferentes, respectivamente. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Aprendizaje automático vs red neuronal
- Marcos de aprendizaje automático
- Redes neuronales vs aprendizaje profundo
- K- Algoritmo de agrupamiento de medios
- Guía para la clasificación de redes neuronales