
Descripción general del modelado de regresión lineal
Cuando comienzas a aprender sobre Algoritmos de aprendizaje automático, comienzas a aprender sobre varias formas de algoritmos de aprendizaje automático, es decir, aprendizaje supervisado, no supervisado, semi-supervisado y de refuerzo. En este artículo, trataremos el aprendizaje supervisado y uno de los algoritmos básicos pero potentes: la regresión lineal.

Por lo tanto, el aprendizaje supervisado es el aprendizaje en el que entrenamos a la máquina para comprender la relación entre los valores de entrada y salida proporcionados en el conjunto de datos de entrenamiento y luego utilizamos el mismo modelo para predecir los valores de salida para el conjunto de datos de prueba. Entonces, básicamente, si ya tenemos la salida o el etiquetado provistos en nuestro conjunto de datos de capacitación y estamos seguros de que la salida proporcionada tiene sentido correspondiente a la entrada, entonces usamos el Aprendizaje supervisado. Los algoritmos de aprendizaje supervisados se clasifican en Regresión y Clasificación.
Los algoritmos de regresión se usan cuando observa que la salida es una variable continua, mientras que los algoritmos de clasificación se usan cuando la salida se divide en secciones como Pasa / Falla, Bueno / Promedio / Malo, etc. Tenemos varios algoritmos para realizar la regresión o clasificación acciones con Algoritmo de regresión lineal como algoritmo básico en Regresión.
Al llegar a esta Regresión, antes de entrar en el algoritmo, déjame establecer la base para ti. En la escuela, espero que recuerdes el concepto de ecuación de línea. Déjame darte un resumen al respecto. Se le dieron dos puntos en el plano XY, es decir, digamos (x1, y1) y (x2, y2), donde y1 es la salida de x1 y y2 es la salida de x2, entonces la ecuación de línea que pasa por los puntos es (y- y1) = m (x-x1) donde m es la pendiente de la recta. Ahora, después de encontrar la ecuación de línea, si se le da un punto, digamos (x3, y3), entonces podrá predecir fácilmente si el punto se encuentra en la línea o la distancia del punto desde la línea. Esta fue la regresión básica que había hecho en la escuela sin siquiera darme cuenta de que esto tendría tanta importancia en el aprendizaje automático. Lo que generalmente hacemos en esto es tratar de identificar la línea o curva de la ecuación que pueda ajustarse correctamente a la entrada y salida del conjunto de datos del tren y luego usar la misma ecuación para predecir el valor de salida del conjunto de datos de prueba. Esto daría como resultado un valor continuo deseado.
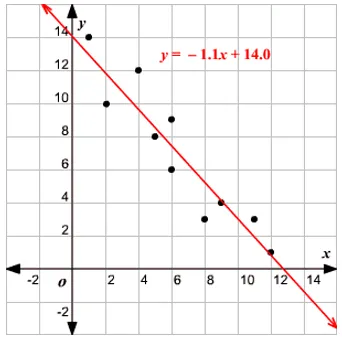
Definición de regresión lineal
La regresión lineal ha existido durante mucho tiempo (alrededor de 200 años). Es un modelo lineal, es decir, supone una relación lineal entre las variables de entrada (x) y una sola variable de salida (y). La y aquí se calcula mediante la combinación lineal de las variables de entrada.
Tenemos dos tipos de regresión lineal
Regresión lineal simple
Cuando hay una sola variable de entrada, es decir, la ecuación de línea es c
considerado como y = mx + c, entonces es Regresión lineal simple.
Regresión lineal múltiple
Cuando hay múltiples variables de entrada, es decir, la ecuación de línea se considera como y = ax 1 + bx 2 +… nx n, entonces es Regresión lineal múltiple. Se utilizan varias técnicas para preparar o entrenar la ecuación de regresión a partir de los datos y la más común entre ellas se llama Mínimos cuadrados ordinarios. El modelo construido utilizando el método mencionado se denomina Regresión lineal de mínimos cuadrados ordinarios o Regresión de mínimos cuadrados ordinarios. El modelo se usa cuando los valores de entrada y el valor de salida a determinar son valores numéricos. Cuando solo hay una entrada y una salida, la ecuación formada es una ecuación lineal, es decir
y = B0x+B1
donde los coeficientes de la línea se determinarán utilizando métodos estadísticos.
Los modelos de regresión lineal simple son muy raros en ML porque, en general, tendremos varios factores de entrada para determinar el resultado. Cuando hay múltiples valores de entrada y un valor de salida, la ecuación formada es la de un plano o hiperplano.
y = ax 1 +bx 2 +…nx n
La idea central en el modelo de regresión es obtener una ecuación lineal que mejor se ajuste a los datos. La línea de mejor ajuste es aquella en la que el error de predicción total para todos los puntos de datos se considera lo más pequeño posible. El error es la distancia entre el punto en el plano y la línea de regresión.
Ejemplo
Comencemos con un ejemplo de regresión lineal simple.

La relación entre la altura y el peso de una persona es directamente proporcional. Se realizó un estudio en los voluntarios para determinar la altura y el peso ideal de la persona y se registraron los valores. Esto se considerará como nuestro conjunto de datos de entrenamiento. Usando los datos de entrenamiento, se calcula una ecuación de línea de regresión que dará un error mínimo. Esta ecuación lineal se usa para hacer predicciones sobre nuevos datos. Es decir, si damos la altura de la persona, el modelo desarrollado por nosotros debería predecir el peso correspondiente con un error mínimo o cero.
Y(pred) = b0 + b1*x
Los valores b0 y b1 deben elegirse para minimizar el error. Si la suma del error al cuadrado se toma como una métrica para evaluar el modelo, entonces el objetivo es obtener la línea que mejor reduzca el error.
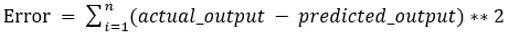
Estamos cuadrando el error para que los valores positivos y negativos no se cancelen entre sí. Para el modelo con un predictor:
El cálculo de la intersección (b0) en la ecuación lineal se realiza mediante:
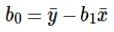
El cálculo del coeficiente para el valor de entrada x se realiza mediante:
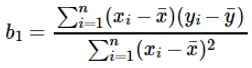
Comprensión del coeficiente b 1 :
- Si b 1 > 0, entonces x (entrada) e y (salida) son directamente proporcionales. Eso es un aumento en x aumentará y, como aumentos de altura, aumentos de peso.
- Si b 1 <0, entonces x (predictor) ey (objetivo) son inversamente proporcionales. Es decir, un aumento en x disminuirá y tal como la velocidad de un vehículo aumenta, el tiempo se toma disminuye.
Comprensión del coeficiente b 0 :
- B 0 toma el valor residual para el modelo y asegura que la predicción no esté sesgada. Si no tenemos el término B 0, entonces la ecuación de línea (y = B 1 x) se ve obligada a pasar por el origen, es decir, los valores de entrada y salida puestos en el modelo dan como resultado 0. Pero este nunca será el caso, si tenemos 0 en la entrada, entonces B 0 será el promedio de todos los valores pronosticados cuando x = 0. Establecer todos los valores predictores en 0 en el caso de x = 0 dará como resultado la pérdida de datos y, a menudo, es imposible.
Además de los coeficientes mencionados anteriormente, este modelo también se puede calcular utilizando ecuaciones normales. Discutiré más a fondo el uso de ecuaciones normales y el diseño de un modelo de regresión simple / multilineal en mi próximo artículo.
Artículos recomendados
Esta es una guía para el modelado de regresión lineal. Aquí discutimos la definición, los tipos de regresión lineal que incluye la regresión lineal simple y múltiple junto con algunos ejemplos. También puede consultar los siguientes artículos para obtener más información:
- Regresión lineal en R
- Regresión lineal en Excel
- Modelado predictivo
- ¿Cómo crear GLM en R?
- Comparación de regresión lineal versus regresión logística