

Introducción a la instalación de la colmena
En la instalación de Hive, se deben cumplir algunos requisitos previos antes de la instalación.
Los componentes de Hadoop como Hive, Hbase, Pig, etc., son compatibles con el entorno Linux. Por lo tanto, se recomienda tener un sistema operativo Linux en su dispositivo. Si no es el caso y desea practicar en la colmena mientras tiene ventanas en su sistema. Lo que puede hacer es instalar la máquina CDH en su sistema y usarla como plataforma para explorar Hadoop. Esto requerirá un mínimo de 4 GB de RAM en su sistema o puede tener una máquina CDH en su pen drive y usarla.
De todos modos, siempre puede tener una solución a su pregunta que tal vez más temprano que tarde.
Requisitos previos para instalar Hive
Hay algunos requisitos previos para instalar la colmena en cualquier máquina:
- Instalación de Java
- Instalación de Hadoop
Paso 1
- Verifique que Java esté instalado.
- Abra la Terminal y escriba el comando.
Versión Java
- Si Java está instalado en el sistema, le dará la versión o un error. En mi caso, Java ya está instalado y a continuación se muestra el resultado del comando.

- En caso de que Java no esté instalado en su sistema. Puede visitar el siguiente enlace y descargar Java e instalarlo.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Instalación de Java
- Extraer el descargado.
- Moverlo a "/ usr / local /".
- Configure las variables PATH y JAVA_HOME.
Paso 2
- Verifique que Hadoop esté instalado.
- Abra la Terminal y escriba el comando.
Versión Hadoop
- Si Hadoop ya está instalado, este comando le dará la versión o un error.
- En mi caso, Hadoop ya ha instalado, por lo tanto, la salida a continuación.
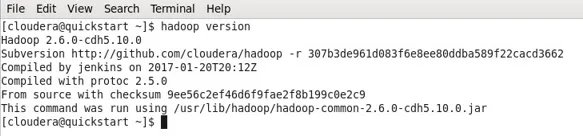
- Ahora puede observar que estoy trabajando con una máquina CDH5.
- Si Hadoop no está instalado, descargue el Hadoop desde la base del software Apache.
Instalación de Hadoop
1. Configurar Hadoop
2. Configurar Hadoop
Los archivos que se deben editar para configurar Hadoop son:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
3. Configure Namenode usando el comando:
Hdfs namenode -format
4. Inicie dfs con el siguiente comando:
start -dfs.sh
5. Inicie hilo utilizando el comando:
Start -yarn.sh
¿Cómo instalar Hive?
Debajo de los puntos ayuda a instalar la colmena:
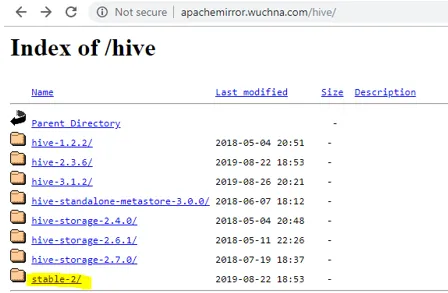
- Lo primero que debemos hacer es descargar la versión de la colmena que se puede hacer haciendo clic en el siguiente enlace: http://apachemirror.wuchna.com/hive/
- El enlace de arriba le dará el enlace del que debe elegir estable-2 resaltado a continuación en amarillo:
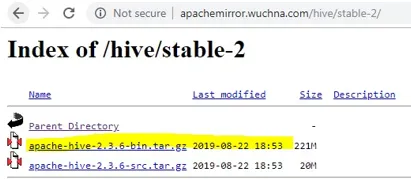
- Después de abrir stable-2, elija el archivo bin (resaltado en amarillo en la captura de pantalla) y haga clic derecho y “copiar dirección del enlace”.
Pasos para instalar Hive
A continuación se detallan los pasos para instalar la colmena:
Paso 1: descargue el archivo tar.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Paso 2: extrae el archivo.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Paso 3: Mueva los archivos apache al directorio / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Paso 4: configure el entorno de Hive agregando las siguientes líneas al archivo ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Paso 5: Ejecute el archivo bashrc.
$ source ~/.bashrc
Paso 6: Configuración de Hive : edite el archivo hive-env.sh para agregar esto:
export HADOOP_HOME=/usr/local/Hadoop
Paso 7: Edite usando los siguientes comandos:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Ahora para verificar que la colmena está instalada o no, use el comando hive-version.
- Aquí, la versión de la colmena ingresa al shell de la colmena, lo que significa que la colmena está instalada. Sin embargo, en mi caso es la versión anterior, por lo tanto, la advertencia.

Conclusión: instalación de la colmena
Hive abre el big data a muchas personas debido a su facilidad y naturaleza similar al SQL, como el lenguaje de consulta y las interfaces. Hive se basa en el núcleo de Hadoop, ya que utiliza Mapreduce para la ejecución. Mucho más fácil recuperar los datos y hacer el procesamiento de Big Data.
Artículos recomendados
Esta es una guía para la instalación de la colmena. Aquí discutimos algunos requisitos previos para instalar Hive en cualquier máquina y cómo instalar Hive en pasos para una mejor comprensión. También puede consultar nuestros otros artículos relacionados para obtener más información.
- ¿Qué es una colmena?
- Comandos de la colmena
- Cómo instalar Hive
- ¿Qué es el cerdo?