

Diferencia entre Apache Hive y Apache HBase -
La historia de Apache Hive comienza en el año 2007 cuando un programador que no tiene Java tiene que luchar mientras usa Hadoop MapReduce. Investigadores y desarrolladores predijeron que mañana es una era de Big Data. Ya se estaban acumulando diferentes formatos de datos como estructurado, semiestructurado y no estructurado. Incluso Facebook estaba luchando con la mayor cantidad de procesamiento de datos. Investigadores de Facebook presentaron Apache Hive para el procesamiento de datos en Hadoop Cluster. Facebook fue la primera compañía en crear Apache Hive.
La historia de Apache HBase comienza en 2006 cuando la startup Powerset, con sede en San Francisco, intentaba construir un motor de búsqueda en lenguaje natural para la web. HBase es una implementación de Bigtable de Google. ¿Alguna vez nos dimos cuenta de por qué era necesario crear otra arquitectura de almacenamiento? El sistema de gestión de bases de datos relacionales existe desde principios de los años setenta. Hay muchos casos de uso para los cuales las bases de datos relacionales tienen mucho sentido, pero para algunos problemas específicos, el modelo relacional no se ajusta muy bien.
Permítanme explicar acerca de Apache Hive y Apache HBase en más detalles.
Diferencias entre Apache Hive y Apache HBase
Apache Hive es un proyecto de código abierto de Apache construido sobre Hadoop para consultar, resumir y analizar grandes conjuntos de datos utilizando una interfaz similar a SQL. Apache Hive proporciona un lenguaje similar a SQL llamado HiveQL, que convierte de forma transparente las consultas a MapReduce para su ejecución en grandes conjuntos de datos almacenados en el Sistema de archivos distribuidos de Hadoop (HDFS). Apache Hive es un componente de clúster de Hadoop que normalmente implementan los analistas de datos. Apache Hive se utiliza para el procesamiento por lotes de grandes trabajos ETL. Apache Hive también admite consultas SQL por lotes en conjuntos de datos muy grandes. Apache Hive aumenta la flexibilidad de diseño del esquema y también la serialización y deserialización de datos. Apache Hive no admite el procesamiento de transacciones en línea (OLTP) porque la sección no admite consultas en tiempo real y actualizaciones a nivel de fila.
Apache HBase es una base de datos NoSQL de código abierto que proporciona acceso en tiempo real, lectura y escritura a grandes conjuntos de datos. NoSQL es una base de datos no relacional. Apache HBase es una base de datos distribuida orientada a columnas que se ejecuta sobre el Sistema de archivos distribuidos de Hadoop (HDFS). Entonces, HBase trae los beneficios de NoSQL a Hadoop. Apache HBase proporciona capacidades de acceso aleatorio de datos presentes en HDFS. Aprovecha la tolerancia a fallas proporcionada por el HDFS. El usuario puede almacenar los datos en HDFS directamente o a través de HBase.
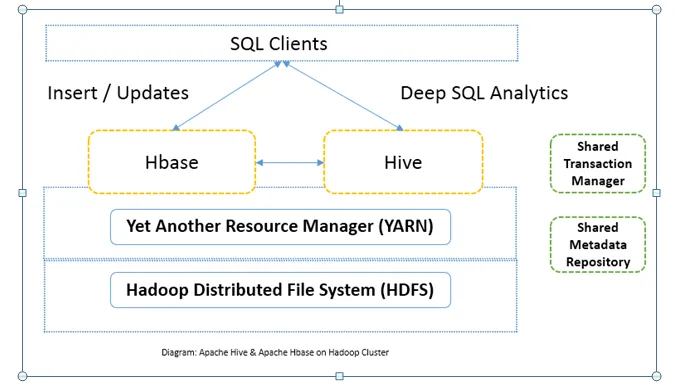
Comparación cabeza a cabeza entre Apache Hive y Apache HBase (Infografía)
A continuación se muestran las 12 principales diferencias entre Apache Hive y Apache HBase

Diferencias clave: Apache Hive vs Apache HBase
A continuación se encuentran las listas de puntos, describa las diferencias clave entre Apache Hive y Apache HBase:
- Apache HBase es una base de datos, mientras que Apache Hive es un motor de base de datos.
- Apache Hive se utiliza principalmente para el procesamiento por lotes (OLAP), mientras que Apache HBase se utiliza principalmente para el procesamiento transaccional (OLTP).
- Apache Hive ejecuta la mayoría de las consultas SQL, mientras que Apache HBase no permite consultas SQL directamente.
- Apache Hive no admite operaciones de nivel de registro como actualización, inserción y eliminación, mientras que Apache HBase admite operaciones de nivel de registro como actualización, inserción y eliminación.
- Apache Hive se ejecuta sobre MapReduce mientras que Apache HBase se ejecuta sobre Hadoop Distributed File System (HDFS).
Apache Hive consulta los archivos definiendo una tabla virtual y ejecutando consultas HQL encima. Es un proceso en el que los archivos están prácticamente conectados a una tabla como estructura y el usuario puede ejecutar Hive Query Language (HQL) y Hive convierte estas consultas en MapReduce Job. El usuario no tiene que escribir el trabajo MapReduce, las consultas HQL se convierten internamente en archivos jar y estos archivos jar se implementarán en conjuntos de datos.
Mientras está en Apache HBase, las tablas se dividen en regiones y son atendidas por los servidores de la región. Otras regiones se dividen verticalmente por familias de columnas en tiendas y las Tiendas se guardan como archivos en HDFS.
Cuándo usar Apache Hive:
- Requisitos de almacenamiento de datos
- Consultas analíticas
- Análisis de datos que están familiarizados con SQL
Cuándo usar Apache HBase:
- Procesamiento de datos rápido e interactivo.
- Consultas en tiempo real
- Búsquedas rápidas
- Procesamiento del lado del servidor
- Acceso aleatorio de lectura / escritura a Big Data
- Escalabilidad de la aplicación
Apache Hive se puede utilizar para calcular tendencias y registros del sitio web de comercio electrónico para una duración, región o zona horaria particular. Se puede usar para procesar consultas por lotes sobre datos históricos, mientras que Apache HBase puede ser usado por Facebook o LinkedIn para mensajes y análisis en tiempo real. También se puede usar para contar me gusta.
Tabla comparativa Apache Hive vs Apache HBase
Estoy discutiendo los principales artefactos y distinguiendo entre Apache Hive y Apache HBase.
| Colmena Apache | Apache HBase | |
| Procesamiento de datos | Apache Hive se utiliza para
procesamiento por lotes, es decir, procesamiento analítico en línea (OLAP) | Apache HBase se utiliza para el procesamiento transaccional, es decir, el procesamiento transaccional en línea (OLTP) |
| Velocidad de procesamiento | Apache Hive tiene una latencia más alta debido a la ejecución del trabajo MapReduce en segundo plano | Apache HBase funciona en consultas en tiempo real y mucho más rápido que Apache Hive |
| Compatibilidad con Hadoop | Apache Hive se ejecuta sobre MapReduce | Apache HBase se ejecuta sobre HDFS |
| Definición | Apache Hive es de código abierto y similar a SQL utilizado para consultas analíticas | Apache HBase es una base de datos NoSQL de código abierto utilizada para consultas en tiempo real |
| Metadatos compartidos | Los datos creados en Apache Hive son visibles automáticamente para Apache HBase | Los datos creados en Apache HBase son visibles automáticamente para Apache Hive |
| Esquema | La colmena Apache admite el esquema para insertar datos en tablas | Apache HBase es una base de datos libre de esquemas. |
| Característica de actualización | La función de actualización es complicada en Apache Hive | El usuario puede actualizar fácilmente los datos en Apache HBase |
| Operaciones | Las operaciones en Apache Hive no se ejecutan en tiempo real | Las operaciones en Apache HBase se ejecutan en tiempo real |
| Tipos de datos | Apache Hive está diseñado para datos estructurados y semiestructurados | Apache HBase es para datos no estructurados. |
| Nivel de consistencia | La colmena Apache admite la coherencia eventual | Apache HBase admite la consistencia inmediata |
| Métodos de partición | Apache Hive admite funciones de Sharding | Apache HBase también admite funciones de Sharding |
| Almacenamiento de datos | La fecha se almacena en el Metastore, particiones y cubos de Hive en Apache Hive | Los datos se almacenan en columnas y filas de tablas en Apache HBase |
Conclusión: Apache Hive vs Apache HBase
Comúnmente, Apache Hive vs Apache HBase se usa en conjunto en el mismo clúster. Ambos se pueden usar juntos para mejorar la potencia de procesamiento. Dado que la colmena mejora los aspectos analíticos de HDFS, mientras que HBase mejora las transacciones en tiempo real. El usuario puede usar Hive como una herramienta ETL para inserciones por lotes con los datos en HBase y luego ejecutar consultas que puedan unir aún más los datos presentes en las tablas de HBase con los datos que ya están presentes en HDFS. Los datos se pueden leer y escribir desde Apache Hive a HBase y viceversa. La interfaz entre Apache Hive y Apache HBase aún está en fase de maduración. Hay mucho más por venir. Aún así, puedo decir que tanto Apache Hive como Apache HBase hacen que el clúster Hadoop sea más robusto y potente.
Artículos relacionados:
Esta ha sido una guía de Apache Hive vs Apache HBase, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- Las 5 principales tendencias de Big Data
- 5 desafíos de Big Data Analytics
- ¿Cómo descifrar la entrevista para desarrolladores de Hadoop?
- 5 desafíos de Big Data Analytics