

¿Qué es kafka?
Para comprender a Kafka, es mejor comprender qué es la tecnología de 'procesamiento de flujo'. 'El procesamiento de flujo es una tecnología que utiliza un usuario para consultar un flujo continuo de datos en un marco de tiempo micro para comprender mejor las condiciones subyacentes responsables.
Un escenario en tiempo real: imagine si su sensor de temperatura envía datos que puede consultar y recibir una alerta después de recibir un punto de congelación. Esta consulta de datos se puede hacer en microsegundos.
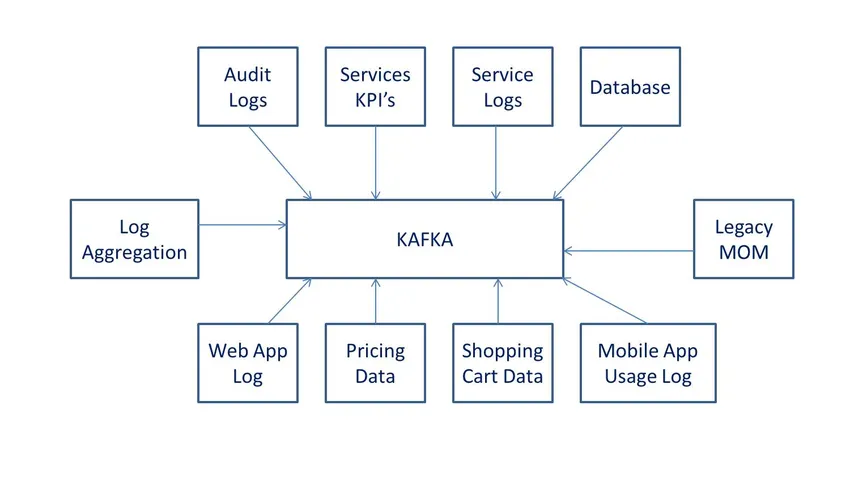
Definiciones
Según Wiki, es un software de procesamiento de datos de código abierto. Fue desarrollado por LinkedIn y luego donado al software Apache.
Entendiendo Kafka
Su crecimiento está explotando exponencialmente. Veamos algunos hechos y estadísticas para subrayar mejor nuestro pensamiento. Disfruta de la preferencia principal de más de un tercio de las Fortune 500 en todo el mundo. Esta distribución es compartida por empresas de viajes, gigantes de telecomunicaciones, bancos y muchos otros. LinkedIn, Microsoft y Netflix procesan mensajes de cuatro comas al día con Kafka (casi equivale a 1, 000, 000, 000, 000).
Se utiliza para flujos de datos en tiempo real, para recopilar grandes datos o para realizar análisis en tiempo real (o ambos). Kafka se usa con microservicios en memoria para proporcionar durabilidad y se puede usar para alimentar eventos a CEP (sistemas de transmisión de eventos complejos) y sistemas de automatización de estilo IoT / IFTTT.
¿Cómo funciona Kafka tan fácil?
Impulsado por la simplicidad sería la forma correcta de definir el rendimiento. Es fácil descubrir cómo funciona Kafka con tanta facilidad desde su configuración y uso. Este mayor rendimiento en el comportamiento está dedicado a su estabilidad, su provisión a una durabilidad confiable, con su capacidad incorporada flexible para publicar o suscribirse o poner en cola el mantenimiento. Esto es muy importante si necesita lidiar con N - números de grupo de clientes, si tiene que mostrar una replicación sólida en el mercado, con el objetivo de proporcionar a sus clientes un enfoque consistente (es decir, partición de temas de Kafka). Un comportamiento crucial de Kafka que lo distingue de sus competidores es su compatibilidad con los sistemas con flujos de datos, su proceso y permite que estos sistemas agreguen, transformen y carguen otras tiendas para trabajar convenientemente. "Todos los hechos mencionados anteriormente no serían posibles si Kafka fuera lento". Su rendimiento excepcional lo hace posible.
Además de la facilidad de trabajo de Kafka, tenemos que pasar al "Nivel de SO". Veamos cómo funcionan las cosas para Kafka a nivel del sistema operativo:
- Se basa en los núcleos del sistema operativo para mover los datos más rápidamente y funciona según el principio de copia cero.
- Permite que los registros de datos se agrupen en fragmentos que se pueden ver desde el sistema de archivos (también conocido como registro de temas Kafka) hasta los consumidores.
- La facilidad para agrupar datos brinda una compresión eficiente de datos con reducción de latencia de E / S.
- Tiene la capacidad de escalar horizontalmente mediante fragmentación. Puede fragmentar un registro de título en cientos de particiones a miles. Esto le permite manejar la carga de trabajo masiva fácilmente.
¿Qué puedes hacer con Kafka?
Si su empresa juega con grandes conjuntos de datos de forma regular, necesita Kafka. Hay una larga lista de empresas que lo utilizan.
- LinkedIn utiliza para rastrear datos y métricas operativas.
- Twitter para proporcionar infraestructuras de procesamiento de flujo.
Hay una larga lista de compañías, desde Uber hasta Spotify y Goldman Sachs hasta Cisco.
Ventajas
- Alto rendimiento: puede manejar fácilmente un gran volumen de datos cuando generar a alta velocidad es una ventaja excepcional a favor de Kafka. Esta aplicación carece de hardware enorme. Con la capacidad de soportar el rendimiento del mensaje a una frecuencia de miles de mensajes por segundo.
- Baja latencia: Baja latencia manejando esta generación de mensajes de alto volumen.
- Tolerancia a fallas: esta característica es muy útil, tiene una capacidad inherente de ser restringida por un nodo integrado en un clúster.
- Durable: es muy duradero en su funcionamiento y es por eso que muchas multinacionales prefieren usar Kafka. Hablando de durabilidad en las operaciones, los mensajes no pueden perderse a largo plazo.
Habilidades requeridas
No hay requisitos especiales para ser un profesional de Kafka. Pero hemos subrayado algunas transmisiones y profesionales:
- Desarrolladores que de buena gana quieren hacer una carrera en el flujo de Big Data y quieren acelerar su carrera.
- Los profesionales de pruebas tienen un buen alcance en Kafka en términos de sistemas de colas y mensajería
- Arquitectos, ya que todo necesita un marco y este marco puede actualizarse de vez en cuando. Los arquitectos de Big Data encontrarían a Kafka como una buena inversión profesional.
- El Project Manager es necesario si el profesional anterior está allí para una mejor gestión de los recursos. Por lo tanto, los puestos más altos también están disponibles para los profesionales de gestión en el campo de Kafka.
¿Por qué usar Kafka?
Con el propósito de rastrear y manipular los datos según las necesidades del negocio, Kafka es el preferido en todo el mundo. Da la posibilidad de transmitir datos en tiempo real con análisis en tiempo real. Es rápido, escalable y duradero y está diseñado como tolerancia a fallas. Hay varios casos de uso presentes en la web donde puede ver por qué JMS, RabbitMQ y AMQP ni siquiera se considera que funcionan, ya que la necesidad es operar un gran volumen y capacidad de respuesta.
Tiene una configuración confiable y de alto rendimiento con características de replicación que lo convierten en una opción preferible para trabajar en sensores IoT.
La compatibilidad es otra razón para usarla y la hizo aceptable en todo el mundo. Se puede configurar fácilmente para trabajar con la aplicación que se detalla a continuación. Esta combinación es muy vital para muchas empresas para hacer crecer negocios y sobrevivir (ya que ahorra tiempo y dinero).
- Canal artificial
- Spark Streaming
- HBase
- Spark para la ingestión, procesamiento y análisis de datos en tiempo real.
- Se utiliza para alimentar Hadoop BigData
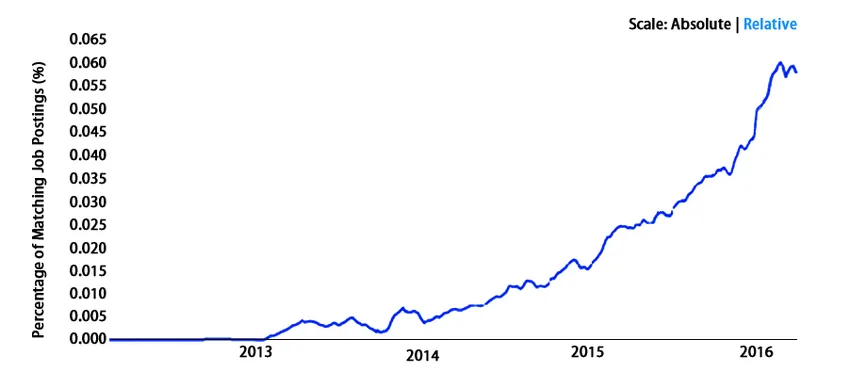
Alcance
Lo está haciendo genial en todo el mundo. Bueno, no estamos diciendo esto más bien estadísticas. Echemos un vistazo -
Estadísticas salariales para profesionales de Kafka - PayScale
- Ingeniero de Software - $ 109, 825
- Ingeniero de datos - $ 109, 580
- Desarrolladores - $ 81, 182
- Ingeniero de Datos Senior - $ 127, 836
Conclusión
En la actualidad, Kafka se ha convertido en el estándar de facto cuando se trata de análisis de datos en tiempo real con la más alta precisión en microsegundos. Hemos presentado nuestras ideas en términos de datos y detalles en apoyo de las tecnologías de Kafka. Hay varias grandes empresas que aprovechan los datos a diario, para ello necesitan profesionales que aprovechen estos enormes conjuntos de datos. Con Kafka, uno puede estar seguro de liderar su carrera en un análisis de BigData
Artículos recomendados
Esta ha sido una guía de ¿Qué es Kafka? Aquí discutimos el trabajo, el alcance, el crecimiento profesional y las ventajas de Kafka. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- ¿Qué es apache?
- ¿Qué es Big Data y Hadoop?
- ¿Qué es el azul?
- ¿Qué es la tecnología Big Data?
- Kafka vs Spark | Las 5 principales diferencias
- Descripción general y aplicaciones principales de Kafka
- Kafka vs Kinesis | 5 diferencias con la infografía