

Entrevista de aprendizaje profundo Preguntas y respuestas
Hoy en día, Deep Learning se considera una de las tecnologías de más rápido crecimiento con una enorme capacidad para desarrollar una aplicación que se consideró difícil hace algún tiempo. El reconocimiento de voz, el reconocimiento de imágenes, la búsqueda de patrones en un conjunto de datos, la clasificación de objetos en fotografías, la generación de texto de personajes, los automóviles autónomos y muchos más son solo algunos ejemplos en los que Deep Learning ha demostrado su importancia.
Así que finalmente ha encontrado el trabajo de sus sueños en Deep Learning, pero se pregunta cómo descifrar la Entrevista de Deep Learning y cuáles podrían ser las preguntas probables de la entrevista de Deep Learning. Cada entrevista es diferente y el alcance de un trabajo también es diferente. Teniendo esto en cuenta, hemos diseñado las preguntas y respuestas de la entrevista de aprendizaje profundo más comunes para ayudarlo a tener éxito en su entrevista.
A continuación se presentan algunas preguntas de la entrevista de aprendizaje profundo que se hacen con frecuencia en la entrevista y que también ayudarían a evaluar sus niveles:
Parte 1 - Preguntas de la entrevista de aprendizaje profundo (básico)
Esta primera parte cubre preguntas y respuestas básicas de la entrevista de aprendizaje profundo
1. ¿Qué es el aprendizaje profundo?
Responder:
El área de aprendizaje automático que se centra en redes neuronales artificiales profundas que están libremente inspiradas en el cerebro. Alexey Grigorevich Ivakhnenko publicó el primer general sobre el funcionamiento de la red Deep Learning. Hoy tiene su aplicación en varios campos, como la visión por computadora, el reconocimiento de voz y el procesamiento del lenguaje natural.
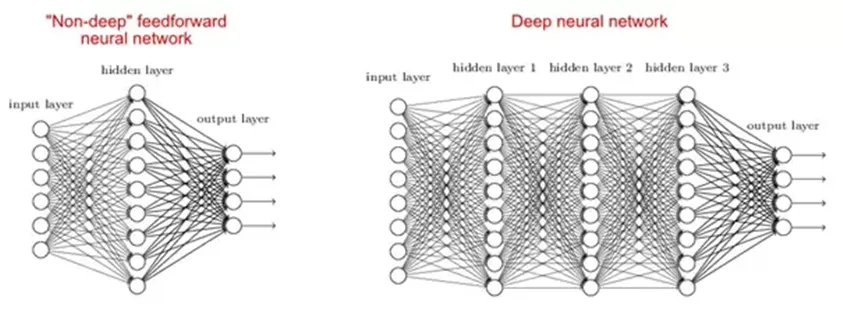
2. ¿Por qué las redes profundas son mejores que las superficiales?
Responder:
Hay estudios que dicen que las redes superficiales y profundas pueden caber en cualquier función, pero como las redes profundas tienen varias capas ocultas, a menudo de diferentes tipos, por lo que pueden construir o extraer mejores características que los modelos superficiales con menos parámetros.
3. ¿Cuál es la función de costo?
Responder:
Una función de costo es una medida de la precisión de la red neuronal con respecto a la muestra de entrenamiento dada y la salida esperada. Es un valor único, no vector, ya que proporciona el rendimiento de la red neuronal en su conjunto. Se puede calcular de la siguiente manera: Error cuadrático medio: -
MSE = 1n∑i = 0n (Y i – Yi) 2
Donde Y y el valor deseado Y es lo que queremos minimizar.
Pasemos a las siguientes preguntas de la entrevista de aprendizaje profundo.
4. ¿Qué es el descenso de gradiente?
Responder:
El descenso de gradiente es básicamente un algoritmo de optimización, que se utiliza para aprender el valor de los parámetros que minimiza la función de costo. Es un algoritmo iterativo que se mueve en la dirección del descenso más pronunciado según lo definido por el negativo del gradiente. Calculamos el descenso de gradiente de la función de costo para un parámetro dado y actualizamos el parámetro mediante la siguiente fórmula:
Θ: = Θ – αd∂ΘJ (Θ)
Donde Θ - es el vector de parámetros, α - tasa de aprendizaje, J (Θ) - es una función de costo.
5. ¿Qué es la retropropagación?
Responder:
La retropropagación es un algoritmo de entrenamiento utilizado para una red neuronal multicapa. En este método, movemos el error desde un extremo de la red a todos los pesos dentro de la red y, por lo tanto, permite un cálculo eficiente del gradiente. Se puede dividir en varios pasos de la siguiente manera: -
Reenviar la propagación de datos de entrenamiento para generar resultados.
UsingLuego, utilizando el valor objetivo y la derivada de error del valor de salida se puede calcular con respecto a la activación de salida.
HenLuego retrocedemos para calcular la derivada del error con respecto a la activación de salida en la anterior y continuamos esto para todas las capas ocultas.
SingUtilizando derivadas calculadas previamente para la salida y todas las capas ocultas calculamos derivadas de error con respecto a los pesos.
Y luego actualizamos los pesos.
6. Explique las siguientes tres variantes del descenso de gradiente: ¿lote, estocástico y mini lote?
Responder:
Descenso de gradiente estocástico : aquí usamos solo un ejemplo de entrenamiento para calcular el gradiente y actualizar los parámetros.
Descenso de gradiente por lotes : aquí calculamos el gradiente para todo el conjunto de datos y realizamos la actualización en cada iteración.
Descenso de gradiente de mini lotes : es uno de los algoritmos de optimización más populares. Es una variante del descenso de gradiente estocástico y aquí, en lugar de un solo ejemplo de entrenamiento, se utiliza un mini lote de muestras.
Parte 2 - Preguntas de la entrevista de aprendizaje profundo (avanzado)
Veamos ahora las preguntas avanzadas de la entrevista de aprendizaje profundo.
7. ¿Cuáles son los beneficios del descenso de gradiente de mini lotes?
Responder:
A continuación se presentan los beneficios del descenso de gradiente de mini lotes
• Esto es más eficiente en comparación con el descenso de gradiente estocástico.
• La generalización al encontrar los mínimos planos.
• Los mini lotes permiten la ayuda para aproximar el gradiente de todo el conjunto de entrenamiento, lo que nos ayuda a evitar los mínimos locales.
8. ¿Qué es la normalización de datos y por qué la necesitamos?
Responder:
La normalización de datos se utiliza durante la propagación hacia atrás. El motivo principal detrás de la normalización de datos es reducir o eliminar la redundancia de datos. Aquí reescalamos los valores para que quepan en un rango específico para lograr una mejor convergencia.
Pasemos a las siguientes preguntas de la entrevista de aprendizaje profundo.
9. ¿Qué es la inicialización de peso en redes neuronales?
Responder:
La inicialización del peso es uno de los pasos más importantes. Una mala inicialización de peso puede evitar que una red aprenda, pero una buena inicialización de peso ayuda a lograr una convergencia más rápida y un mejor error general. Los sesgos generalmente se pueden inicializar a cero. La regla para establecer los pesos es estar cerca de cero sin ser demasiado pequeño.
10. ¿Qué es un codificador automático?
Responder:
Un autoencoder es un algoritmo autónomo de aprendizaje automático que utiliza el principio de retropropagación, donde los valores objetivo se configuran para que sean iguales a las entradas proporcionadas. Internamente, tiene una capa oculta que describe un código utilizado para representar la entrada.
Algunos hechos clave sobre el codificador automático son los siguientes:
• Es un algoritmo de ML no supervisado similar al análisis de componentes principales
• Minimiza la misma función objetivo que el Análisis de componentes principales
• Es una red neuronal.
• La salida objetivo de la red neuronal es su entrada
11. ¿Está bien conectarse desde una salida de Capa 4 a una entrada de Capa 2?
Responder:
Sí, esto se puede hacer teniendo en cuenta que la salida de la capa 4 es del paso de tiempo anterior, como en RNN. Además, debemos suponer que el lote de entrada anterior a veces está correlacionado con el lote actual.
Pasemos a las siguientes preguntas de la entrevista de aprendizaje profundo.
12. ¿Qué es la máquina Boltzmann?
Responder:
Boltzmann Machine se utiliza para optimizar la solución de un problema. El trabajo de la máquina Boltzmann es básicamente optimizar los pesos y la cantidad para el problema dado.
Algunos puntos importantes sobre la máquina Boltzmann:
• Utiliza una estructura recurrente.
• Se compone de neuronas estocásticas, que consisten en uno de los dos estados posibles, 1 o 0.
• Las neuronas en esto están en un estado adaptativo (estado libre) o bloqueado (estado congelado).
• Si aplicamos recocido simulado en una red Hopfield discreta, se convertiría en la máquina Boltzmann.
13. ¿Cuál es el papel de la función de activación?
Responder:
La función de activación se utiliza para introducir la no linealidad en la red neuronal y ayudarla a aprender funciones más complejas. Sin el cual la red neuronal solo podría aprender la función lineal, que es una combinación lineal de sus datos de entrada.
Artículos recomendados
Esta ha sido una guía para la Lista de preguntas y respuestas de la entrevista de aprendizaje profundo para que el candidato pueda tomar medidas enérgicas contra estas preguntas de la entrevista de aprendizaje profundo fácilmente. También puede consultar los siguientes artículos para obtener más información.
- Conozca las 10 preguntas más útiles de la entrevista de HBase
- Preguntas y respuestas útiles para la entrevista de Machine Learning
- Las 5 preguntas más importantes de la entrevista de ciencia de datos
- Preguntas y respuestas importantes de la entrevista de Ruby