
Diferencia entre HBase y Cassandra
HBase es una base de datos que utiliza el sistema de archivos distribuidos de Hadoop para su almacenamiento. HBase es una parte importante de HDFS y se ejecuta sobre el clúster de Hadoop. HBase no es una base de datos relacional tradicional, requiere un enfoque de modelado de datos diferente. Cassandra trabaja en el modelo de replicación de datos, por lo que en caso de no disponibilidad de ningún nodo no habrá pérdida de datos. Cassandra es una base de datos distribuida, lo que significa que un cliente puede acceder a los datos desde cualquier clúster y desde cualquier nodo
1.1) Cassandra:
Fue iniciado por Facebook porque siempre está en el requisito de la aplicación. Cassandra se inició en 2005 y se puso a disposición del público en 2008. Cassandra se desarrolló para aplicaciones siempre activas, como redes sociales como Facebook y Twitter.
Cassandra trabaja en una arquitectura "siempre activa " y tiene un modelo de nodo Activo-Activo para que no haya SPoF (punto único de falla). CQL (Cassandra Query Language) es el lenguaje de consulta de Cassandra pero tiene una sintaxis igual que SQL. Es compatible con todos los principales sistemas operativos como Linux, Unix, OSX y Windows.
Siempre encendido:
Cassandra es una base de datos con un modelo de distribución y todos los nodos son iguales dentro del clúster. Los datos se replican en nodos configurables, por lo que en caso de falla de algunos no. de nodos no dará como resultado la pérdida de datos.
(Siempre en modelo)
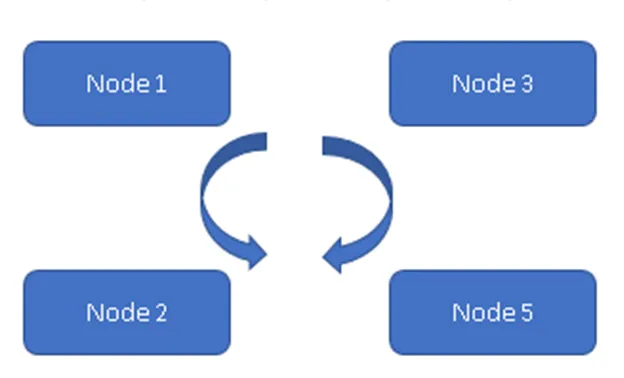
En la Figura 1, los cuatro nodos están sincronizados entre sí y replican los datos dentro del clúster. Todos están trabajando en el Modelo Activo-Activo, por lo que en caso de falla de un nodo no se perderán datos. Un cliente puede leer los datos del resto de los nodos / nodos disponibles.
1.2) HBase:
HBase es una base de datos basada en NoSQL y diseñada para procesar consultas en tablas grandes que tienen miles de millones de filas con millones de columnas y se ejecutan en un grupo de productos básicos / hardware normal. Le proporciona capacidades de consulta en tiempo real con la velocidad de un " almacén de clave / valor " .
HBase realmente se basa / trabaja en un modelo de datos de cuatro dimensiones.
- ID de fila / clave de fila
- Familia de columna.
- Pares clave-valor.
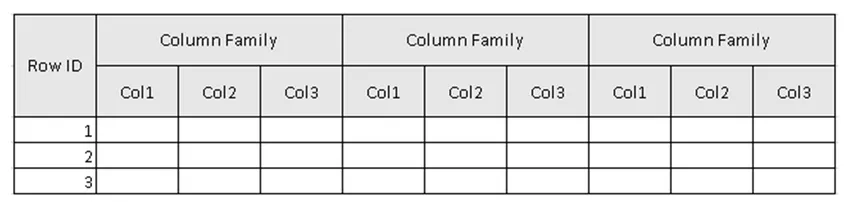
(Figura 2, esquema de ejemplo de la tabla en HBase).
En la Figura 2, Tabla es la colección de Column Family y Column Family es la colección de Columnas. Las columnas son la colección de pares clave-valor
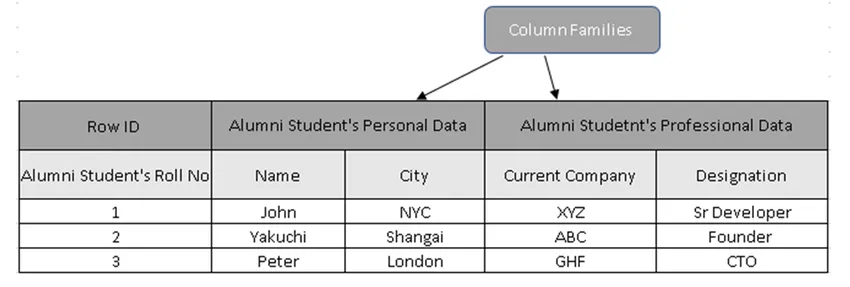
(Figura 3, Tabla de muestra en HBase)
En la Figura 3, las familias de columnas son la recopilación de datos de alumnos Alumni y las ID de fila (claves de fila) contienen el número de lista del alumno
De hecho, las teclas de fila contienen el valor único contra los datos de la familia de columnas. Al usar la tecla Row, se pueden extraer todos los detalles, por lo que las bases de datos orientadas a columnas son mucho más rápidas que las bases de datos tradicionales.
Apache HBase se puede usar para acceso de lectura / escritura aleatorio y proporciona soporte para fallas. También es compatible con la replicación y el trabajo en el modelo de base de datos de distribución.
Comparación cabeza a cabeza de HBase vs Cassandra (infografía)
A continuación se muestra la diferencia de los 9 principales entre HBase y Cassandra
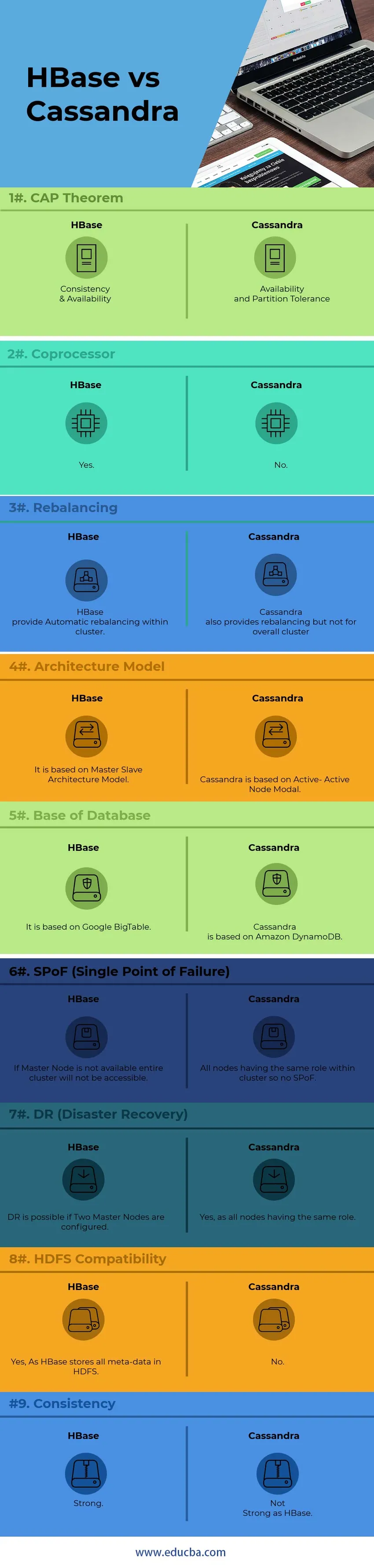 Diferencias clave entre HBase y Cassandra
Diferencias clave entre HBase y Cassandra
A continuación se encuentran las listas de puntos, describa las diferencias clave entre HBase y Cassandra:
1) Para la comunicación interna del nodo, Cassandra usa el protocolo GOSSIP mientras que HBase se basa en Zookeeper. Los servicios del Protocolo GOSSIP están integrados con Cassandra. Otra parte de Zookeeper es una aplicación de distribución completamente separada.
2) En la arquitectura Cassandra, todos los nodos funcionan como Nodo Activo mientras que el arquitecto HBase sigue el modelo de Nodo Maestro-Esclavo. En el modelo de nodo activo-activo, no hay SPoF (punto único de falla). En HBase, si el nodo maestro se cae, no se podrá acceder al clúster completo.
3) HBase admite el modelo de búsqueda de árbol binario, mientras que Cassandra no admite el modelo de árbol B Sin árbol B, no puede buscar la familia de columnas del usuario para todas las personas con un aniversario en abril, mientras que puede buscar a todos los que viven en Beijing con un Aniversario en abril.
4) HBase, admite los lenguajes de script C, C ++, Java, Python, Scala, mientras que Cassandra también admite JavaScript y Ruby.
5) HBase tiene una característica llamada como coprocesadores, mientras que Cassandra no tiene esa característica a partir de ahora. Los coprocesadores proporcionan una biblioteca y un entorno de tiempo de ejecución para ejecutar el código de usuario dentro del servidor de la región HBase y los procesos maestros.
6) HBase está diseñado para admitir el almacén de datos, mientras que Cassandra será perfecto para aplicaciones que se ejecutan todo el tiempo, como aplicaciones web y móviles.
7) El lenguaje de consulta HBase es un lenguaje personalizado que debe aprenderse mientras Cassandra usa su propio CQL desarrollado (Cassandra Query Language), que es un lenguaje tipo SQL
8) Administrar Cassandra es mucho más fácil que HBase. En Cassandra, se debe ejecutar un solo proceso Java por nodo, mientras que para HBase, HDFS totalmente operativo, varios procesos HBase y un sistema Zookeeper.
9) HBase realiza sumas de verificación de extremo a extremo y reequilibrio automático, mientras que Cassandra no admite el reequilibrio general del clúster.
10) Basado en el " Teorema CAP", Cassandra trabaja en el modelo AP mientras que HBase es el modelo CP.
Teorema de la PAC
Este teorema se usa para sistemas distribuidos. C significa Consistencia, A significa Disponibilidad y P es Tolerancia de Partición. Teorema de CAP explicado a continuación:
C (coherencia): la coherencia significa que si alguien ha escrito un valor en una base de datos, otros pueden leer inmediatamente el mismo valor.
A (Disponibilidad) : Disponibilidad significa que si algunos nodos no están disponibles en su clúster (Los nodos se desconectaron / no viven en el clúster debido a algún problema) no afectarán a todo el clúster y el Sistema distribuido / Base de datos estará disponible para acceder a los datos. El Cluster estará accesible para todo tipo de tareas.
P (Tolerancia de partición): Tolerancia de partición significa que si un Centro de datos se cae aún, eso no debería afectar los datos presentes en los nodos y todos los datos deberían estar accesibles en cualquier momento. Significa que la tolerancia de partición permite una mejor replicación de datos a otros centros de datos, así como dentro del entorno del clúster.
Tabla comparativa de HBase vs Cassandra
| Puntos | HBase | Cassandra |
| Teorema de la PAC | Consistencia y Disponibilidad | Disponibilidad y tolerancia de partición |
| Coprocesador | si | No |
| Reequilibrio | HBase proporciona un reequilibrio automático dentro de un clúster. | Cassandra también proporciona reequilibrio, pero no para el clúster general |
| Modelo de arquitectura | Se basa en el modelo de arquitectura maestro-esclavo | Cassandra se basa en el modo de nodo activo-activo |
| Base de base de datos | Está basado en Google BigTable | Cassandra está basada en Amazon DynamoDB |
| SPoF (Punto único de falla) | Si el nodo maestro no está disponible, no se podrá acceder a todo el clúster | Todos los nodos tienen la misma función dentro del clúster, por lo que no hay SPoF |
| DR (recuperación de desastres) | DR es posible si se configuran dos nodos maestros. | Sí, ya que todos los nodos tienen el mismo rol |
| Compatibilidad HDFS | Sí, ya que HBase almacena todos los metadatos en HDFS | No |
| Consistencia | Fuerte | No fuerte como HBase |
Conclusión - HBase vs Cassandra
Facebook y otra parte de las redes sociales preferirían HBase (anteriormente ambos usaban Cassandra, consulte la publicación de Facebook) debido a su disponibilidad, otro sector de dominio de banca lateral busca seguridad para todas sus transacciones financieras, por lo que seleccionarían a Cassandra sobre HBase.
Las características clave de Cassandra implican Alta disponibilidad, Administración mínima y Sin SPoF (Punto único de falla). El otro lado de HBase es bueno para leer y escribir más rápidamente los datos con escalabilidad lineal.
Empresas como Verizon, Bloomberg, Bank of America y muchas más están utilizando HBase y Cassandra está siendo utilizada por los principales sitios de redes sociales como Twitter, Facebook, etc.
No podemos concluir cuál es el mejor, HBase y Cassandra tienen sus propias ventajas y desventajas. El rendimiento real de las bases de datos HBase y Cassandra se puede ver en el entorno de producción.
Artículos recomendados:
Esta ha sido una guía de HBase vs Cassandra, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- Hadoop vs Apache Spark: cosas interesantes que debes saber
- ¿Cómo descifrar la entrevista para desarrolladores de Hadoop?
- Las 5 principales tendencias de Big Data
- 5 desafíos de Big Data Analytics