

¿Qué es el análisis de conglomerados?
El análisis de conglomerados agrupa los datos en función de las características que poseen. El análisis de conglomerados agrupa objetos en función de los factores que los hacen similares. El análisis de conglomerados se denomina análisis de segmentación o análisis de taxonomía. El análisis de conglomerados no diferencia las variables dependientes e independientes. El análisis de conglomerados se utiliza en una amplia variedad de campos, como psicología, biología, estadística, minería de datos, reconocimiento de patrones y otras ciencias sociales.
Objetivo del análisis de clúster
El objetivo principal del análisis de conglomerados es abordar la heterogeneidad en cada conjunto de datos. Los otros objetivos de análisis de clúster son
- Descripción de la taxonomía : identificación de grupos dentro de los datos
- Simplificación de datos : la capacidad de analizar grupos de observaciones similares en lugar de todas las observaciones individuales
- Generación o prueba de hipótesis: desarrolle hipótesis basadas en la naturaleza de los datos o para probar la hipótesis establecida anteriormente
- Identificación de relación : la estructura simplificada del análisis de conglomerados que describe las relaciones
Hay dos propósitos principales del análisis de conglomerados: comprensión y utilidad.
En circunstancias de comprensión, el análisis de conglomerados agrupa objetos que comparten algunas características comunes
En el propósito de Utility, el análisis de clúster proporciona las características de cada objeto de datos a los clústeres a los que pertenecen.
El análisis de conglomerados va de la mano con el análisis factorial y el análisis discriminante.
Debe hacerse algunas preguntas de análisis de conglomerados antes de comenzar
- ¿Qué variables son relevantes?
- ¿Es suficiente el tamaño de la muestra?
- ¿Se pueden detectar valores atípicos y se deben eliminar?
- ¿Cómo debe medirse la similitud de objeto?
- ¿Deberían estandarizarse los datos?

Tipos de agrupaciones
Hay tres tipos principales de agrupamiento
- Agrupación jerárquica : que contiene el método aglomerativo y divisivo
- Agrupamiento Particional - Contiene K-Means, Fuzzy K-Means, Isodata debajo de él
- Agrupación basada en la densidad : tiene Denclust, CLUPOT, Mean Shift, SVC, Parzen-Watershed debajo de ella
Suposiciones en el Análisis de Cluster
Siempre hay dos supuestos en el análisis de conglomerados
- Se supone que la muestra es representativa de la población.
- Se supone que las variables no están correlacionadas. Incluso si las variables están correlacionadas, elimine las variables correlacionadas o use medidas de distancia que compensen la correlación.
Pasos en el análisis de clúster
-
- Paso 1: definir el problema
- Paso 2: Decidir la medida de similitud apropiada
- Paso 3: decide cómo agrupar los objetos
- Paso 4: decida el número de clústeres
- Paso 5: interpretar, describir y validar el clúster
Análisis de clúster en SPSS
En SPSS puede encontrar la opción de análisis de clúster en la opción Analizar / Clasificar. En SPSS existen tres métodos para el análisis de conglomerados: K-Means Cluster, Hierarchical Cluster y Two Step Step Cluster.
El método de clúster K-Means clasifica un conjunto de datos dado a través de un número fijo de clústeres. Este método es fácil de entender y ofrece la mejor salida cuando los datos están bien separados entre sí.
El análisis de clúster en dos pasos es una herramienta diseñada para manejar grandes conjuntos de datos. Crea grupos en variables categóricas y continuas.
El grupo jerárquico es el método de análisis de grupos más utilizado. Combina casos en grupos homogéneos reuniéndolos a través de una serie de pasos secuenciales.
El análisis de agrupamiento jerárquico contiene tres pasos.
- Calcular la distancia
- Vincula los grupos
- Elegir una solución seleccionando el número correcto de clústeres
A continuación se detallan los pasos para realizar el análisis de clúster jerárquico en SPSS.
- El primer paso es seleccionar las variables que se van a agrupar. El siguiente cuadro de diálogo te lo explica
- Al hacer clic en la opción de estadísticas en el cuadro de diálogo anterior, obtendrá el cuadro de diálogo donde desea especificar la salida
- En los diagramas del cuadro de diálogo, agregue el Dendrograma. Dendrogram es la representación gráfica del método de análisis jerárquico de conglomerados. Muestra cómo se combinan los clústeres en cada paso hasta que se forma un solo clúster.
- El método del cuadro de diálogo es crucial. Puede mencionar la distancia y el método de agrupamiento aquí. En SPSS hay tres medidas para Intervalo, recuentos y datos binarios.
- La distancia euclidiana al cuadrado es la suma de las diferencias al cuadrado sin sacar la raíz cuadrada.
- En los recuentos, puede seleccionar entre la medida Chi Square y Phi Square
- En la sección Binario tienes muchas opciones para elegir. La distancia euclidiana al cuadrado es la mejor opción para usar.
- El siguiente paso es elegir el método de clúster. Siempre se recomienda usar Enlace único o Vecino más cercano, ya que ayuda fácilmente a identificar los valores atípicos. Después de identificar los valores atípicos, puede usar el Método de Ward.
- El último paso es la estandarización.
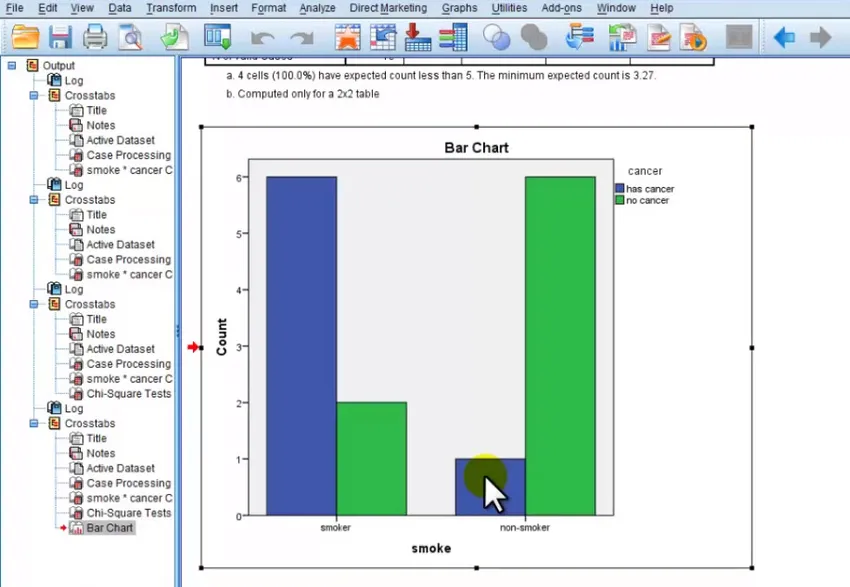
Críticas del análisis de conglomerados
Las críticas más comunes se enumeran a continuación.
- Es descriptivo, teórico y no inferencial.
- Producirá grupos independientemente de la existencia real de cualquier estructura.
- No se puede utilizar ampliamente, ya que depende totalmente de las variables utilizadas como base para la medida de similitud
¿Qué es el análisis factorial?
El análisis factorial es un análisis exploratorio que ayuda a agrupar variables similares en dimensiones. Se puede utilizar para simplificar los datos al reducir las dimensiones de las observaciones. El análisis factorial tiene varios métodos de rotación diferentes.
El análisis factorial se utiliza principalmente para fines de reducción de datos.
Hay dos tipos de análisis factorial: exploratorio y confirmatorio.
- El método exploratorio se utiliza cuando no tiene una idea predefinida sobre las estructuras o dimensiones en un conjunto de variables.
- El método confirmatorio se usa cuando se quiere probar hipótesis específicas sobre las estructuras o dimensiones en un conjunto de variables.
Objetivos del análisis factorial
Hay dos objetivos principales del análisis factorial que se mencionan a continuación.
- Identificación de los factores subyacentes : esto incluye agrupar variables en conjuntos homogéneos, crear nuevas variables y ayudar a obtener conocimiento sobre las categorías.
- Detección de variables : es útil en la regresión e identifica agrupaciones para permitirle seleccionar una variable que represente muchas.
Supuestos del análisis factorial
Hay cuatro supuestos principales del análisis factorial que se mencionan a continuación.
- Los modelos generalmente se basan en relaciones lineales
- Se supone que los datos recopilados son escalados a intervalos.
- La multicolinealidad en los datos es deseable ya que el objetivo es descubrir el conjunto de variables interrelacionadas
- Los datos deben ser abiertos y receptivos para el análisis factorial. No debe ser de tal manera que una variable solo esté correlacionada consigo misma y no exista correlación con ninguna otra variable. El análisis factorial no se puede hacer en tales datos.
Tipos de factoring
- Factorización de componentes principales : el método más utilizado donde los pesos de los factores se calculan para extraer la máxima varianza posible y continúa hasta que no quede ninguna varianza significativa.
- Análisis factorial canónico : encuentra factores que tienen la mayor correlación canónica con las variables observadas
- Análisis factorial común : busca el menor número de factores que pueden explicar la varianza común de un conjunto de variables
- Factorización de imagen : basado en la matriz de correlación donde cada variable se predice a partir de las otras mediante regresión múltiple
- Factorización alfa : maximiza la fiabilidad de los factores
- Modelo de regresión de factores : combinación de modelo de factores y modelo de regresión cuyos factores se conocen parcialmente
Criterios de análisis factorial
-
Criterios de valor propio
- Representa la cantidad de varianza en las variables originales que está conectada con un factor
- La suma del cuadrado de las cargas factoriales de cada variable en un factor representa el valor propio
- Se mantienen los factores con valores propios superiores a 1.0
-
Criterios de trama de pantalla
- Una gráfica de los valores propios contra el número de factores, en orden de extracción.
- La forma de la trama determina el número de factores.
-
Porcentaje de criterios de varianza
- El número de factores extraídos se determina de modo que el porcentaje creciente de varianza extraído por los factores alcance el nivel de satisfacción.
-
Criterios de prueba de significación
- Se descubre la importancia estadística de los valores propios separados, y solo se conservan aquellos factores que son estadísticamente significativos.
El análisis factorial se utiliza en diversos campos como psicología, sociología, ciencias políticas, educación y salud mental.
Análisis factorial en SPSS
En SPSS, la opción de análisis factorial se puede encontrar en Analizar à Reducción de dimensión à Factor
- Comience agregando las variables a la sección de la lista de variables
- Haga clic en la pestaña Descriptivo y agregue algunas estadísticas bajo las cuales se verifican los supuestos del análisis factorial.
- Haga clic en la opción Extracción que le permitirá elegir el método de extracción y el valor de corte para la extracción.
- Componentes principales (PCA) es el método de extracción predeterminado que extrae incluso combinaciones lineales no correlacionadas de las variables. PCA se puede usar cuando una matriz de correlación es singular. Es muy similar al análisis de correlación canónica, donde el primer factor tiene la varianza máxima y los siguientes factores explican una porción más pequeña de la varianza.
- El segundo análisis más general es la factorización del eje principal. Identifica las construcciones latentes detrás de las observaciones.
- El siguiente paso es seleccionar un método de rotación. El método más utilizado es Varimax. Este método simplifica la interpretación de los factores.
- El segundo método es Quartimax. Este método rota los factores para minimizar la cantidad de factores. Simplifica la interpretación de la variable observada.
- El siguiente método es Equamax, que es una combinación de los dos métodos anteriores.
- En el cuadro de diálogo haciendo clic en las "opciones" puede administrar los valores faltantes
- Antes de guardar los resultados en el conjunto de datos, primero ejecute el análisis factorial y verifique las suposiciones y confirme que los resultados son significativos y útiles.
Análisis de clúster vs análisis factorial
Tanto el análisis de conglomerados como el análisis de factores son métodos de aprendizaje no supervisados que se utilizan para la segmentación de datos. Muchos investigadores que son nuevos en este campo sienten que el análisis de conglomerados y el análisis factorial son similares. Puede parecer similar, pero difieren en muchos aspectos. Las diferencias entre el análisis de conglomerados y el análisis factorial se enumeran a continuación.
-
Objetivo
El objetivo del análisis factorial y factorial es diferente. El objetivo del análisis de conglomerados es dividir las observaciones en grupos homogéneos y distintos. El análisis factorial, por otro lado, explica la homogeneidad de las variables resultantes de la similitud de los valores.
-
Complejidad
La complejidad es otro factor en el que difieren el análisis de conglomerados y factorial. El tamaño de los datos afecta el análisis de manera diferente. Si el tamaño de los datos es demasiado grande, se vuelve computablemente intratable en el análisis de conglomerados.
-
Solución
La solución a un problema es más o menos similar tanto en el análisis factorial como en el análisis de conglomerados. Pero el análisis factorial proporciona una mejor solución para el investigador en un mejor aspecto. El análisis de conglomerados no produce el mejor resultado ya que todos los algoritmos en el análisis de conglomerados son computacionalmente ineficientes.
-
Aplicaciones
El análisis factorial y el análisis de conglomerados se aplican de manera diferente a los datos reales. El análisis factorial es adecuado para simplificar modelos complejos. Reduce el gran conjunto de variables a un conjunto mucho más pequeño de factores. El investigador puede desarrollar un conjunto de hipótesis y ejecutar un análisis factorial para confirmar o negar estas hipótesis.
El análisis de conglomerados es adecuado para clasificar objetos según ciertos criterios. El investigador puede medir ciertos aspectos de un grupo y dividirlos en categorías específicas mediante el análisis de conglomerados.
También hay muchas otras diferencias que se mencionan a continuación.
- El análisis de clúster intenta agrupar casos, mientras que el análisis factorial intenta agrupar características.
- El análisis de conglomerados se utiliza para encontrar grupos más pequeños de casos que son representativos de los datos en su conjunto. El análisis factorial se utiliza para encontrar un grupo más pequeño de características que son representativas de las características originales de los conjuntos de datos.
- La parte más importante del análisis de conglomerados es encontrar el número de conglomerados. Básicamente, los métodos de agrupamiento se dividen en dos: método de aglomeración y método de partición. El método aglomerativo comienza con cada caso en su propio grupo y se detiene cuando se alcanza un criterio. El método de partición comienza con todos los casos en un clúster.
- El análisis factorial se utiliza para descubrir una estructura subyacente en un conjunto de datos.
Conclusión
Espero que este artículo le haya ayudado a comprender los conceptos básicos del análisis de clúster y el análisis factorial y las diferencias entre los dos.
Cursos relacionados :-
- Curso de Análisis de Clúster