
Introducción a la ciencia de datos
Data Science es uno de los trabajos de más rápido crecimiento, desafiantes y mejor remunerados de esta década. Entonces, la pregunta es ¿qué es la ciencia de datos? la ciencia de datos es un campo interdisciplinario (consta de más de una rama de estudio) que utiliza estadísticas, ciencias de la computación y algoritmos de aprendizaje automático para obtener información de datos estructurados y no estructurados. Según 'Economic Times', India ha visto un aumento de más del 400 por ciento en la demanda de profesionales de la ciencia de datos en diversos sectores de la industria en un momento en que la oferta de dicho talento es testigo de un lento crecimiento.
Componentes principales de la ciencia de datos
Los principales componentes o procesos seguidos en la Introducción a la ciencia de datos son los siguientes:
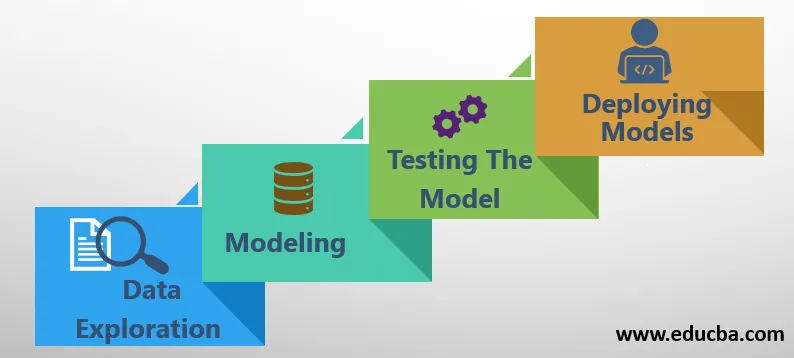
1. Exploración de datos
Es el paso más importante ya que este paso consume la mayor cantidad de tiempo. Alrededor del 70 por ciento del tiempo se dedica a la exploración de datos. El ingrediente principal para la ciencia de datos son los datos, por lo que cuando obtenemos datos, rara vez esos datos están en una forma estructurada correcta. Hay mucho ruido presente en los datos. Ruido aquí significa una gran cantidad de datos no deseados que no se requieren. Entonces, ¿qué hacemos en este paso? Este paso implica el muestreo y la transformación de datos en los que verificamos las observaciones (filas) y las características (columnas) y eliminamos el ruido mediante el uso de métodos estadísticos. Este paso también se usa para verificar la relación entre varias características (columnas) en el conjunto de datos, por la relación nos referimos a si las características (columnas) son dependientes entre sí o independientes, si faltan valores en los datos o no. Entonces, básicamente, los datos se transforman y preparan para su uso posterior. Por lo tanto, este es uno de los pasos más largos.
2. Modelado
Entonces, ahora nuestros datos están preparados y listos para funcionar. Este es el segundo paso donde realmente usamos algoritmos de Machine Learning. Aquí en realidad ajustamos los datos al modelo. La selección de un modelo depende del tipo de datos que tenemos y los requisitos comerciales. Por ejemplo, la selección del modelo para recomendar un artículo a un cliente será diferente del modelo requerido para predecir la cantidad de artículos que se venderán en un día en particular. Una vez que se decide el modelo, ajustamos los datos en el modelo.
3. Prueba del modelo
Es el siguiente paso y muy importante con respecto al rendimiento del modelo. El modelo se prueba con datos de prueba para verificar la precisión y otras características del modelo y hacer los cambios necesarios en el modelo para obtener el resultado deseado. En caso de que no obtengamos la precisión deseada, podemos volver al paso 2 (modelado), seleccionar un modelo diferente y luego repetir el mismo paso 3 y elegir el modelo que ofrezca el mejor resultado según los requisitos del negocio.
4. Implementación de modelos
Una vez que obtenemos el resultado deseado mediante las pruebas adecuadas según los requisitos del negocio, finalizamos el modelo que nos da el mejor resultado según los resultados de las pruebas e implementamos el modelo en el entorno de producción.
Características de la ciencia de datos
Las características de un científico de datos son las siguientes:
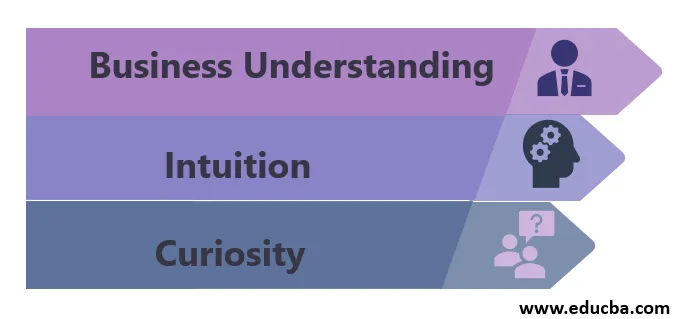
1. Entendimiento empresarial
Es la característica más importante ya que, a menos que comprenda el negocio, no puede hacer un buen modelo, incluso si tiene un buen conocimiento de algoritmos de aprendizaje automático o habilidades estadísticas. Un científico de datos debe comprender los requisitos comerciales y desarrollar análisis de acuerdo con ellos. Por lo tanto, el conocimiento del dominio del negocio también se vuelve importante o útil.
2. Intuición
Aunque las matemáticas involucradas son probadas y fundamentales, un científico de datos debe elegir el modelo correcto con la precisión correcta. Como todos los modelos no cederán exactamente los mismos resultados. Por lo tanto, un científico de datos debe sentir cuándo un modelo está listo para la implementación de producción. También necesitan la intuición para saber en qué punto el modelo de producción está obsoleto y necesita una refactorización para responder al entorno empresarial cambiante.
3. curiosidad
Data Science no es un campo nuevo. También ha estado allí antes, pero el progreso que se está haciendo en este campo es muy rápido y constantemente se desarrollan nuevos métodos para resolver problemas familiares, por lo que la curiosidad de un científico de datos por aprender tecnologías emergentes se vuelve muy importante.
Aplicaciones
Aquí, en la introducción a la ciencia de datos, hemos aclarado sobre las aplicaciones de la ciencia de datos que es enorme. Se requiere en todos los campos. Aquí hay ejemplos de algunos sectores donde la ciencia de datos puede usarse o usarse activamente.
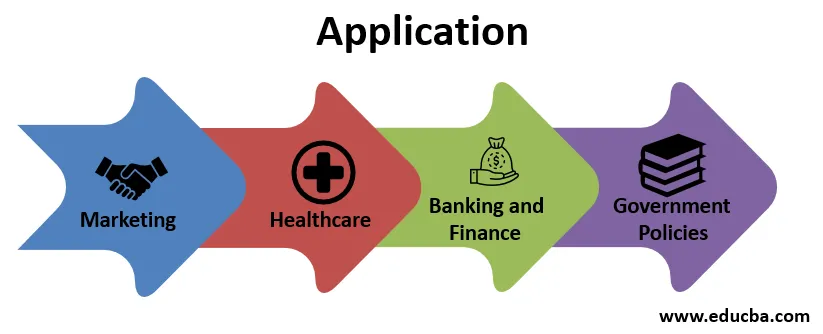
1. Comercialización
Existe un gran alcance en marketing, por ejemplo, estrategia de precios mejorada. Empresas como Uber, las compañías de comercio electrónico pueden usar precios basados en datos científicos que les permiten aumentar sus ganancias.
2. Asistencia sanitaria
Uso de datos ponibles para prevenir y monitorear problemas de salud. Los datos generados por el cuerpo se pueden usar en la atención médica para prevenir futuras emergencias.
3. Banca y finanzas
Mientras discutimos la introducción a la ciencia de datos ahora, seguiremos adelante con la aplicación de los usos de la ciencia de datos en el sector bancario para la detección de fraudes, lo que puede ser útil para reducir los activos no rentables de los bancos.
4. Políticas gubernamentales
El Gobierno puede utilizar la ciencia de datos para preparar mejores políticas para satisfacer mejor las necesidades de las personas y lo que desean utilizando los datos que pueden obtener mediante la realización de encuestas y otras fuentes de otras fuentes oficiales.
Ventajas y desventajas de la ciencia de datos
Después de analizar todos los componentes, características y la amplia Introducción a la Ciencia de Datos, vamos a explorar las ventajas y desventajas de la Ciencia de Datos:
Ventajas
En este tema de Introducción a la ciencia de datos, también le mostramos las ventajas de la ciencia de datos. Algunos de ellos son los siguientes:
- Nos ayuda a obtener información de los datos históricos con sus poderosas herramientas.
- Ayuda a optimizar el negocio, contratar a las personas adecuadas y generar más ingresos, ya que el uso de la ciencia de datos le ayuda a tomar mejores decisiones futuras para el negocio.
- Las empresas pueden desarrollar y comercializar mejor sus productos, ya que pueden seleccionar mejor a sus clientes objetivo.
- Introducción a Data Science también ayuda a los consumidores a buscar mejores productos, especialmente en sitios de comercio electrónico basados en el sistema de recomendación basado en datos.
Desventajas
Mientras estudiamos acerca de la introducción a la ciencia de datos ahora avanzamos con las desventajas de la ciencia de datos:
Las desventajas son generalmente cuando la ciencia de datos se utiliza para la creación de perfiles de clientes y la violación de la privacidad del cliente, ya que su información, como transacciones, compras y suscripciones, es visible en sus empresas matrices. La información obtenida utilizando la ciencia de datos se puede utilizar contra un determinado grupo, individuo, país o comunidad.
Artículos recomendados
Esta ha sido una guía de Introducción a la Ciencia de Datos. Aquí hemos discutido la introducción a la ciencia de datos con los principales componentes y características de la introducción a la ciencia de datos. También puede consultar los siguientes artículos:
- Ciencia de datos vs visualización de datos
- Preguntas de la entrevista de ciencia de datos
- Data Science vs Data Analytics
- Análisis predictivo vs ciencia de datos
- Algoritmos de ciencia de datos | Tipos