
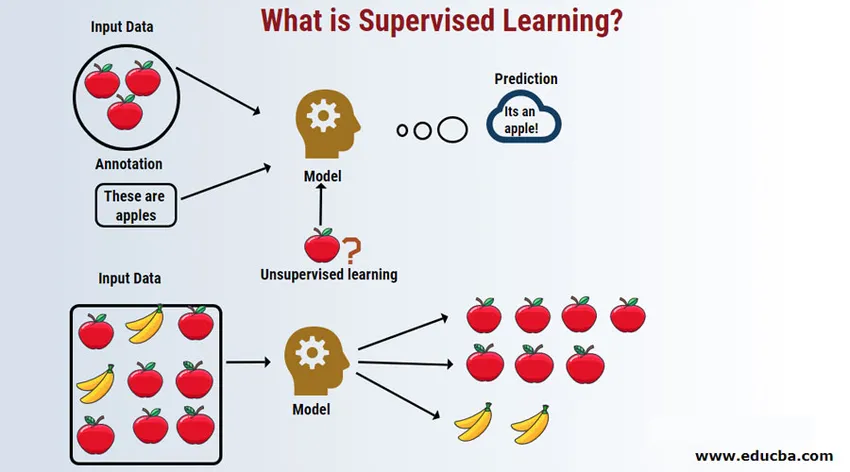
Introducción al aprendizaje supervisado
El aprendizaje supervisado es un área de aprendizaje automático donde trabajamos para predecir los valores utilizando conjuntos de datos etiquetados. Los conjuntos de datos de entrada etiquetados se denominan variable independiente, mientras que los resultados pronosticados se denominan variable dependiente porque dependen de la variable independiente para sus resultados. Por ejemplo, todos tenemos una carpeta de correo no deseado en nuestra cuenta de correo electrónico (por ejemplo, Gmail) que detecta automáticamente la mayoría de los correos electrónicos no deseados / fraudes para usted con una precisión superior al 95%. Funciona en base a un modelo de aprendizaje supervisado en el que tenemos un conjunto de capacitación de datos etiquetados, que en este caso es correo electrónico con etiqueta marcado por los usuarios. Estos conjuntos de capacitación se utilizan para el aprendizaje, que luego se utilizarán para la categorización de nuevos correos electrónicos como spam si se ajusta a la categoría.
Trabajando en aprendizaje automático supervisado
Comprendamos el aprendizaje automático supervisado con la ayuda de un ejemplo. Digamos que tenemos una cesta de frutas que se llena con diferentes especies de frutas. Nuestro trabajo es clasificar las frutas según su categoría.
En nuestro caso, hemos considerado cuatro tipos de frutas y esas son manzana, plátano, uvas y naranjas.
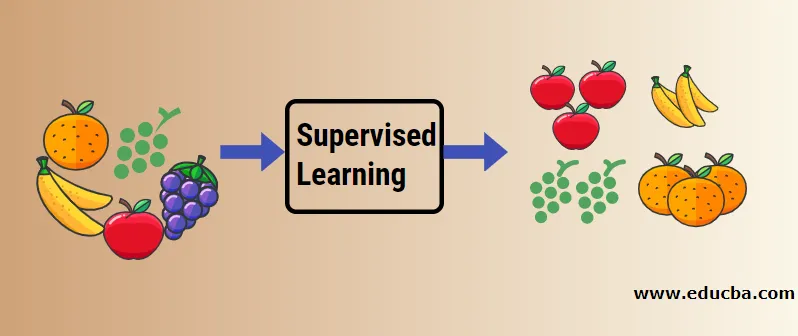
Ahora intentaremos mencionar algunas de las características únicas de estas frutas que las hacen únicas.
|
S No. | Talla | Color | Forma |
Nombre de pila |
|
1 | Pequeño | Verde | Redondo a ovalado, forma cilíndrica |
Uva |
|
2 | Grande | rojo | Forma redondeada con una depresión en la parte superior. |
manzana |
|
3 | Grande | Amarillo | Cilindro curvo largo |
Plátano |
| 4 4 | Grande | naranja | Forma redondeada |
naranja |
Ahora, digamos que ha recogido una fruta de la cesta de frutas, miró sus características, por ejemplo, su forma, tamaño y color, y luego dedujo que el color de esta fruta es rojo, el tamaño es grande, la forma es redondeada con depresión en la parte superior, por lo tanto, es una manzana.
- Del mismo modo, también haces lo mismo para todas las demás frutas restantes.
- La columna de la derecha ("Nombre de la fruta") se conoce como la variable de respuesta.
- Así es como formulamos un modelo de aprendizaje supervisado, ahora será bastante fácil para cualquiera nuevo (digamos un robot o un extraterrestre) con propiedades dadas para agrupar fácilmente el mismo tipo de frutas.
Tipos de algoritmo supervisado de aprendizaje automático
Veamos diferentes tipos de algoritmos de aprendizaje automático:
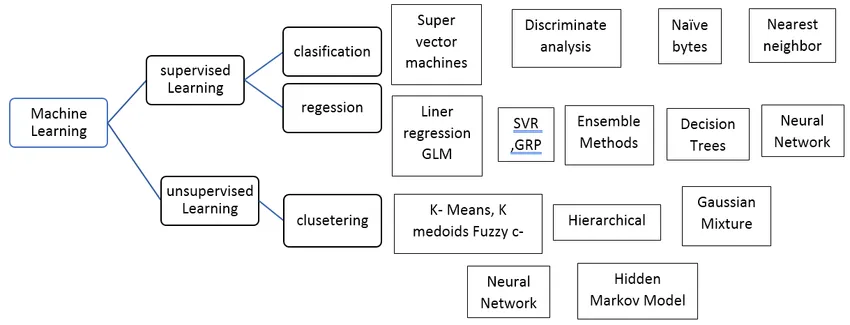
Regresión:
La regresión se usa para predecir la salida de un solo valor utilizando el conjunto de datos de entrenamiento. El valor de salida siempre se llama como la variable dependiente, mientras que las entradas se conocen como la variable independiente. Tenemos diferentes tipos de regresión en el aprendizaje supervisado, por ejemplo,
- Regresión lineal : aquí solo tenemos una variable independiente que se utiliza para predecir la salida, es decir, la variable dependiente.
- Regresión múltiple : aquí tenemos más de una variable independiente que se utiliza para predecir la salida, es decir, la variable dependiente.
- Regresión polinómica : aquí el gráfico entre las variables dependientes e independientes sigue una función polinómica. Por ejemplo, al principio, la memoria aumenta con la edad, luego alcanza un umbral a cierta edad y luego comienza a disminuir a medida que envejecemos.
Clasificación:
La clasificación de los algoritmos de aprendizaje supervisado se utiliza para agrupar objetos similares en clases únicas.
- Clasificación binaria: si el algoritmo está tratando de agrupar 2 grupos distintos de clases, entonces se llama clasificación binaria.
- Clasificación multiclase: si el algoritmo está tratando de agrupar objetos en más de 2 grupos, se llama clasificación multiclase.
- Fuerza : los algoritmos de clasificación generalmente funcionan muy bien.
- Inconvenientes: propenso al sobreajuste y podría no tener restricciones. Por ejemplo : clasificador de correo electrónico no deseado
- Regresión / clasificación logística: cuando la variable Y es una categoría binaria categórica (es decir, 0 o 1), utilizamos la regresión logística para la predicción. Por ejemplo : predecir si una determinada transacción con tarjeta de crédito es fraude o no.
- Clasificadores Naïve Bayes: el clasificador Naïve Bayes se basa en el teorema bayesiano. Este algoritmo suele ser más adecuado cuando la dimensionalidad de las entradas es alta. Consiste en gráficos acíclicos que tienen un nodo primario y muchos nodos secundarios. Los nodos secundarios son independientes entre sí.
- Árboles de decisión: un árbol de decisión es una estructura similar a un diagrama de árbol que consta de un nodo interno (prueba en el atributo), rama que denota el resultado de la prueba y los nodos hoja que representan la distribución de clases. El nodo raíz es el nodo superior. Es una técnica muy utilizada que se utiliza para la clasificación.
- Máquina de vectores de soporte: una máquina de vectores de soporte es o un SVM hace el trabajo de clasificación al encontrar el hiperplano que debería maximizar el margen entre 2 clases. Estas máquinas SVM están conectadas a las funciones del núcleo. Los campos, donde los SVM se usan ampliamente, son biometría, reconocimiento de patrones, etc.
Ventajas
A continuación se presentan algunas de las ventajas de los modelos supervisados de aprendizaje automático:
- El rendimiento de los modelos puede ser optimizado por las experiencias del usuario.
- El aprendizaje supervisado produce resultados utilizando la experiencia previa y también le permite recopilar datos.
- Los algoritmos de aprendizaje automático supervisados se pueden utilizar para implementar una serie de problemas del mundo real.
Desventajas
Las desventajas del aprendizaje supervisado son las siguientes:
- El esfuerzo de entrenar modelos supervisados de aprendizaje automático puede llevar mucho tiempo si el conjunto de datos es más grande.
- La clasificación de big data a veces plantea un desafío mayor.
- Uno puede tener que lidiar con los problemas de sobreajuste.
- Necesitamos muchos buenos ejemplos si queremos que el modelo funcione bien mientras entrenamos al clasificador.
Buenas prácticas al construir modelos de aprendizaje
Es una buena práctica construir modelos de máquinas de aprendizaje supervisadas:
- Antes de construir un buen modelo de aprendizaje automático, se debe realizar el proceso de preprocesamiento de datos.
- Uno debe decidir el algoritmo que mejor se adapte a un problema dado.
- Necesitamos decidir qué tipo de datos se utilizarán para el conjunto de capacitación.
- Necesita decidir sobre la estructura del algoritmo y la función.
Conclusión
En nuestro artículo, hemos aprendido qué es el aprendizaje supervisado y vimos que aquí entrenamos el modelo utilizando datos etiquetados. Luego pasamos al funcionamiento de los modelos y sus diferentes tipos. Finalmente vimos las ventajas y desventajas de estos algoritmos supervisados de aprendizaje automático.
Artículos recomendados
Esta es una guía de lo que es el aprendizaje supervisado. Aquí discutimos los conceptos, cómo funciona, los tipos, las ventajas y las desventajas del aprendizaje supervisado. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- ¿Qué es el aprendizaje profundo?
- Aprendizaje supervisado vs Aprendizaje profundo
- ¿Qué es la sincronización en Java?
- ¿Qué es el alojamiento web?
- Formas de crear un árbol de decisión con ventajas
- Regresión polinómica | Usos y características