
Introducción a la arquitectura de la colmena
Hive Architecture está construida sobre el ecosistema Hadoop. La colmena con frecuencia tiene interacciones con el Hadoop. Apache Hive hace frente tanto al sistema de base de datos SQL del dominio como a Map-reduce. Las aplicaciones de Hive se pueden escribir en varios lenguajes como Java, Python. La arquitectura de colmena muestra cómo escribir el lenguaje de consulta de colmena y cómo se realizan las interacciones entre el programador mediante la interfaz de línea de comandos. El lenguaje de consulta de Hive hace el trabajo de convertir todas las tareas del clúster de Hadoop a través de map-reduce. Como todos sabíamos, Hadoop procesaba big data en un entorno distribuido y formaba un marco de código abierto. Con Hive, es flexible para administrar y ejecutar la consulta y un buen soporte para realizar funciones como encapsulación, consultas ad-hoc. Este artículo proporciona una breve introducción a la arquitectura de la colmena que reside en la capa de Hadoop para realizar resúmenes en big data.
Arquitectura de colmena con sus componentes
Hive desempeña un papel importante en el análisis de datos y la integración de inteligencia empresarial y admite formatos de archivo como archivo de texto, archivo rc. Hive usa un sistema distribuido para procesar y ejecutar consultas y el almacenamiento finalmente se realiza en el disco y finalmente se procesa utilizando un marco de reducción de mapas. Resuelve el problema de optimización que se encuentra en map-reduce y la colmena realiza trabajos por lotes que se explican claramente en el flujo de trabajo. Aquí una tienda meta almacena información de esquema. Un marco llamado Apache Tez está diseñado para el rendimiento de consultas en tiempo real.
Los componentes principales de la colmena se dan a continuación:
- Clientes de la colmena
- Servicios de colmena
- Almacenamiento de colmena (Meta almacenamiento)
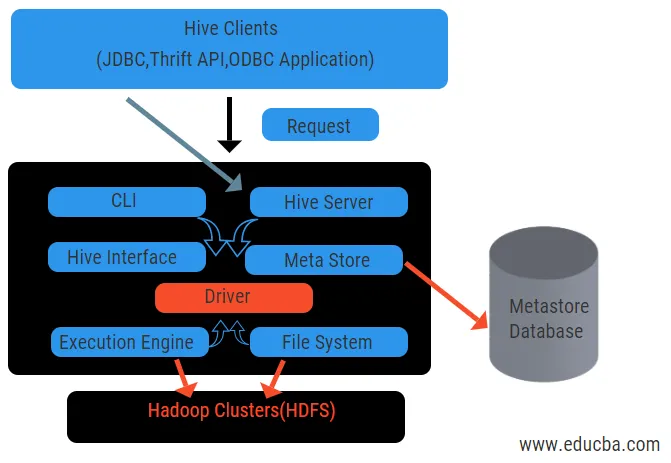
El diagrama anterior muestra la arquitectura de la colmena y sus elementos componentes.
Clientes de la colmena:
Incluyen la aplicación Thrift para ejecutar comandos de colmena fáciles que están disponibles para python, ruby, C ++ y controladores. Estos beneficios de la aplicación cliente para ejecutar consultas en la colmena. Hive tiene tres tipos de categorización de clientes: clientes de segunda mano, clientes JDBC y ODBC.
Servicios de colmena:
Para procesar todas las consultas colmena tiene varios servicios. Todas las funciones son fácilmente definidas por el usuario en la colmena. Veamos todos esos servicios en breve:
- Interfaz de línea de comandos ( interfaz de usuario): permite la interacción entre el usuario y la colmena, un shell predeterminado. Proporciona una GUI para ejecutar la línea de comando de la colmena y la información de la colmena. También podemos utilizar interfaces web (HWI) para enviar consultas e interacciones con un navegador web.
- Controlador de Hive: recibe consultas de diferentes fuentes y clientes como el servidor de segunda mano y almacena y recupera en el controlador ODBC y JDBC que se conectan automáticamente a la colmena. Este componente realiza un análisis semántico al ver las tablas del metastore que analiza una consulta. El controlador toma la ayuda del compilador y realiza funciones como un analizador, planificador, ejecución de trabajos MapReduce y optimizador.
- Compilador: el compilador realiza el análisis y el proceso semántico de la consulta. Convierte la consulta en un árbol de sintaxis abstracta y nuevamente en DAG por compatibilidad. El optimizador, a su vez, divide las tareas disponibles. El trabajo del ejecutor es ejecutar las tareas y monitorear el programa de canalización de las tareas.
- Motor de ejecución: todas las consultas son procesadas por un motor de ejecución. El motor ejecuta los planes de una etapa DAG y ayuda a gestionar las dependencias entre las etapas disponibles y ejecutarlas en un componente correcto.
- Metastore: actúa como un repositorio central para almacenar toda la información estructurada de metadatos, también es una parte importante del aspecto de la colmena ya que tiene información como tablas y detalles de particiones y el almacenamiento de archivos HDFS. En otras palabras, diremos que metastore actúa como un espacio de nombres para tablas. Metastore se considera una base de datos separada que también es compartida por otros componentes. Metastore tiene dos piezas llamadas servicio y almacenamiento atrasado.
El modelo de datos de la colmena está estructurado en particiones, cubos, tablas. Todos estos se pueden filtrar, tener claves de partición y evaluar la consulta. La consulta de Hive funciona en el marco de Hadoop, no en la base de datos tradicional. El servidor de la colmena es una interfaz entre las consultas de un cliente remoto a la colmena. El motor de ejecución está completamente integrado en un servidor de la colmena. Puede encontrar aplicaciones de colmena en aprendizaje automático, inteligencia empresarial en el proceso de detección.
Flujo de trabajo de la colmena:
Hive funciona en dos tipos de modos: modo interactivo y modo no interactivo. El modo anterior permite que todos los comandos de la colmena vayan directamente al shell de la colmena mientras que el tipo posterior ejecuta el código en modo consola. Los datos se dividen en particiones que se dividen en cubos. Los planes de ejecución se basan en la agregación y el sesgo de datos. Una ventaja adicional de usar Hive es que procesa fácilmente una gran escala de información y tiene más interfaces de usuario.
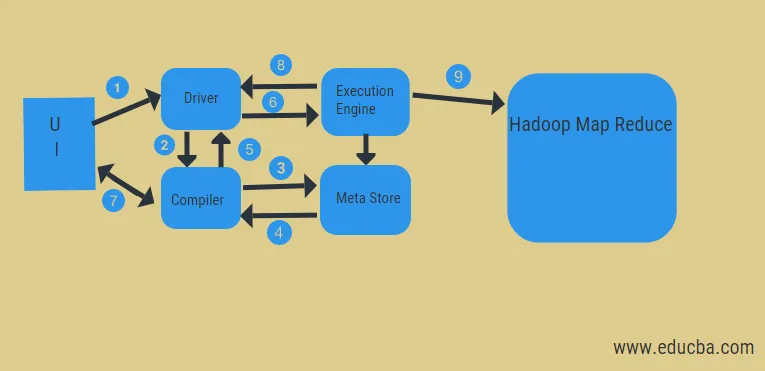
En el diagrama anterior, podemos ver el flujo de datos en la colmena con el sistema Hadoop.
Los pasos incluyen:
- ejecutar la consulta desde la interfaz de usuario
- obtener un plan de las tareas del conductor etapas DAG
- obtener solicitud de metadatos de la tienda meta
- enviar metadatos desde el compilador
- devolver el plan al conductor
- Ejecutar plan en el motor de ejecución
- obtener resultados para la consulta de usuario adecuada
- enviando resultados bidireccionalmente
- Procesamiento del motor de ejecución en HDFS con los resultados de reducción y asignación de mapas de los nodos de datos creados por el rastreador de trabajos. Actúa como un conector entre Hive y Hadoop.
El trabajo del motor de ejecución es comunicarse con los nodos para obtener la información almacenada en la tabla. Aquí se realizan operaciones SQL como crear, soltar, alterar para acceder a la tabla.
Conclusión:
Hemos pasado por Hive Architecture y su flujo de trabajo, la colmena básicamente realiza una cantidad de datos de petabytes y, por lo tanto, es un paquete de almacenamiento de datos en la plataforma Hadoop. Como colmena es una buena opción para manejar un gran volumen de datos, ayuda en la preparación de datos con la guía de la interfaz SQL para resolver los problemas de MapReduce. Apache Hive es una herramienta ETL para procesar datos estructurados. Conocer el funcionamiento de la arquitectura de la colmena ayuda a las personas corporativas a comprender el principio de funcionamiento de la colmena y tiene un buen comienzo con la programación de la colmena.
Artículos recomendados:
Esta ha sido una guía para la arquitectura de la colmena. Aquí discutimos la arquitectura de la colmena, los diferentes componentes y el flujo de trabajo de la colmena. También puede consultar los siguientes artículos para obtener más información.
- Arquitectura Hadoop
- Usos de rubí
- ¿Qué es C ++?
- ¿Qué es la base de datos MySQL?
- Orden de la colmena por