

Diferencia entre Big Data y Apache Hadoop
Todo está en internet. Internet tiene muchos datos. Por lo tanto, todo es Big Data. ¿Sabes que los datos de 2.5 quintillones de bytes se crean todos los días y se acumulan como Big Data? Nuestras actividades diarias como comentarios, me gusta, publicaciones, etc. en las redes sociales como Facebook, LinkedIn, Twitter e Instagram se suman como Big Data. Se supone que para el año 2020 se crearán casi 1, 7 megabytes de datos por segundo, para cada persona en la tierra. Puede imaginar y considerar cuántos datos se generan asumiendo cada persona en la tierra. Hoy estamos conectados y compartimos nuestras vidas en línea. La mayoría de nosotros estamos conectados en línea. Vivimos en una casa inteligente y utilizamos vehículos inteligentes y todos están conectados a nuestros teléfonos inteligentes. ¿Alguna vez imaginaste cómo estos dispositivos se están volviendo inteligentes? Me gustaría darle una respuesta muy simple, es por analizar la gran cantidad de datos, es decir, Big Data. Dentro de cinco años habrá más de 50 mil millones de dispositivos inteligentes conectados en el mundo, todos desarrollados para recopilar, analizar y compartir datos para que nuestras vidas sean más cómodas.
Las siguientes son las introducciones de Big Data vs Apache Hadoop
Presentación del término Big Data
¿Qué es el Big Data? ¿Qué tamaño de datos se considera grande y se denominará Big Data? Tenemos muchos supuestos relativos para el término Big Data. Es posible que la cantidad de datos digamos que 50 terabytes se puedan considerar como grandes datos para las empresas de nueva creación, pero puede no ser Big Data para compañías como Google y Facebook. Es porque tienen la infraestructura para almacenar y procesar esa cantidad de datos. Me gustaría definir el término Big Data como:
- Big Data es la cantidad de datos más allá de la capacidad de la tecnología para almacenar, administrar y procesar de manera eficiente.
- Big Data son datos cuya escala, diversidad y complejidad requieren una nueva arquitectura, técnicas, algoritmos y análisis para administrarlo y extraer valor y conocimiento oculto de él.
- Big data son activos de información de gran volumen, alta velocidad y gran variedad que exigen formas rentables e innovadoras de procesamiento de información que permitan una mejor comprensión, toma de decisiones y automatización de procesos.
- Big Data se refiere a tecnologías e iniciativas que involucran datos que son demasiado diversos, de cambio rápido o masivos para que las tecnologías, habilidades e infraestructura convencionales puedan abordarse de manera eficiente. Dicho de otra manera, el volumen, la velocidad o la variedad de datos es demasiado grande.
3 V de Big Data
- Volumen: El volumen se refiere a la cantidad / cantidad a la que se crean los datos, como Cada hora, las transacciones de los clientes de Wal-Mart proporcionan a la empresa aproximadamente 2.5 petabytes de datos.
- Velocidad: la velocidad se refiere a la velocidad a la que se mueven los datos, como los usuarios de Facebook envían un promedio de 31.25 millones de mensajes y ven 2.77 millones de videos por minuto todos los días a través de Internet.
- Variedad: Variedad se refiere a diferentes formatos de datos que se crean como datos estructurados, semiestructurados y no estructurados. Al igual que el envío de correos electrónicos con el archivo adjunto en Gmail son datos no estructurados, mientras que publicar cualquier comentario con algunos enlaces externos también se denomina datos no estructurados. Compartir imágenes, clips de audio, videoclips son una forma de datos no estructurada.
Almacenar y procesar este gran volumen, velocidad y variedad de datos es un gran problema. Necesitamos pensar en otra tecnología que no sea RDBMS para Big Data. Esto se debe a que RDBMS es capaz de almacenar y procesar solo datos estructurados. Así que aquí Apache Hadoop viene como un rescate.
Presentación del término Apache Hadoop
Apache Hadoop es un marco de software de código abierto para almacenar datos y ejecutar aplicaciones en clústeres de hardware básico. Apache Hadoop es un marco de software que permite el procesamiento distribuido de grandes conjuntos de datos en grupos de computadoras utilizando modelos de programación simples. Está diseñado para escalar desde servidores individuales hasta miles de máquinas, cada una de las cuales ofrece computación y almacenamiento local. Apache Hadoop es un marco para almacenar y procesar Big Data. Apache Hadoop es capaz de almacenar y procesar todos los formatos de datos, como datos estructurados, semiestructurados y no estructurados. Apache Hadoop es de código abierto y el hardware básico trajo la revolución a la industria de TI. Es fácilmente accesible para todos los niveles de empresas. No necesitan invertir más para configurar el clúster de Hadoop y en diferentes infraestructuras. Entonces, veamos la diferencia útil entre Big Data y Apache Hadoop en detalle en esta publicación.
Marco de Apache Hadoop
El framework Apache Hadoop se divide en dos partes:
- Sistema de archivos distribuidos de Hadoop (HDFS): esta capa es responsable del almacenamiento de datos.
- MapReduce: esta capa es responsable del procesamiento de datos en Hadoop Cluster.
Hadoop Framework se divide en arquitectura maestra y esclava. El nodo de nombre de capa del sistema de archivos distribuidos de Hadoop (HDFS) es el componente maestro mientras que el nodo de datos es el componente esclavo mientras que en la capa MapReduce Job Tracker es el componente maestro mientras que el rastreador de tareas es el componente esclavo. A continuación se muestra el diagrama del marco Apache Hadoop.
¿Por qué es importante Apache Hadoop?
- Capacidad para almacenar y procesar grandes cantidades de cualquier tipo de datos, rápidamente
- Poder de cómputo: el modelo de cómputo distribuido de Hadoop procesa big data rápidamente. Cuantos más nodos informáticos use, más potencia de procesamiento tendrá.
- Tolerancia a fallas: el procesamiento de datos y aplicaciones está protegido contra fallas de hardware. Si un nodo se cae, los trabajos se redirigen automáticamente a otros nodos para asegurarse de que la informática distribuida no falle. Múltiples copias de todos los datos se almacenan automáticamente.
- Flexibilidad: puede almacenar tantos datos como desee y decidir cómo usarlos más adelante. Eso incluye datos no estructurados como texto, imágenes y videos.
- Bajo costo: el marco de código abierto es gratuito y utiliza hardware básico para almacenar grandes cantidades de datos.
- Escalabilidad: puede hacer crecer fácilmente su sistema para manejar más datos simplemente agregando nodos. Se requiere poca administración
Comparación cara a cara entre Big Data y Apache Hadoop (infografía)
A continuación se muestra la comparación de los 4 principales entre Big Data y Apache Hadoop
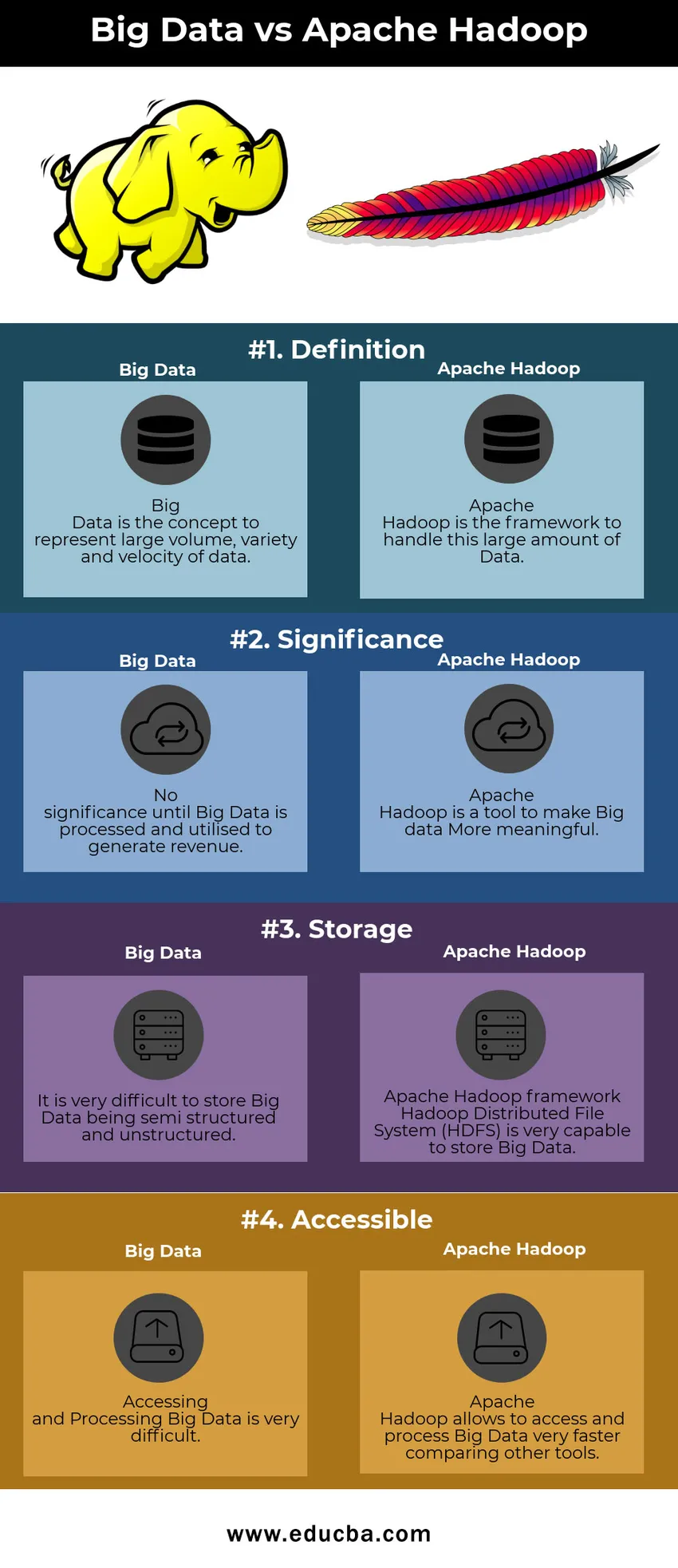
Tabla comparativa Big Data vs Apache Hadoop
Estoy discutiendo los principales artefactos y distinguiendo entre Big Data y Apache Hadoop
| Big Data | Apache Hadoop | |
| Definición | Big Data es el concepto que representa un gran volumen, variedad y velocidad de datos. | Apache Hadoop es el marco para manejar esta gran cantidad de datos |
| Significado | No tiene importancia hasta que Big Data sea procesado y utilizado para generar ingresos | Apache Hadoop es una herramienta para hacer que Big Data sea más significativo |
| Almacenamiento | Es muy difícil almacenar Big Data siendo semiestructurado y desestructurado | El marco de Apache Hadoop Hadoop Distributed File System (HDFS) es muy capaz de almacenar Big Data |
| Accesible | Acceder y procesar Big Data es muy difícil | Apache Hadoop permite acceder y procesar Big Data muy rápidamente comparando otras herramientas |
Conclusión: Big Data vs Apache Hadoop
No puede comparar Big Data y Apache Hadoop. Esto se debe a que Big Data es un problema, mientras que Apache Hadoop es una solución. Dado que la cantidad de datos aumenta exponencialmente en todos los sectores, es muy difícil almacenar y procesar datos desde un solo sistema. Entonces, para procesar esta gran cantidad de datos, necesitamos procesamiento distribuido y almacenamiento de datos. Por lo tanto, Apache Hadoop presenta la solución de almacenar y procesar una gran cantidad de datos. Finalmente, concluiré que Big Data es una gran cantidad de datos complejos, mientras que Apache Hadoop es un mecanismo para almacenar y procesar Big Data de manera muy eficiente y sin problemas.
Artículo recomendado
Esta ha sido una guía de Big Data vs Apache Hadoop, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. Este artículo consta de todas las diferencias útiles entre Big Data y Apache Hadoop. También puede consultar los siguientes artículos para obtener más información:
- Big Data vs Data Science: ¿en qué se diferencian?
- Las 5 principales tendencias de Big Data que las empresas tendrán que dominar
- Hadoop vs Apache Spark: cosas interesantes que debes saber
- Apache Hadoop vs Apache Spark | ¡Las 10 mejores comparaciones que debes conocer!