

Diferencia entre Hadoop y HBase
Hadoop es un marco de Java de código abierto, utilizado para administrar y procesar una gran cantidad de datos estructurados y no estructurados. Hadoop es masivamente escalable, por lo tanto, se utiliza para procesar cargas de trabajo de Big data. Los grandes datos se almacenan, acceden y procesan en el clúster confiable y expandible. HBase (Hadoop Database) es una base de datos no relacional y no solo SQL, es decir, NoSQL que se ejecuta en la parte superior de Hadoop como un almacén de big data distribuido y escalable. Es una base de datos de código abierto en la que los datos se almacenan en forma de filas y columnas, en esa celda hay una intersección de columnas y filas.
A continuación se muestran los componentes principales de la arquitectura Hadoop:
- Sistema de archivos distribuidos de Hadoop (HDFS): Hadoop incluye un sistema de almacenamiento distribuido, el Sistema de archivos distribuidos de Hadoop (HDFS). HDFS es la arquitectura maestro-esclavo que almacena datos en todo el clúster. Datos distribuidos en varios nodos esclavos por el nodo maestro en el bloque de formulario. El nodo maestro se llama Namenode y los nodos esclavos se llaman Datanode. HDFS es fácilmente expandible y almacena una gran cantidad de datos en Datanodes. HDFS tiene un factor de replicación configurable con valor predeterminado 3 que puede ser editable.
- MapReduce: MapReduce es un paradigma de programación, procesa en paralelo en una gran cantidad de conjuntos de datos a través de la red. MapReduce se refiere a dos tareas diferentes: mapear los datos de entrada en los que los datos divididos en un subconjunto de datos llamados tuplas y la tarea de reducción toman estas tuplas del mapa como entrada y se combinan para formar la salida del original.
- Yarn: YARN es sinónimo de otro navegador de recursos que maneja recursos informáticos como la CPU y la memoria, la programación de solicitudes de recursos.
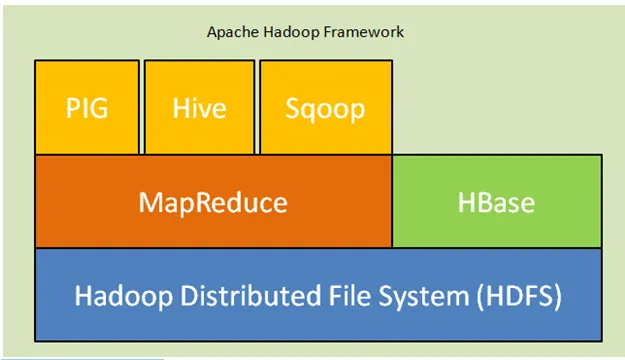
Fig. Marco de Apache Hadoop
El servidor de región sirve datos para operaciones de lectura / escritura. Todos los datos de HBase se almacenan en el archivo HDFS. El HDFS Datanode almacena los datos que administra el servidor de región. HDFS Namenode mantiene información de metadatos para todos los bloques de datos físicos que comprenden los archivos.
El control de versiones se utiliza para realizar un seguimiento de los cambios de celda, lo que mantiene el seguimiento de la versión del contenido. De ahí se puede recuperar cualquier versión de contenido. Cada valor de celda incluye el atributo 'versión' con respecto a la marca de tiempo para recuperar la celda. Cada valor en el mapa es una matriz ininterrumpida de bytes. El mapa está indexado por una clave de fila, una clave de columna y una marca de tiempo. La arquitectura de HBase es mapas altamente escalables, dispersos, distribuidos, persistentes y multidimensionales.
Comparación cabeza a cabeza entre Hadoop y HBase (infografía)
A continuación se muestra la diferencia entre los 7 principales entre Hadoop y HBase
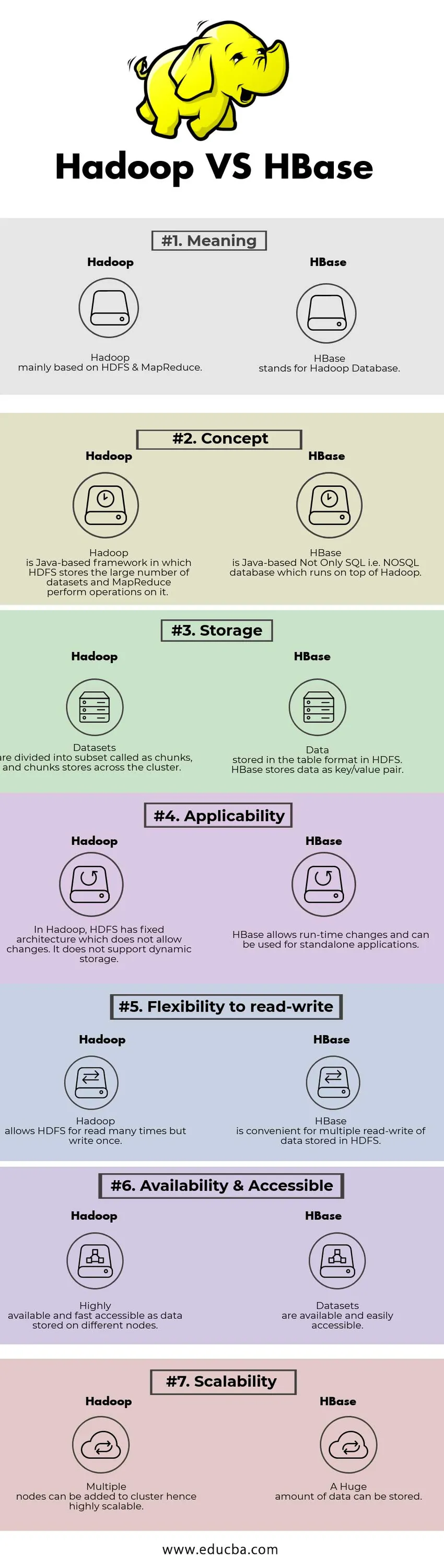
Diferencias clave entre Hadoop y HBase
La diferencia entre Hadoop y HBase se explica en los puntos presentados a continuación:
- Hadoop no es adecuado para el procesamiento analítico en línea (OLAP) y HBase es parte del ecosistema Hadoop que proporciona acceso aleatorio en tiempo real (lectura / escritura) a los datos en el sistema de archivos Hadoop.
- Hadoop Framework es tolerante a fallas por diseño y admite la transferencia rápida de datos entre nodos incluso durante fallas del sistema. HBase es una base de datos no relacional y de código abierto No solo SQL que se ejecuta sobre Hadoop. HBase viene bajo el tipo de teorema CAP (consistencia, disponibilidad y tolerancia de partición).
- Hadoop es el más adecuado para realizar análisis por lotes. Sin embargo, uno de sus mayores inconvenientes es su incapacidad para realizar análisis en tiempo real, el requisito de tendencia de la industria de TI. HBase, por otro lado, puede manejar grandes conjuntos de datos y no es apropiado para el análisis por lotes. En cambio, se usa para escribir / leer datos de Hadoop en tiempo real.
- Tanto Hadoop como HBase son capaces de procesar datos estructurados, semiestructurados y no estructurados. En Hadoop, HDFS carece de un motor de procesamiento en memoria que desacelere el proceso de análisis de datos; ya que está usando el viejo MapReduce para hacerlo. HBase, por el contrario, se jacta de un motor de procesamiento en memoria que aumenta drásticamente la velocidad de lectura / escritura.
- Hadoop es muy transparente en su ejecución de análisis de datos. HBase, por otro lado, al ser una base de datos NoSQL en formato tabular, obtiene valores al ordenarlos bajo diferentes valores clave.
Tabla de comparación de Hadoop vs HBase
| BASE DE COMPARACIÓN | Hadoop | HBase |
| Sentido | Hadoop se basa principalmente en HDFS y MapReduce. | HBase significa Hadoop Database. |
| Concepto | Hadoop es un marco basado en Java en el que HDFS almacena la gran cantidad de conjuntos de datos y MapReduce realiza operaciones en él. | HBase está basado en Java, no solo SQL, es decir, la base de datos NoSQL que se ejecuta sobre Hadoop. |
| Almacenamiento | Los conjuntos de datos se dividen en subconjuntos llamados trozos, y los trozos se almacenan en todo el clúster. | Datos almacenados en el formato de tabla en HDFS. HBase almacena datos como par clave / valor. |
| Aplicabilidad | En Hadoop, HDFS tiene una arquitectura fija que no permite cambios. No es compatible con el almacenamiento dinámico. | HBase permite cambios en el tiempo de ejecución y se puede usar para aplicaciones independientes. |
| Flexibilidad para leer y escribir | Hadoop permite HDFS para leer muchas veces pero escribir una vez. | HBase es conveniente para la lectura y escritura múltiple de datos almacenados en HDFS |
| Disponibilidad y Accesible | Altamente disponible y de rápido acceso como datos almacenados en diferentes nodos. | Los conjuntos de datos están disponibles y son fácilmente accesibles. |
| Escalabilidad | Se pueden agregar varios nodos al clúster, por lo tanto, altamente escalables. | Se puede almacenar una gran cantidad de datos. |
Conclusión: Hadoop vs HBase
Arquitectura de Hadoop basada principalmente en HDFS y MapReduce. HBase es el componente de soporte en el sistema Hadoop. HBase es capaz de alojar grandes tablas y proporcionar acceso aleatorio rápido a los datos disponibles, mientras que HDFS es adecuado para almacenar archivos grandes. Tanto Hadoop como HBase brindan un acceso rápido a los datos, pero con HBase se pueden realizar operaciones de lectura / escritura y para HDFS leer muchas veces y una vez que se puede escribir. Este artículo describió una comprensión de Hadoop y HBase, destacó brevemente las características y las comparó sabiamente.
Artículo recomendado
- Apache Hadoop vs Apache Spark | ¡Las 10 mejores comparaciones que debes conocer!
- Hadoop vs Hive - Descubre las mejores diferencias
- HBase vs Cassandra - Cuál es mejor (infografía)
- Top 12 Comparación de Apache Hive vs Apache HBase (Infografía)
- Hadoop vs Spark: ¿Cuáles son las características?