

Introducción al algoritmo del árbol de decisión
Cuando tenemos que resolver un problema que es un problema de clasificación o de regresión, el algoritmo del árbol de decisión es uno de los algoritmos más populares utilizados para construir los modelos de clasificación y regresión. Se incluyen en la categoría de aprendizaje supervisado, es decir, datos etiquetados.
¿Qué es el algoritmo de árbol de decisión?
El algoritmo de árbol de decisión es un algoritmo supervisado de aprendizaje automático en el que los datos se dividen continuamente en cada fila según ciertas reglas hasta que se genera el resultado final. Tomemos un ejemplo, supongamos que abre un centro comercial y, por supuesto, desea que crezca en el negocio con el tiempo. Por lo tanto, necesitaría clientes que regresen más clientes nuevos en su centro comercial. Para ello, prepararía diferentes estrategias comerciales y de marketing, como enviar correos electrónicos a clientes potenciales; crear ofertas y ofertas, dirigidas a nuevos clientes, etc. Pero, ¿cómo sabemos quiénes son los clientes potenciales? En otras palabras, ¿cómo clasificamos la categoría de los clientes? Como algunos clientes visitarán una vez en una semana y a otros les gustaría visitar una o dos veces en un mes, o algunos visitarán en un trimestre. Por lo tanto, los árboles de decisión son uno de esos algoritmos de clasificación que clasificarán los resultados en grupos hasta que no quede más similitud.
De esta manera, el árbol de decisión se cae en un formato estructurado en árbol. Los componentes principales de un árbol de decisión son:
- Los nodos de decisión, que es donde se dividen o dicen los datos, es un lugar para el atributo.
- Enlace de decisión, que representa una regla.
- Hojas de decisión, que son los resultados finales.

Trabajo de un algoritmo de árbol de decisión
Hay muchos pasos involucrados en el funcionamiento de un árbol de decisión:
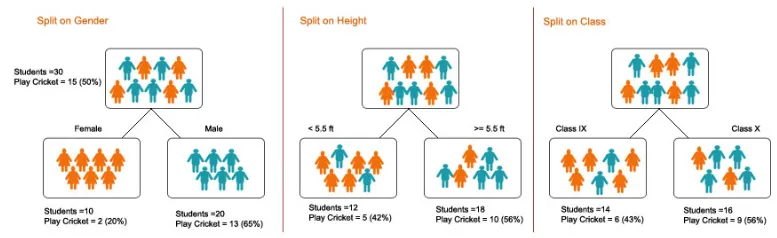
1. División : es el proceso de partición de datos en subconjuntos. La división se puede realizar en varios factores como se muestra a continuación, es decir, en función del género, la altura o la clase.
2. Poda : es el proceso de acortar las ramas del árbol de decisión, lo que limita la profundidad del árbol.
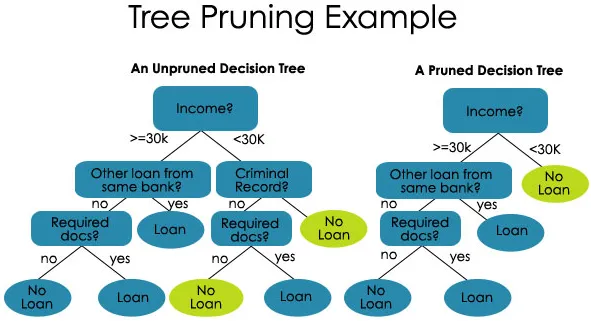
La poda también es de dos tipos:
- Poda previa : aquí dejamos de hacer crecer el árbol cuando no encontramos ninguna asociación estadísticamente significativa entre los atributos y la clase en ningún nodo en particular.
- Post-poda : para publicar la poda, debemos validar el rendimiento del modelo del conjunto de prueba y luego cortar las ramas que son el resultado del ruido de ajuste excesivo del conjunto de entrenamiento.
3. Selección de árbol : el tercer paso es el proceso de encontrar el árbol más pequeño que se ajuste a los datos.
Ejemplos e ilustración de la construcción de un árbol de decisión
Ahora, como hemos aprendido los principios de un árbol de decisión. Comprendamos e ilustremos esto con la ayuda de un ejemplo.
Digamos que quieres jugar al cricket en algún día en particular (por ejemplo, el sábado). ¿Cuáles son los factores involucrados que decidirán si la obra va a suceder o no?
Claramente, el factor principal es el clima, ningún otro factor tiene tanta probabilidad como el clima está teniendo para la interrupción del juego.
Hemos recopilado los datos de los últimos 10 días que se presentan a continuación:
| Día | Clima | Temperatura | Humedad | Viento | ¿Jugar? |
| 1 | Nublado | Caliente | Alto | Débiles | si |
| 2 | Soleado | Caliente | Alto | Débiles | No |
| 3 | Soleado | Templado | Normal | Fuerte | si |
| 4 4 | Lluvioso | Templado | Alto | Fuerte | No |
| 5 5 | Nublado | Templado | Alto | Fuerte | si |
| 6 6 | Lluvioso | Frio | Normal | Fuerte | No |
| 7 7 | Lluvioso | Templado | Alto | Débiles | si |
| 8 | Soleado | Caliente | Alto | Fuerte | No |
| 9 9 | Nublado | Caliente | Normal | Débiles | si |
| 10 | Lluvioso | Templado | Alto | Fuerte | No |
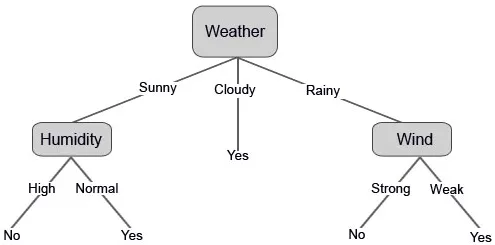
Ahora construyamos nuestro árbol de decisión basado en los datos que tenemos. Así que hemos dividido el árbol de decisión en dos niveles, el primero se basa en el atributo "Tiempo" y la segunda fila se basa en "Humedad" y "Viento". Las siguientes imágenes ilustran un árbol de decisión aprendido.
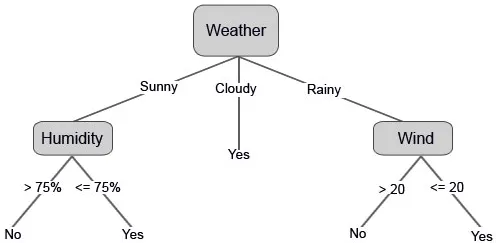
También podemos establecer algunos valores de umbral si las características son continuas.
¿Qué es la entropía en el algoritmo del árbol de decisión?
En palabras simples, la entropía es la medida de cuán desordenados son sus datos. Si bien es posible que haya escuchado este término en sus clases de Matemáticas o Física, aquí es lo mismo.
La razón por la que se utiliza Entropía en el árbol de decisión es porque el objetivo final en el árbol de decisión es agrupar grupos de datos similares en clases similares, es decir, ordenar los datos.
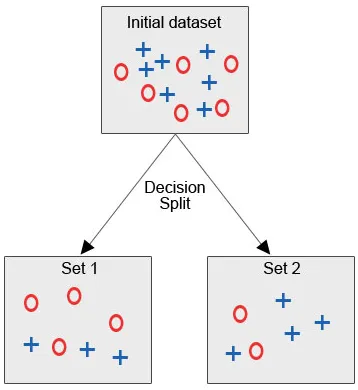
Veamos la imagen a continuación, donde tenemos el conjunto de datos inicial y estamos obligados a aplicar el algoritmo del árbol de decisión para agrupar los puntos de datos similares en una categoría.
Después de la división de la decisión, como podemos ver claramente, la mayoría de los círculos rojos caen en una clase, mientras que la mayoría de las cruces azules caen en otra clase. Por lo tanto, una decisión fue clasificar los atributos que podrían basarse en varios factores.
Ahora, intentemos hacer algunos cálculos aquí:
Digamos que tenemos conjuntos "N" del elemento y estos elementos se dividen en dos categorías, y ahora para agrupar los datos en función de las etiquetas, presentamos la relación:
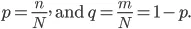
La entropía de nuestro conjunto viene dada por la siguiente ecuación:
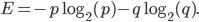
Veamos el gráfico para la ecuación dada:
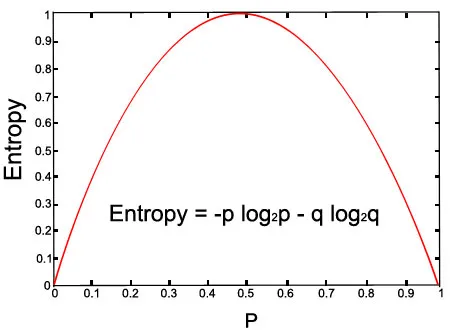
Imagen de arriba (con p = 0.5 y q = 0.5)
Ventajas
1. Un árbol de decisión es simple de entender y una vez que se entiende, podemos construirlo.
2. Podemos implementar un árbol de decisión en datos numéricos y categóricos.
3. Se ha demostrado que el Árbol de decisión es un modelo robusto con resultados prometedores.
4. También son eficientes en tiempo con grandes datos.
5. Requiere menos esfuerzo para el entrenamiento de los datos.
Desventajas
1. Inestabilidad : solo si la información es precisa y precisa, el árbol de decisión arrojará resultados prometedores. Incluso si hay un ligero cambio en los datos de entrada, puede causar grandes cambios en el árbol.
2. Complejidad : si el conjunto de datos es enorme con muchas columnas y filas, es una tarea muy compleja diseñar un árbol de decisión con muchas ramas.
3. Costos : a veces el costo también sigue siendo un factor principal porque cuando se requiere construir un árbol de decisión complejo, se requiere un conocimiento avanzado en análisis cuantitativo y estadístico.
Conclusión
En este artículo, aprendimos sobre el algoritmo del árbol de decisión y cómo construir uno. También vimos el gran papel que desempeña Entropy en el algoritmo del árbol de decisión y, finalmente, vimos las ventajas y desventajas del árbol de decisión.
Artículos recomendados
Esta ha sido una guía para el algoritmo del árbol de decisión. Aquí discutimos el papel desempeñado por la entropía, el trabajo, las ventajas y las desventajas. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Métodos importantes de minería de datos
- ¿Qué es la aplicación web?
- Guía de ¿Qué es la ciencia de datos?
- Preguntas de la entrevista del analista de datos
- Aplicación del árbol de decisión en minería de datos