

Introducción a la minería de datos
Este es un método de minería de datos utilizado para colocar elementos de datos en sus grupos similares. Cluster es el procedimiento de dividir objetos de datos en subclases. La calidad de la agrupación depende del método que utilizamos. La agrupación también se denomina segmentación de datos, ya que los grandes grupos de datos se dividen por su similitud.
¿Qué es la agrupación en minería de datos?
La agrupación es la agrupación de objetos específicos en función de sus características y similitudes. En cuanto a la minería de datos, esta metodología divide los datos que mejor se adaptan al análisis deseado utilizando un algoritmo de unión especial. Este análisis permite que un objeto no sea parte o estrictamente parte de un clúster, lo que se denomina partición dura de este tipo. Sin embargo, las particiones suaves sugieren que cada objeto en el mismo grado pertenece a un grupo. Se pueden crear divisiones más específicas como objetos de múltiples grupos, se puede obligar a un solo grupo a participar o incluso se pueden construir árboles jerárquicos en las relaciones grupales. Este sistema de archivos se puede implementar de diferentes maneras en función de varios modelos. Estos algoritmos distintos se aplican a todos y cada uno de los modelos, distinguiendo sus propiedades y sus resultados. Un buen algoritmo de agrupación es capaz de identificar el grupo independientemente de la forma del grupo. Hay 3 etapas básicas del algoritmo de agrupamiento que se muestran a continuación
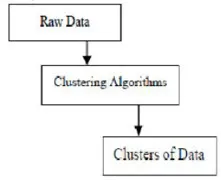
Algoritmos de agrupamiento en minería de datos
Dependiendo de los modelos de clúster descritos recientemente, se pueden usar muchos clústeres para dividir la información en un conjunto de datos. Debe decirse que cada método tiene sus propias ventajas y desventajas. La selección de un algoritmo depende de las propiedades y la naturaleza del conjunto de datos.
Los métodos de agrupamiento para la minería de datos se pueden mostrar a continuación
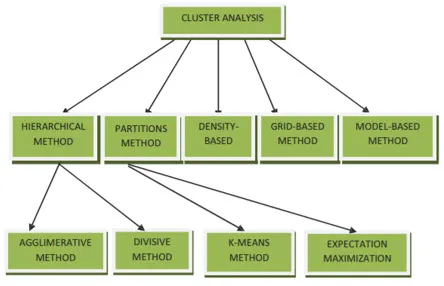
- Método basado en particiones
- Método basado en la densidad
- Método basado en centroides
- Método jerárquico
- Método basado en cuadrícula
- Método basado en modelo
1. Método basado en particiones
El algoritmo de partición divide los datos en muchos subconjuntos.
Supongamos que el algoritmo de partición crea una partición de datos, ya que k y n son objetos presentes en la base de datos. Por lo tanto, cada partición se representará como k ≤ n.
Esto da una idea de que la clasificación de los datos está en k grupos, que se pueden mostrar a continuación
La Figura 1 muestra los puntos originales en la agrupación

La figura 2 muestra la agrupación de particiones después de aplicar un algoritmo
Esto indica que cada grupo tiene al menos un objeto, y que cada objeto debe pertenecer exactamente a un grupo.
2. Método basado en la densidad
Estos algoritmos producen grupos en una ubicación determinada en función de la alta densidad de los participantes del conjunto de datos. Agrega cierta noción de rango para los miembros del grupo en grupos a un nivel estándar de densidad. Dichos procesos pueden realizar menos en la detección de las áreas de superficie del grupo.
3. Método basado en centroides
Casi todos los grupos están referenciados por un vector de valores en este tipo de técnica de agrupación del sistema operativo. En comparación con otros grupos, cada objeto es parte del grupo con una diferencia mínima de valor. El número de clústeres debe estar predefinido, y este es el mayor problema de algoritmo de este tipo. Esta metodología es la más cercana al tema de identificación y es ampliamente utilizada para problemas de optimización.
4. Método jerárquico
El método creará una descomposición jerárquica de un conjunto dado de objetos de datos. En función de cómo se forma la descomposición jerárquica, podemos clasificar los métodos jerárquicos. Este método se da de la siguiente manera
- Enfoque aglomerativo
- Enfoque divisivo
El enfoque aglomerativo también se conoce como enfoque de botones. Aquí comenzamos con cada objeto que constituye un grupo separado. Continúa fusionando objetos o grupos muy juntos
El enfoque divisivo también se conoce como el enfoque de arriba hacia abajo. Comenzamos con todos los objetos en el mismo grupo. Este método es rígido, es decir, nunca se puede deshacer una vez que se completa una fusión o división
5. Método basado en cuadrícula
Los métodos basados en cuadrícula funcionan en el espacio de objetos en lugar de dividir los datos en una cuadrícula. La cuadrícula se divide en función de las características de los datos. Al usar este método, los datos no numéricos son fáciles de administrar. El orden de los datos no afecta la partición de la cuadrícula. Una ventaja importante de un modelo basado en cuadrícula es que proporciona una velocidad de ejecución más rápida.
Las ventajas de la agrupación jerárquica son las siguientes
- Es aplicable a cualquier tipo de atributo.
- Proporciona flexibilidad relacionada con el nivel de granularidad.
6. Método basado en el modelo
Este método utiliza un modelo hipotético basado en la distribución de probabilidad. Al agrupar la función de densidad, este método localiza los grupos. Refleja la distribución espacial de los puntos de datos.
Aplicación de clustering en Data Mining
La agrupación puede ayudar en muchos campos, como en biología, plantas y animales clasificados por sus propiedades, así como en marketing, la agrupación ayudará a identificar a los clientes de un determinado registro de clientes con conducta similar. En muchas aplicaciones, como la investigación de mercado, el reconocimiento de patrones, el procesamiento de datos e imágenes, el análisis de agrupamiento se utiliza en grandes cantidades. La agrupación también puede ayudar a los anunciantes en su base de clientes a encontrar diferentes grupos. Y sus grupos de clientes pueden definirse mediante patrones de compra. En biología, se usa para la determinación de taxonomías de plantas y animales, para la categorización de genes con funcionalidad similar y para conocer las estructuras inherentes a la población. En una base de datos de observación de la tierra, la agrupación también facilita encontrar áreas de uso similar en la tierra. Ayuda a identificar grupos de casas y apartamentos por tipo, valor y destino de casas. La agrupación de documentos en la web también es útil para el descubrimiento de información. El análisis de clúster es una herramienta para obtener información sobre la distribución de datos para observar las características de cada clúster como una función de minería de datos.
Conclusión
La agrupación es importante en la minería de datos y su análisis. En este artículo, hemos visto cómo se puede realizar la agrupación aplicando varios algoritmos de agrupación y su aplicación en la vida real.
Artículo recomendado
Esta ha sido una guía de Qué es la agrupación en clúster en la minería de datos. Aquí discutimos los conceptos, definición, características, aplicación de Clustering en Data Mining. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- ¿Qué es el procesamiento de datos?
- ¿Cómo convertirse en un analista de datos?
- ¿Qué es la inyección SQL?
- Definición de lo que es SQL Server?
- Descripción general de la arquitectura de minería de datos
- Agrupación en Machine Learning
- Algoritmo de agrupamiento jerárquico
- Agrupación jerárquica | Agrupamiento Aglomerativo y Divisivo