
¿Qué es el algoritmo SVM?
SVM significa Support Vector Machine. SVM es un algoritmo de aprendizaje automático supervisado que se usa comúnmente para desafíos de clasificación y regresión. Las aplicaciones comunes del algoritmo SVM son el sistema de detección de intrusiones, el reconocimiento de escritura a mano, la predicción de la estructura de proteínas, la detección de esteganografía en imágenes digitales, etc.
En el algoritmo SVM, cada punto se representa como un elemento de datos dentro del espacio n-dimensional donde el valor de cada entidad es el valor de una coordenada específica.
Después de trazar, la clasificación se ha llevado a cabo mediante la búsqueda de hipeplanes que diferencian dos clases. Consulte la imagen a continuación para comprender este concepto.
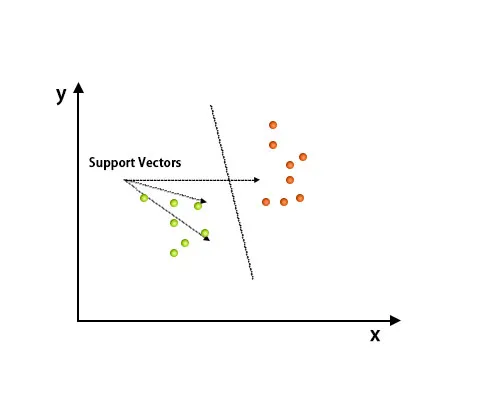
El algoritmo Support Vector Machine se utiliza principalmente para resolver problemas de clasificación. Los vectores de soporte no son más que las coordenadas de cada elemento de datos. Support Vector Machine es una frontera que diferencia dos clases usando hiperplanos.
¿Cómo funciona el algoritmo SVM?
En la sección anterior, hemos discutido la diferenciación de dos clases usando hiper-plano. Ahora veremos cómo funciona realmente este algoritmo SVM.
Escenario 1: Identificar el hiperplano correcto
Aquí hemos tomado tres hiperplanos, es decir, A, B y C. Ahora tenemos que identificar el hiperplano correcto para clasificar la estrella y el círculo.
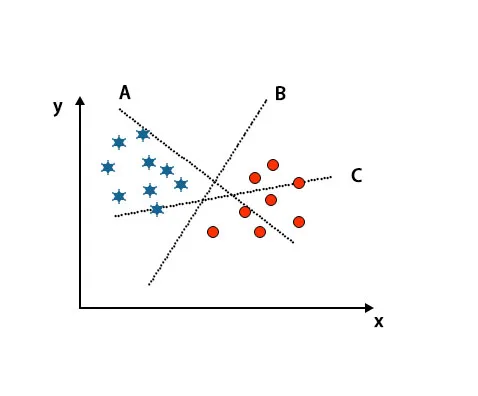
Para identificar el hiperplano correcto, debemos conocer la regla del pulgar. Seleccione el hiperplano que diferencia dos clases. En la imagen mencionada anteriormente, el hiperplano B diferencia muy bien dos clases.
Escenario 2: Identificar el hiperplano correcto
Aquí hemos tomado tres hiperplanos, es decir, A, B y C. Estos tres hiperplanos ya están diferenciando muy bien las clases.
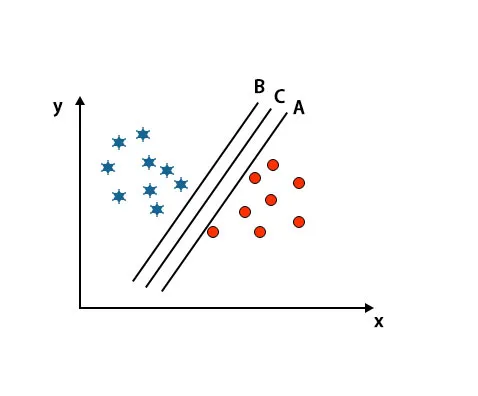
En este escenario, para identificar el hiperplano correcto aumentamos la distancia entre los puntos de datos más cercanos. Esta distancia no es más que un margen. Consulte la imagen a continuación.
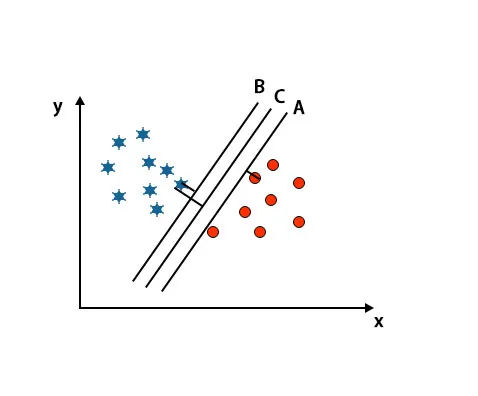
En la imagen mencionada anteriormente, el margen del hiperplano C es más alto que el hiperplano A y el hiperplano B. Entonces, en este escenario, C es el hiperplano correcto. Si elegimos el hiperplano con un margen mínimo, puede conducir a una clasificación errónea. Por lo tanto, elegimos el hiperplano C con margen máximo debido a su robustez.
Escenario 3: Identificar el hiperplano correcto
Nota: Para identificar el hiperplano, siga las mismas reglas que se mencionaron en las secciones anteriores.
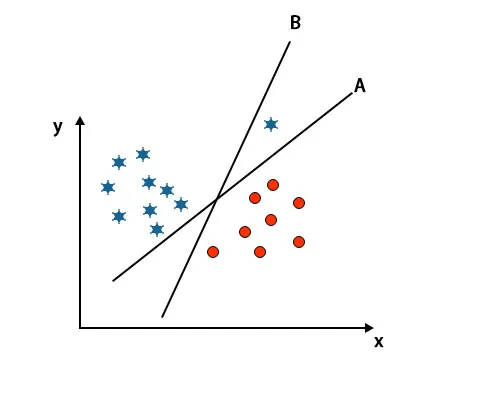
Como puede ver en la imagen mencionada anteriormente, el margen del hiperplano B es mayor que el margen del hiperplano A, por eso algunos seleccionarán el hiperplano B como un derecho. Pero en el algoritmo SVM, selecciona ese hiperplano que clasifica las clases con precisión antes de maximizar el margen. En este escenario, el hiperplano A ha clasificado a todos con precisión y hay algún error con la clasificación del hiperplano B. Por lo tanto, A es el hiperplano correcto.
Escenario 4: clasificar dos clases
Como puede ver en la imagen mencionada a continuación, no podemos diferenciar dos clases usando una línea recta porque una estrella se encuentra como un valor atípico en la otra clase de círculo.
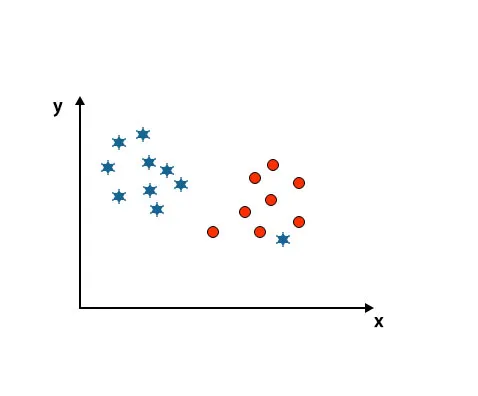
Aquí, una estrella está en otra clase. Para la clase de estrella, esta estrella es el valor atípico. Debido a la propiedad de robustez del algoritmo SVM, encontrará el hiperplano correcto con un margen más alto ignorando un valor atípico.
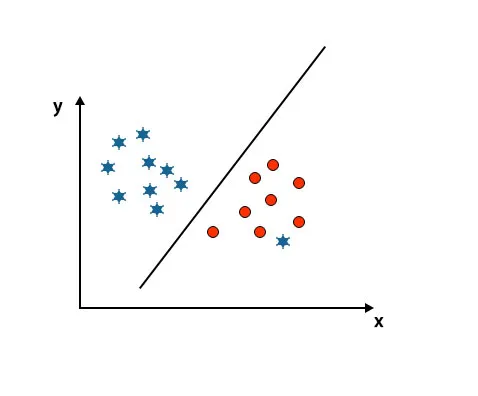
Escenario 5: hiperplano fino para diferenciar clases
Hasta ahora hemos mirado hiper-plano lineal. En la imagen mencionada a continuación, no tenemos un hiperplano lineal entre clases.
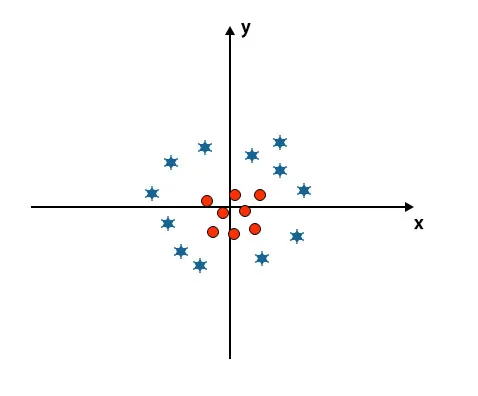
Para clasificar estas clases, SVM presenta algunas características adicionales. En este escenario, vamos a utilizar esta nueva característica z = x 2 + y 2.
Traza todos los puntos de datos en los ejes xy z.

Nota
- Todos los valores en el eje z deben ser positivos porque z es igual a la suma de x al cuadrado e y al cuadrado.
- En el gráfico mencionado anteriormente, los círculos rojos están cerrados al origen del eje x y el eje y, lo que lleva el valor de z a un nivel más bajo y la estrella es exactamente lo opuesto al círculo, está lejos del origen del eje x y eje y, llevando el valor de z a alto.
En el algoritmo SVM, es fácil de clasificar usando hiperplano lineal entre dos clases. Pero la pregunta que surge aquí es si deberíamos agregar esta característica de SVM para identificar el hiperplano. Entonces, la respuesta es no, para resolver este problema SVM tiene una técnica que comúnmente se conoce como truco del núcleo.
El truco del kernel es la función que transforma los datos en una forma adecuada. Hay varios tipos de funciones del núcleo utilizadas en el algoritmo SVM, es decir, polinomial, lineal, no lineal, función de base radial, etc. Aquí, utilizando el truco del núcleo, el espacio de entrada de baja dimensión se convierte en un espacio de mayor dimensión.
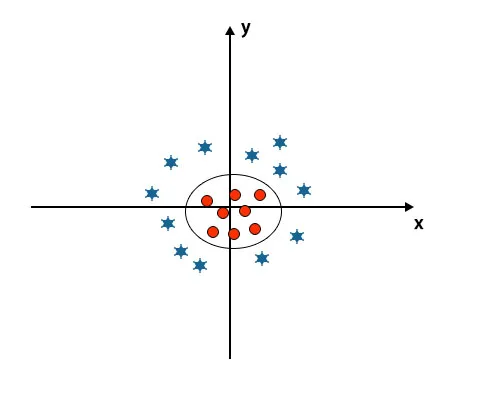
Cuando miramos el hiperplano el origen del eje y el eje y, se ve como un círculo. Consulte la imagen a continuación.
Pros del algoritmo SVM
- Incluso si los datos de entrada no son lineales ni separables, los SVM generan resultados de clasificación precisos debido a su solidez.
- En la función de decisión, utiliza un subconjunto de puntos de entrenamiento llamados vectores de soporte, por lo tanto, es eficiente en memoria.
- Es útil para resolver cualquier problema complejo con una función de núcleo adecuada.
- En la práctica, los modelos SVM son generalizados, con menos riesgo de sobreajuste en SVM.
- Los SVM funcionan muy bien para la clasificación de texto y para encontrar el mejor separador lineal.
Contras del algoritmo SVM
- Se necesita un largo tiempo de entrenamiento cuando se trabaja con grandes conjuntos de datos.
- Es difícil entender el modelo final y el impacto individual.
Conclusión
Se ha guiado para admitir el algoritmo de máquina de vectores, que es un algoritmo de aprendizaje automático. En este artículo, discutimos qué es el algoritmo SVM, cómo funciona y sus ventajas en detalle.
Artículos recomendados
Esta ha sido una guía para el algoritmo SVM. Aquí discutimos su funcionamiento con un escenario, pros y contras del algoritmo SVM. También puede consultar los siguientes artículos para obtener más información:
- Algoritmos de minería de datos
- Técnicas de minería de datos
- ¿Qué es el aprendizaje automático?
- Herramientas de aprendizaje automático
- Ejemplos de algoritmo C ++