
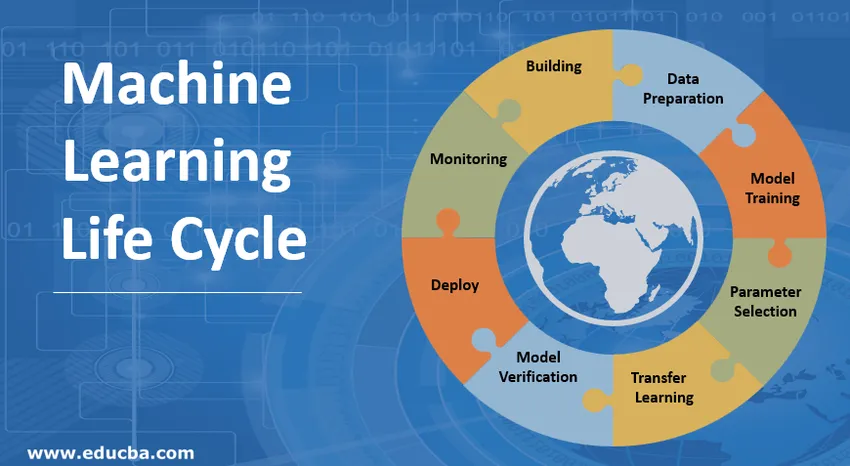
Introducción al ciclo de vida de Machine Learning (ML)
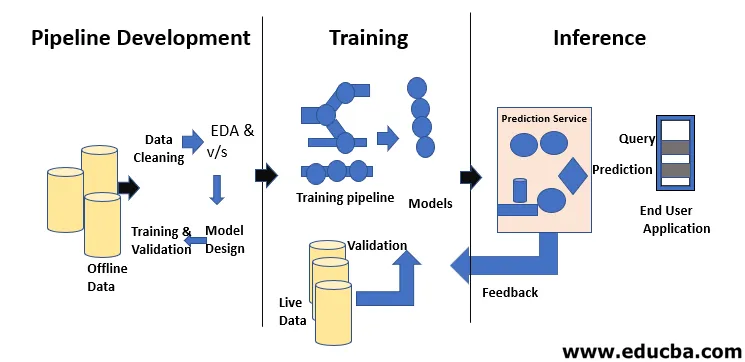
Machine Learning Life Cycle se trata de adquirir conocimiento a través de los datos. El ciclo de vida del aprendizaje automático describe un proceso trifásico utilizado por científicos e ingenieros de datos para desarrollar, entrenar y servir modelos. El desarrollo, capacitación y servicio de modelos de aprendizaje automático es el resultado de un proceso llamado ciclo de vida de aprendizaje automático. Es un sistema que utiliza datos como entrada, con la capacidad de aprender y mejorar el uso de algoritmos sin estar programado para hacerlo. El ciclo de vida del aprendizaje automático tiene tres fases, como se muestra en la figura siguiente: desarrollo de tuberías, capacitación e inferencia.
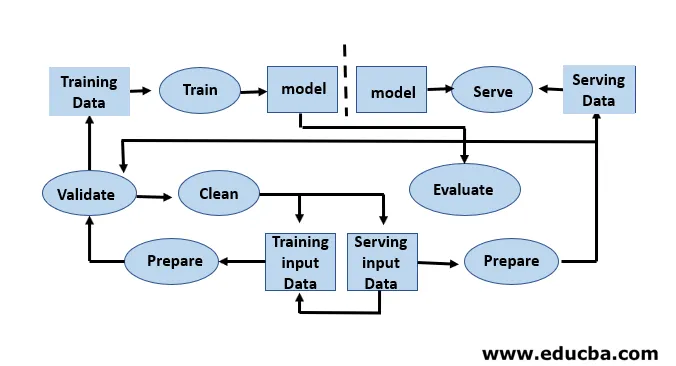
El primer paso en el ciclo de vida del aprendizaje automático consiste en transformar los datos sin procesar en un conjunto de datos limpio, que a menudo se comparte y reutiliza. Si un analista o un científico de datos que encuentra problemas en los datos recibidos, necesitan acceder a los scripts de transformación y datos originales. Hay una variedad de razones por las cuales podemos querer regresar a versiones anteriores de nuestros modelos y datos. Por ejemplo, encontrar la mejor versión anterior puede requerir buscar en muchas versiones alternativas ya que los modelos inevitablemente se degradan en su poder predictivo. Hay muchas razones para esta degradación, como un cambio en la distribución de datos que puede resultar en una disminución rápida en el poder predictivo como compensación por errores. Diagnosticar esta disminución puede requerir comparar datos de entrenamiento con datos en vivo, volver a entrenar el modelo, revisar las decisiones de diseño anteriores o incluso rediseñar el modelo.
Aprendiendo de los errores
El desarrollo de modelos requiere formación separada y conjuntos de datos de prueba. El uso excesivo de los datos de prueba durante el entrenamiento puede conducir a una generalización y un rendimiento deficientes, ya que pueden conducir a un ajuste excesivo. El contexto juega un papel vital aquí, por lo tanto, es necesario comprender qué datos se usaron para entrenar los modelos previstos y con qué configuraciones. El ciclo de vida del aprendizaje automático está basado en datos porque el modelo y el resultado de la capacitación están vinculados a los datos en los que se capacitó. En la figura que se muestra a continuación se muestra una descripción general de una canalización de aprendizaje automático de extremo a extremo con un punto de vista de datos:
Pasos involucrados en el ciclo de vida del aprendizaje automático
El desarrollador de Machine Learning realiza constantemente experimentos con nuevos conjuntos de datos, modelos, bibliotecas de software y parámetros de ajuste para optimizar y mejorar la precisión del modelo. Dado que el rendimiento del modelo depende completamente de los datos de entrada y del proceso de capacitación.
1. Construyendo el modelo de aprendizaje automático
Este paso decide el tipo de modelo en función de la aplicación. También encuentra que la aplicación del modelo en la etapa de aprendizaje del modelo para que puedan diseñarse adecuadamente de acuerdo con la necesidad de una aplicación prevista. Hay una variedad de modelos de aprendizaje automático disponibles, como el modelo supervisado, el modelo no supervisado, los modelos de clasificación, los modelos de regresión, los modelos de agrupamiento y los modelos de aprendizaje de refuerzo. Una visión detallada se muestra en la figura que se muestra a continuación:
2. Preparación de datos
Se puede utilizar una variedad de datos como entrada para fines de aprendizaje automático. Estos datos pueden provenir de varias fuentes, como un negocio, compañías farmacéuticas, dispositivos IoT, empresas, bancos, hospitales, etc. Se proporcionan grandes volúmenes de datos en la etapa de aprendizaje de la máquina, ya que a medida que aumenta el número de datos, se alinea con produciendo los resultados deseados. Estos datos de salida pueden usarse para análisis o alimentarse como entrada en otras aplicaciones o sistemas de aprendizaje automático para los que actuarán como semilla.
3. Entrenamiento modelo
Esta etapa se refiere a la creación de un modelo a partir de los datos que se le proporcionan. En esta etapa, una parte de los datos de entrenamiento se utiliza para encontrar parámetros del modelo, como los coeficientes de un polinomio o los pesos del aprendizaje automático que ayuda a minimizar el error para el conjunto de datos dado. Los datos restantes se utilizan para probar el modelo. Estos dos pasos generalmente se repiten varias veces para mejorar el rendimiento del modelo.
4. Selección de parámetros
Implica la selección de los parámetros asociados con el entrenamiento, que también se denominan hiperparámetros. Estos parámetros controlan la efectividad del proceso de capacitación y, por lo tanto, en última instancia, el rendimiento del modelo depende de esto. Son muy cruciales para la producción exitosa del modelo de aprendizaje automático.
5. Transferencia de aprendizaje
Dado que hay muchos beneficios en la reutilización de modelos de aprendizaje automático en varios dominios. Por lo tanto, a pesar del hecho de que un modelo no se puede transferir entre dominios diferentes directamente, por lo tanto, se utiliza para proporcionar un material de partida para comenzar la capacitación de un modelo de etapa siguiente. Por lo tanto, reduce significativamente el tiempo de entrenamiento.
6. Verificación del modelo
La entrada de esta etapa es el modelo entrenado producido por la etapa de aprendizaje del modelo y el resultado es un modelo verificado que proporciona información suficiente para permitir a los usuarios determinar si el modelo es adecuado para su aplicación prevista. Por lo tanto, esta etapa del ciclo de vida del aprendizaje automático tiene que ver con el hecho de que un modelo funciona correctamente cuando se trata con entradas que no se ven.
7. Implemente el modelo de aprendizaje automático
En esta etapa del ciclo de vida del aprendizaje automático, aplicamos para integrar modelos de aprendizaje automático en procesos y aplicaciones. El objetivo final de esta etapa es la funcionalidad adecuada del modelo después de la implementación. Los modelos deben implementarse de tal manera que puedan usarse para inferencia y deben actualizarse regularmente.
8. Monitoreo
Implica la inclusión de medidas de seguridad para garantizar el correcto funcionamiento del modelo durante su vida útil. Para que esto suceda, se requiere una gestión y actualización adecuadas.
Ventaja del ciclo de vida del aprendizaje automático
El aprendizaje automático proporciona los beneficios de potencia, velocidad, eficiencia e inteligencia a través del aprendizaje sin programarlos explícitamente en una aplicación. Brinda oportunidades para mejorar el rendimiento, la productividad y la solidez.
Conclusión - Ciclo de vida del aprendizaje automático
Los sistemas de aprendizaje automático son cada vez más importantes a medida que la cantidad de datos involucrados en diversas aplicaciones aumenta rápidamente. La tecnología de aprendizaje automático es el corazón de los dispositivos inteligentes, electrodomésticos y servicios en línea. El éxito del aprendizaje automático puede extenderse aún más a los sistemas críticos para la seguridad, la gestión de datos, la informática de alto rendimiento, que tiene un gran potencial para los dominios de aplicación.
Artículos recomendados
Esta es una guía para el ciclo de vida del aprendizaje automático. Aquí discutimos la introducción, Aprendiendo de los errores, los pasos involucrados en el ciclo de vida del aprendizaje automático y las ventajas. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Empresas de Inteligencia Artificial
- Análisis de conjuntos QlikView
- Ecosistema IoT
- Cassandra Data Modeling