

¿Qué es Big Data y Hadoop?
Los datos crecen exponencialmente todos los días y con estos datos crecientes surge la necesidad de utilizar esos datos. Al igual que en los días anteriores, solíamos tener unidades de disquete para almacenar datos y la transferencia de datos también era lenta, pero hoy en día son insuficientes y el almacenamiento en la nube se utiliza ya que tenemos terabytes de datos. En el mundo de hoy, tenemos las redes sociales que contribuyen más alto en el crecimiento de datos. Consiste en el comportamiento de las personas, la mentalidad y varios otros aspectos. Se dice que en cada minuto que se cargan 300 horas de video en YouTube, se cargan más de 20 millones de fotos en Facebook y muchas otras. Además, no existe una estructura adecuada de los datos que se cargan, que es el mayor desafío para procesar esos datos.
A medida que se generan enormes datos a alta velocidad, los sistemas RDBMS tradicionales no pudieron manejar un crecimiento tan acelerado. Además, tampoco son capaces de manejar datos no estructurados. Se hizo muy difícil manejar una cantidad tan grande de datos heterogéneos que crecen rápidamente y procesar estos datos con alta velocidad de procesamiento. Por lo tanto, surgió la necesidad de un sistema que sea capaz de manejar grandes conjuntos de datos de manera eficiente. Por lo tanto, para resolver el escenario, Hadoop surgió. HDFS es el componente de Hadoop que abordó el problema de almacenamiento del gran conjunto de datos mediante el almacenamiento distribuido, mientras que YARN es el componente que abordó el problema de procesamiento y redujo drásticamente el tiempo de procesamiento.
Hadoop es un marco de software de código abierto para almacenar y procesar grandes conjuntos de datos utilizando un gran grupo distribuido de hardware básico. Fue desarrollado por Doug Cutting y Michael J. Cafarella y con licencia de Apache. Está escrito usando Java y fue desarrollado en base al documento escrito por Google en el sistema MapReduce y aplica conceptos de programación funcional. Es confiable, económico, flexible y escalable.
Los componentes principales de Hadoop
Los componentes principales de Hadoop son los siguientes
-
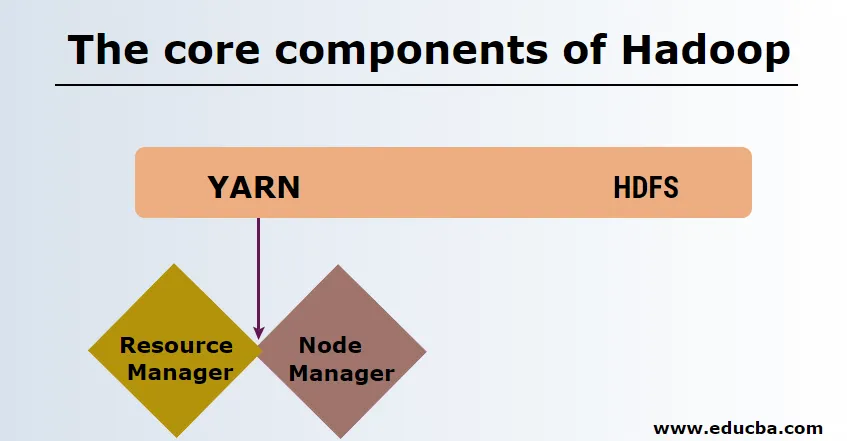
HDFS
HDFS o Hadoop Distributed File System tienen Namenode y nodo de datos. Namenode es el nodo maestro que ejecuta el demonio maestro y gestiona los nodos de datos y realiza un seguimiento de todas las operaciones. Los nodos de datos son los esclavos donde los datos se almacenan realmente.
-
HILO
HILO consta de dos componentes principales:
1. ResourceManager: se ejecuta en el nodo maestro y gestiona todos los recursos y programa todas las aplicaciones. Tiene programador y administrador de aplicaciones.
2. NodeManager: se ejecuta en cada nodo esclavo y es responsable de administrar contenedores y monitorear la utilización de recursos.
Varios componentes de Hadoop
Hay varios componentes de Hadoop como el cerdo, colmena, sqoop, canal, mahout, oozie, zookeeper, HBase, etc.
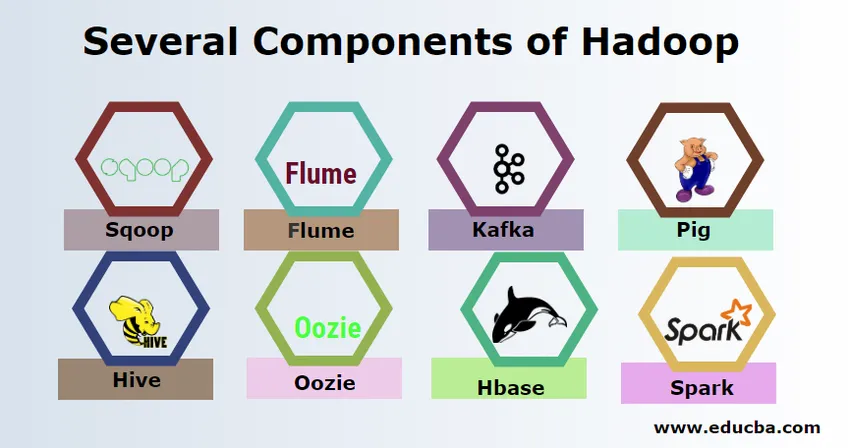
- Sqoop: se utiliza para importar y exportar datos de RDBMS a Hadoop y viceversa.
- Flume : se utiliza para extraer datos en tiempo real en Hadoop.
- Kafka: es un sistema de mensajería utilizado para enrutar datos en tiempo real a Hadoop.
- Pig : se utiliza como lenguaje de script para el procesamiento de datos.
- Colmena : es un marco de almacenamiento de datos creado en HDFS para que los usuarios familiarizados con SQL puedan ejecutar consultas para obtener los datos. Estas consultas se llaman HiveQL.
- Oozie : se utiliza para programar el flujo de trabajo de los trabajos para que se ejecuten en eventos u horarios específicos.
- Hbase : es la base de datos sin SQL que se proporciona como parte de Apache Hadoop.
- Spark: se utiliza para realizar un procesamiento en memoria que es mucho más rápido que la reducción de mapas de Hadoop.
Proveedores de Hadoop
Hay muchas compañías que ofrecen distribuciones de Hadoop. A continuación se presentan los mejores proveedores para Hadoop:
- Cloudera
- Hortonworks
- MapR
Hay pocos requisitos previos para aprender Hadoop. Se necesita experiencia previa en Java y lenguaje de script. Aunque Hadoop ya tiene sus propios lenguajes de programación de alto nivel como pig and hive que genera el código de back-end para su posterior procesamiento, aún es posible crear su propio programa de reducción de mapas en cualquier lenguaje de programación como Ruby, Python, Perl e incluso programación en C.
Bigdata y Hadoop tienen una gran demanda en el mercado actual. Esto va a aumentar más en los próximos días. Mucha organización ya se mudó a Hadoop y aquellos que no se mudarán pronto. Hay un informe actual que indica que las grandes corporaciones han comenzado a invertir en análisis de big data. El pronóstico de marketing de Big Data siempre está en una tendencia al alza y no es en absoluto un estado de corta duración. Además de todo esto, los trabajos en Hadoop y Big Data siempre ofrecen altos salarios en comparación con otras tecnologías.
Principales empresas de Big Data y Hadoop
A continuación se presentan algunas de las principales empresas que emplean la mayor cantidad de recursos de Hadoop.
- Yahoo
- Amazonas
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Hay muchas compañías que usan aplicaciones de big data. Estos son:
-
Nokia
Utiliza componentes de Cloudera y Hadoop como HDFS, HBase, Sqoop, Scribe para la aplicación. Usó los datos del usuario de manera efectiva para comprender y mejorar la experiencia del usuario. Utiliza el procesamiento de datos y análisis complejos para construir el mapa con tráfico predictivo y modelos de elevación en capas.
-
SAS
Ha colaborado con Hadoop para ayudar a los científicos de datos a obtener una mejor visión al proporcionar un entorno que brinde experiencia visual e interactiva, lo que ayuda a explorar nuevas tendencias. Los programas analíticos extraen información significativa de los datos y la tecnología en memoria ayuda a un acceso más rápido a los datos.
También hay muchas otras empresas que utilizan plataformas de big data para diversos análisis. Estos son análisis de datos de vuelos de caja negra en la industria de la aviación, los diferentes análisis en el mercado de acciones, etc.
Ventajas de Haddop
A continuación se presentan algunas de las ventajas de Hadoop.
- Escalable: a diferencia del RDBMS tradicional, es una plataforma altamente escalable ya que puede almacenar grandes conjuntos de datos en grupos distribuidos sobre hardware básico que funciona en paralelo.
- Rentable: el costo era demasiado alto para que RDBMS almacenara datos que se han aliviado en Hadoop.
- Rápido y flexible : ofrece acceso rápido a los datos a través de su sistema de archivos distribuido. También ofrece obtener información comercial de datos semiestructurados y no estructurados.
- Tolerante a fallos : cuando se envían datos a un nodo, los mismos datos se replican en otros nodos a los que se puede acceder en caso de cualquier fallo del primer nodo.
Conclusión: ¿qué es Big Data y Hadoop?
Los datos crecen continuamente y, por lo tanto, siempre habrá necesidad de Big Data y Hadoop para que tengan sentido. Por esta razón, los profesionales con habilidades de Hadoop siempre encontrarán amplias oportunidades en los próximos días y pueden ser un activo vital para una organización que impulse el negocio y su carrera.
Artículos recomendados
Esta ha sido una guía sobre lo que es Big Data y Hadoop. Aquí hemos discutido los conceptos básicos y componentes de Big Data y Hadoop. También puede consultar el siguiente artículo para obtener más información:
- Ejemplos de análisis de Big Data
- Usos de Hadoop
- Guía de visualización de datos
- ¿Qué es el análisis de Big Data?