
Diferencia entre Hadoop y Redshift
Hadoop es un marco de código abierto desarrollado por Apache Software Foundation con sus principales beneficios de escalabilidad, confiabilidad y computación distribuida. El procesamiento de datos, el almacenamiento, el acceso y la seguridad son varios tipos de funciones disponibles en el ecosistema de Hadoop. HDFS tiene un alto rendimiento, lo que significa que es capaz de manejar grandes cantidades de datos con capacidad de procesamiento en paralelo. Redshift es un servicio web de alojamiento en la nube desarrollado por la unidad de servicios web de Amazon dentro de Amazon.com Inc., fuera de los servicios existentes proporcionados por Amazon. Se utiliza para diseñar un almacén de datos a gran escala en la nube. Redshift es un servicio de almacenamiento de datos a escala de petabytes que está totalmente administrado y es rentable para operar en grandes conjuntos de datos.
Estudiemos más sobre Hadoop y Redshift en detalle:
Hadoop HDFS tiene una alta capacidad de tolerancia a fallas y fue diseñado para ejecutarse en sistemas de hardware de bajo costo. Hadoop puede manejar un tamaño de tipo mínimo de TeraBytes a GigaBytes de archivos dentro de su sistema. HDFS es una arquitectura maestro-esclavo que consiste en Nodos de Nombre y Nodos de Datos donde el Nodo de Nombre contiene metadatos y el Nodo de Datos contiene datos reales para ser procesados u operados.
RedShift utiliza diferentes técnicas de carga de datos, como informes de BI (Business Intelligence), herramientas analíticas y minería de datos. Redshift proporciona una consola para crear y administrar clústeres de Amazon Redshift. El componente principal de Redshift Data Warehouse es un clúster.
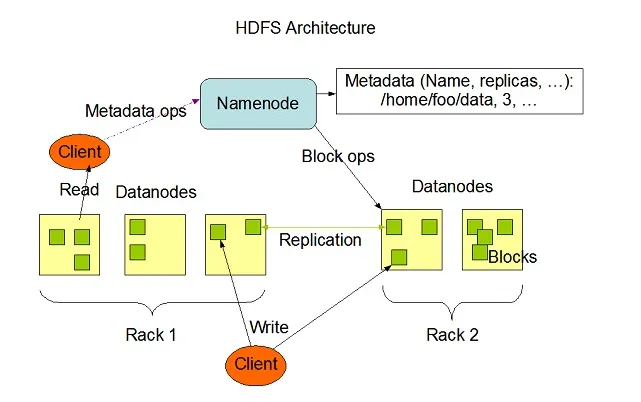
Fuente de la imagen: Apache.org
Arquitectura RedShift:
 Fuente de la imagen: Amazon.com
Fuente de la imagen: Amazon.com
Comparación cabeza a cabeza entre Hadoop y Redshift (infografía):
A continuación se muestran las 10 principales comparaciones entre Hadoop y Redshift:

Diferencias clave entre Hadoop y Redshift:
A continuación se muestran las diferencias clave entre Hadoop y Redshift:
1.La arquitectura Hadoop HDFS (Hadoop Distributed File System) tiene nodos de nombre y nodos de datos, mientras que Redshift tiene nodos de líder y nodos de cómputo donde los nodos de cómputo se dividirán en segmentos.
2. Hadoop proporciona una interfaz de línea de comandos para interactuar con el sistema de archivos, mientras que RedShift tiene una consola de administración para interactuar con servicios de almacenamiento de Amazon como S3, DynamoDB, etc.
3. Las operaciones de la base de datos deben ser configuradas por los desarrolladores. En Redshift automatiza las operaciones de la base de datos al analizar los planes de ejecución.
4.Hadoop tiene varias herramientas de terceros compatibles para integrarse fácilmente, mientras que Redshift solo admite los productos desarrollados por Amazon en su nube.
5.En términos de diseño arquitectónico de Hadoop, la red, el almacenamiento, la seguridad y el rendimiento se han considerado elementos primarios, mientras que en Redshift estos elementos se pueden configurar de manera fácil y flexible utilizando la consola de administración en la nube de Amazon.
6.Hadoop es una arquitectura de sistema de archivos basada en interfaces de programación de aplicaciones (API) de Java, mientras que Redshift se basa en el sistema de gestión de bases de datos modelo relacional (RDBMS).
7.Hadoop puede tener integraciones con diferentes proveedores y Redshift no tiene soporte en este caso donde Amazon es su único proveedor. ¿Qué sucede si un usuario no está satisfecho con el servicio? En este caso, Hadoop es una ventaja.
8. La mayoría de las compañías existentes todavía usan Hadoop, mientras que los nuevos clientes eligen RedShift.
9.En términos, el rendimiento de Hadoop siempre se queda atrás y Redshift siempre gana en el caso de la ejecución de consultas en grandes volúmenes de datos.
10.Hadoop usa el modelo de programación Map Reduce para ejecutar trabajos. Amazon Redshift utiliza Elastic Map Reduce de Amazon.
11.Hadoop usa el modelo de programación Map Reduce para ejecutar trabajos. Amazon Redshift utiliza Elastic Map Reduce de Amazon.
12.Hadoop es preferible ejecutar diariamente trabajos por lotes que se vuelven más baratos, mientras que Redshift sale más barato en el caso de la tecnología de procesamiento analítico en línea (OLAP) que existe detrás de muchas herramientas de Business Intelligence.
13.Hadoop es 10 veces más lento que Redshift en la ejecución de consultas de la misma manera que Hadoop es 10 veces más costoso que Redshift, lo que hace que Hadoop sea el menos elegido antes de Redshift.
14.En términos de carga de datos también, Hadoop ha estado detrás de Redshift en términos si el sistema tarda horas en cargar los datos del almacenamiento en su sistema de procesamiento de archivos.
15.Hadoop se puede usar para almacenamientos de bajo costo, archivo de datos, lagos de datos, almacenamiento de datos y análisis de datos, mientras que Redshift se encuentra bajo las capacidades de almacenamiento de datos, lo que limita el uso multipropósito.
16. La plataforma Hadoop brinda soporte a varios proveedores externos y sus propios proyectos de Apache como Storm, Spark, Kafka, Solr, etc., y por otro lado Redshift tiene un soporte de integración limitado con sus únicos productos de Amazon
Tabla de comparación de Hadoop vs Redshift
| BASE PARA
COMPARACIÓN | HADOOP | REDSHIFT |
| Disponibilidad | Marco de código abierto por proyectos de Apache | Servicios con precios proporcionados por Amazon |
| Implementación | Proporcionado por los proveedores de Hortonworks y Cloudera, etc., | Desarrollado y proporcionado por Amazon |
| Actuación | Los trabajos de Hadoop MapReduce son más lentos | Redshift funciona más rápido que el clúster Hadoop |
| Escalabilidad | Limitaciones en escalabilidad | Se puede reducir / aumentar fácilmente según los requisitos |
| Precios | Cuesta $ 200 por mes para ejecutar consultas | El precio depende de la región del servidor y más barato que Hadoop
Por ejemplo: $ 20 / mes |
| Velocidad | Más rápido pero más lento en comparación con Redshift | 10 veces más rápido que Hadoop |
| Velocidad de consulta | Toma 1491 segundos ejecutar datos de 1.2TB | 155 segundos para ejecutar datos de 1.2TB |
| Integración de datos | Flexible con sistema de archivos local y cualquier base de datos | Solo puede cargar datos de Amazon S3 o DynamoDB |
| Formato de datos | Todos los formatos de datos son compatibles | Estricto en formatos de datos como los formatos de archivo CSV |
| Facilidad de uso | Complejo y complicado para manejar actividades administrativas | Copia de seguridad automatizada y administración de almacenamiento de datos |
Conclusión - Hadoop vs Redshift
La declaración final para concluir que el gran ganador en esta comparación es Redshift que gana en términos de facilidad de operaciones, mantenimiento y productividad, mientras que Hadoop carece de escalabilidad de rendimiento y costo de servicios con el único beneficio de una fácil integración con herramientas de terceros. y productos. Redshift ha evolucionado recientemente con un gran crecimiento y aceptación por parte de muchos clientes y clientes debido a su alta disponibilidad y menor costo de operaciones en comparación con Hadoop lo hace cada vez más popular. Pero, hasta ahora, la mayoría de las compañías Fortune 1000 existentes han estado utilizando plataformas Hadoop en sus arquitecturas para administrar los datos del cliente.
En la mayoría de los casos, RedShift ha sido la mejor opción para los fines comerciales de cualquier cliente o cliente a fin de manejar los datos grandes y confidenciales de cualquier institución financiera o información pública con más integridad y seguridad de los datos.
Además de esto, Hadoop tiene sus propias ventajas al ser un proyecto de código abierto y había estado disponible durante muchos años, lo que también hace que los sistemas existentes se reemplacen como un proceso que genera costos. El producto finalmente debe elegirse en función de los requisitos y la flexibilidad en lugar de los precios o la popularidad en función de las necesidades comerciales impulsadas.
Artículo recomendado:
Esta ha sido una guía de Hadoop vs Redshift, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- Hadoop vs Hive - Descubre las mejores diferencias
- HADOOP vs RDBMS | Conozca las 12 diferencias útiles
- Apache Hadoop vs Apache Spark | ¡Las 10 mejores comparaciones que debes conocer!
- Big Data vs Data Science: ¿en qué se diferencian?
- Guía sobre Hadoop vs Spark
- Los 4 principales proveedores de alojamiento en la nube con funciones