
Introducción a las técnicas de análisis de datos
En el siglo XXI, el análisis de datos es una de las palabras más utilizadas en todos los dominios. Entonces, hoy veamos qué quiere decir todo el mundo con el análisis de datos y algunas técnicas importantes en el análisis de datos. El análisis de datos es el proceso de inspección, limpieza, transformación y modelado de datos con la intención de descubrir información útil que pueda mejorar la toma de decisiones. En 2019, dijo el economista, "El activo más valioso del mundo ya no es el petróleo, sino los DATOS". El análisis de datos está estrechamente relacionado con la visualización de datos. Según la cantidad de datos que las industrias generan cada minuto, y según su necesidad, existe una variedad de técnicas que surgieron. Veamos cuáles son en la siguiente sección. En este tema, vamos a aprender sobre los tipos de técnicas de análisis de datos.
Tipos importantes de técnicas de análisis de datos
Las técnicas de análisis de datos se clasifican en general en dos tipos:
- Métodos basados en enfoques matemáticos y estadísticos.
- Métodos basados en inteligencia artificial y aprendizaje automático.
Enfoques matemáticos y estadísticos
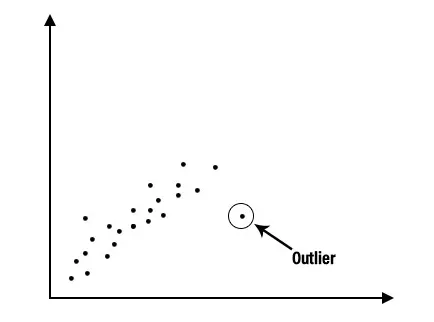
1. Análisis descriptivo: El análisis descriptivo es un primer paso importante para realizar análisis estadísticos. Nos proporciona una idea de la distribución de datos, ayuda a detectar valores atípicos y nos permite identificar asociaciones entre variables, preparando así los datos para realizar análisis estadísticos adicionales. El análisis descriptivo de un gran conjunto de datos se puede facilitar dividiéndolo en dos categorías, son análisis descriptivos para cada variable individual y análisis descriptivo para combinaciones de variables.
2. Análisis de regresión: el análisis de regresión es una de las técnicas de análisis de datos dominantes que se está utilizando en la industria en este momento. En este tipo de técnica, podemos ver la relación entre dos o más variables de interés y, en el centro, todas estudian la influencia de una o más variables independientes en la variable dependiente. Para ver si hay alguna relación entre las variables o no, primero tenemos que trazar los datos en un gráfico y será evidente si existe alguna relación. Por ejemplo, considere el gráfico trazado a continuación para tener una comprensión clara.
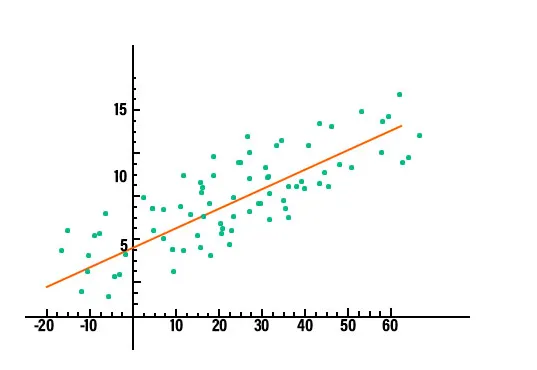
En la minería de datos, esta técnica se usa para predecir los valores de una variable, en ese conjunto de datos en particular. Existen diferentes tipos de modelos de regresión en uso. Algunos de ellos son regresión lineal, regresión logística y regresión múltiple.
3. Análisis de dispersión: la dispersión es el grado en que una distribución se estira o se exprime. En el enfoque matemático, la dispersión se puede definir de dos maneras, fundamentalmente la diferencia de valores entre ellos y, en segundo lugar, la diferencia entre el valor promedio. Si la diferencia entre el valor y el promedio es muy baja, entonces podemos decir que la dispersión es menor en este caso. Y algunas de las medidas comunes de dispersión son la varianza, la desviación estándar y el rango intercuartil.
4. Análisis factorial: el análisis factorial es un tipo de técnica de análisis de datos que ayuda a encontrar la estructura subyacente en un conjunto de variables. Ayuda a encontrar variables independientes en el conjunto de datos que describe los patrones y modelos de relaciones. Es el primer paso hacia los procedimientos de agrupamiento y clasificación. El análisis factorial también está relacionado con el análisis de componentes principales (PCA), pero ambos no son idénticos, podemos llamar PCA como la versión más básica del análisis factorial exploratorio
5. Series temporales: el análisis de series temporales es una técnica de análisis de datos que se ocupa de los datos de series temporales o análisis de tendencias. Ahora, comprendamos qué son los datos de series temporales. Los datos de series de tiempo son datos en una serie de intervalos de tiempo o períodos particulares. Si vemos científicamente, la mayoría de las mediciones se ejecutan con el tiempo.
Métodos basados en el aprendizaje automático y la inteligencia artificial.
1. Árboles de decisión: el análisis del árbol de decisión es una representación gráfica, similar a una estructura similar a un árbol en la que los problemas en la toma de decisiones se pueden ver en forma de un diagrama de flujo, cada uno con ramas para respuestas alternativas. Los árboles de decisión son un tipo de enfoque de arriba hacia abajo, con el primer nodo de decisión en la parte superior, según la respuesta en el primer nodo de decisión, se dividirá en ramas y continuará hasta que el árbol llegue a una decisión final. Las ramas que ya no se dividen se conocen como hojas.
2. Redes neuronales: las redes neuronales son un conjunto de algoritmos diseñados para imitar el cerebro humano. También se conoce como la "Red de neuronas artificiales". Las aplicaciones de la red neuronal en la minería de datos son muy amplias. Tienen una gran capacidad de aceptación para datos ruidosos y resultados de alta precisión. Según la necesidad, actualmente se utilizan muchos tipos de redes neuronales, pocas de ellas son redes neuronales recurrentes y redes neuronales convolucionales. Las redes neuronales convolucionales se utilizan principalmente en el procesamiento de imágenes, el procesamiento del lenguaje natural y los sistemas de recomendación. Las redes neuronales recurrentes se utilizan principalmente para la escritura a mano y el reconocimiento de voz.
3. Algoritmos evolutivos: los algoritmos evolutivos utilizan los mecanismos inspirados en la recombinación y la selección. Estos tipos de algoritmos son independientes del dominio y tienen la capacidad de explorar grandes conjuntos de datos, descubrir patrones y soluciones. Son insensibles al ruido en comparación con otras técnicas de datos.
4. Lógica difusa: es un enfoque en informática basado en el "Grado de verdad" en lugar de la "lógica booleana" común (verdad / falso o 0/1). Como se discutió anteriormente en los árboles de decisión en el nodo de decisión, tenemos sí o no como respuesta, ¿qué sucede si tenemos una situación en la que no podemos decidir sí absoluto o absoluto no? En estos casos, la lógica difusa juega un papel importante. Es una lógica de valores diversos en la que el valor de verdad puede estar entre completamente verdadero y completamente falso, es decir, puede tomar cualquier valor real entre 0 y 1. La lógica difusa es aplicable cuando hay una cantidad significativa de ruido en los valores.
Conclusión
La pregunta difícil que enfrentan todas las empresas o compañías es qué tipo de técnica de análisis de datos es la mejor para ellos. No podemos definir ninguna técnica como la mejor; en cambio, lo que podemos hacer es probar varias técnicas y ver cuál se adapta mejor a nuestro conjunto de datos y usarlo. Las técnicas mencionadas anteriormente son algunas de las técnicas importantes que se utilizan actualmente en la industria.
Artículos recomendados
Esta es una guía de los tipos de técnicas de análisis de datos. Aquí discutimos los tipos de técnicas de análisis de datos que se utilizan actualmente en la industria. También puede echar un vistazo a los siguientes artículos para obtener más información:
- Herramientas de ciencia de datos
- Plataforma de ciencia de datos
- Carrera de ciencia de datos
- Tecnologías de Big Data
- Agrupación en Machine Learning
- Sistema de lógica difusa | Cuándo usar, arquitectura
- Guía completa para la implementación de redes neuronales
- ¿Qué es el análisis de datos?
- Crear árbol de decisión con ventajas
- Guía para diferentes tipos de análisis de datos