
Introducción a AWS Data Pipeline
Los datos crecen exponencialmente día a día y se vuelven difíciles de administrar en comparación con el pasado. Necesitamos herramientas y servicios para administrar nuestros datos de manera eficiente y a un costo más barato, ahí es donde viene a la mente el AWS Data Pipeline. No se trata solo de almacenar datos, sino que debe analizar, procesar y transformar los datos en la forma deseada en el mismo lugar, todo esto se puede lograr con AWS Data Pipeline.
Necesidad de canalización de datos
Tratemos de comprender la necesidad de la canalización de datos con el ejemplo:
Ejemplo 1
Tenemos un sitio web que muestra imágenes y gifs en función de las búsquedas o filtros de los usuarios. Nuestro enfoque principal es servir contenido. Hay ciertos objetivos a alcanzar que son los siguientes:
- Mejora de la entrega de contenido: Sirviendo lo que los usuarios quieren de manera eficiente y lo suficientemente rápida.
- Administre la aplicación de manera eficiente: almacenar los datos del usuario, así como los registros del sitio web para fines analíticos posteriores.
- Mejore el negocio: el uso de datos almacenados y análisis toma la decisión de mejorar el negocio a un costo más económico.
Ejemplo # 2
Hay ciertos cuellos de botella que deben tenerse en cuenta para alcanzar los objetivos:
- La gran cantidad de datos en diferentes formatos y en diferentes lugares hace que procesar, almacenar y migrar datos sea una tarea compleja.
Diferentes componentes de almacenamiento de datos para diferentes tipos de datos:
- Posibles datos en tiempo real para los usuarios registrados: Dynamo DB .
- Registros del servidor web para usuarios potenciales: Amazon S3 .
- Datos demográficos y credenciales de inicio de sesión: Amazon RDS.
- Datos del sensor y conjunto de datos de terceros: Amazon S3.
Soluciones
- Solución factible: Podemos ver que tenemos que lidiar con diferentes tipos de herramientas para convertir datos de estructurados a estructurados para análisis. Aquí tenemos que usar diferentes herramientas para almacenar datos y nuevamente para convertir, analizar y almacenar datos procesados. No es una solución rentable.
- Solución óptima: utilice una canalización de datos que maneje el procesamiento, la visualización y la migración. La canalización de datos puede ser útil en la migración de datos desde diferentes lugares, también analizando datos y procesando en la misma ubicación en su nombre.
¿Qué es la canalización de datos de AWS?
AWS Data Pipeline es básicamente un servicio web ofrecido por Amazon que lo ayuda a transformar, procesar y analizar sus datos de manera escalable y confiable, así como a almacenar datos procesados en S3, DynamoDb o su base de datos local.
- Con AWS Data Pipeline puede acceder fácilmente a datos de diferentes fuentes.
- Transforme y procese esos datos a escala.
- Transfiera los resultados de manera eficiente a otros servicios como S3, tabla DynamoDb o almacén de datos local.
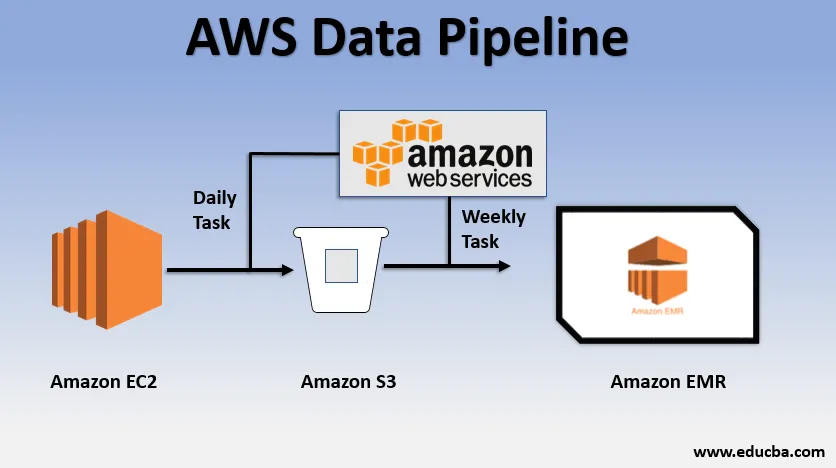
Ejemplo de uso básico de la canalización de datos
- Podríamos tener un sitio web implementado en EC2 que genera registros todos los días.
- Una simple tarea diaria podría copiarse archivos de registro de E2 y lograrlos en el bucket de S3.
- Una tarea semanal podría ser procesar los datos e iniciar el análisis de datos a través de Amazon EMR para generar informes semanales sobre la base de todos los datos recopilados.
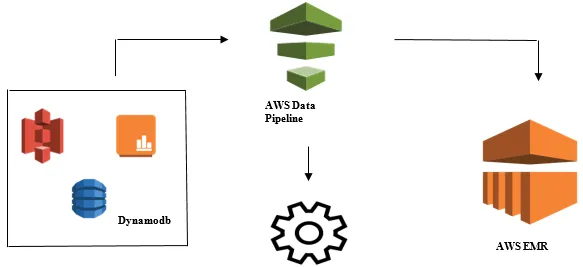
Inicio del análisis de datos con AWS Data Pipeline
- Recopilación de datos de diferentes fuentes de datos como: S3, Dynamodb, local, datos de sensores, etc.
- Realización de transformación, procesamiento y análisis en AWS EMR para generar informes semanales.
- Informe semanal guardado en Redshift, S3 o base de datos local.
Beneficios de la canalización de datos de AWS
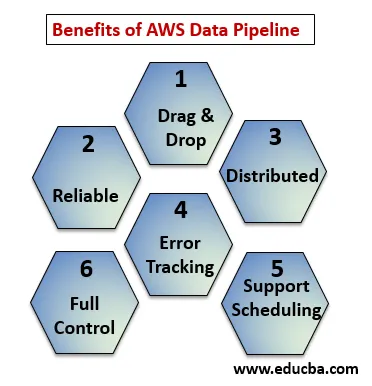
Debajo de los puntos se explican los beneficios de AWS Data Pipeline:
- Consola de arrastrar y soltar que es fácil de entender y usar.
- Infraestructura distribuida y confiable: las canalizaciones de datos se ejecutan en servicios escalables y son confiables si falla cualquier error o tarea, se puede configurar para volver a intentarlo.
- Admite la programación y el seguimiento de errores: puede programar sus tareas y realizar un seguimiento de las fallas y el éxito.
- Distribuido: se puede ejecutar en paralelo en varias máquinas o de forma lineal.
- Control total sobre recursos computacionales como EC2, clústeres EMR.
Componentes de canalización de datos de AWS
A continuación se muestran los componentes de la canalización de datos de AWS:
1. Definición de tubería
Convierta su lógica empresarial en AWS Data Pipeline.
- Nodos de datos : contiene el nombre, la ubicación y el formato del origen de datos que podría ser (S3, dynamodb, local)
- Actividades : mover, transformar o realizar consultas sobre sus datos.
- Programa : programa tus actividades diarias o semanales.
- Precondición : las condiciones como iniciar el programador verifican la disponibilidad de datos en la fuente.
- Recursos : recursos informáticos EC2, EMR.
- Acciones : Actualización sobre canalización de datos, envío de notificaciones, activación de alarma.
2. Tuberías
Aquí puede programar y ejecutar las tareas para realizar actividades definidas.
- Componentes de la tubería C : los componentes de la tubería son los mismos que los componentes de la definición de tubería.
- Instancias: mientras ejecuta tareas, AWS compila todos los componentes para crear ciertas instancias accionables. Tales instancias tienen toda la información sobre tareas específicas.
- Intentos: ya hemos discutido cuán confiable es la canalización de datos con sus mecanismos de reintento. Aquí establece cuántas veces desea volver a intentar la tarea en caso de que falle.
3. Task Runner
Pregunta o sondea las tareas de AWS Data Pipeline y luego realiza esas tareas.
Precios de tubería de datos de AWS
Debajo de los puntos, explique el precio de la tubería de datos de AWS:
1. Nivel libre
Puede comenzar a utilizar AWS Data Pipeline de forma gratuita como parte del nivel de uso gratuito de AWS. Los nuevos clientes registrados obtienen cada mes algunos beneficios gratuitos durante un año:
- 3 Condiciones previas de baja frecuencia que se ejecutan en AWS sin cargo alguno.
- 5 Actividades de baja frecuencia que se ejecutan en AWS sin cargo.
2. baja frecuencia
Baja frecuencia debe ejecutarse una vez en un día o menos. Data Pipeline sigue la misma estrategia de facturación que otros servicios web de AWS, es decir, facturado por su uso. Se factura según la frecuencia con la que se ejecutan sus tareas, actividades y condiciones previas todos los días y dónde se ejecutan (AWS o local). Las actividades de alta frecuencia están programadas para ejecutarse más de una vez al día.
Ejemplo: podemos programar una actividad para que se ejecute cada hora y procesar los registros del sitio web o podría ser cada 12 horas. Mientras que las actividades de baja frecuencia son aquellas que se realizan una vez al día o menos si no se cumplen las condiciones previas. Las tuberías inactivas tienen estados INACTIVO, PENDIENTE y FINALIZADO.
3. Se muestra el precio de la tubería de datos de AWS por región
Región # 1: EE . UU. Este (N.Virginia), EE. UU. Oeste (Oregón), Asia Pacífico (Sídney), UE (Irlanda)
| Alta frecuencia | Baja frecuencia | |
| Actividades o condiciones previas que se ejecutan en AWS | $ 1.00 por mes | $ 0.06 por mes |
| Actividades o condiciones previas que se ejecutan en las instalaciones | $ 2.50 por mes | $ 1.50 por mes |
| Tuberías inactivas: $ 1.00 por mes |
Región # 2: Asia Pacífico (Tokio)
| Alta frecuencia | Baja frecuencia | |
| Actividades o condiciones previas que se ejecutan en AWS | $ 0.9524 por mes | $ 0.5715 por mes |
| Actividades o condiciones previas que se ejecutan en las instalaciones | $ 2.381 por mes | $ 1.4286 por mes |
| Tuberías inactivas: $ 0.9524 por mes |
La canalización de que un trabajo diario, es decir, una actividad de baja frecuencia en AWS para mover datos de la tabla DynamoDB a Amazon S3 costaría $ 0.60 por mes. Si agregamos EC2 para producir un informe basado en datos de Amazon S3, el costo total de la tubería sería de $ 1.20 por mes. Si realizamos esta actividad cada 6 horas, costaría $ 2.00 por mes, porque entonces sería una actividad de alta frecuencia.
Conclusión
AWS Data Pipeline es una solución muy útil para administrar los datos que crecen exponencialmente a un costo más barato. Es muy confiable y escalable según su uso. Para cualquier necesidad comercial donde se trate con una gran cantidad de datos, AWS Data Pipeline es una muy buena opción para alcanzar todos nuestros objetivos comerciales.
Artículos recomendados
Esta es una guía de la canalización de datos de AWS. Aquí discutimos las necesidades de la tubería de datos, qué es la tubería de datos de AWS, sus componentes y detalles de precios. También puede consultar nuestros otros artículos relacionados para obtener más información:
- AWS EBS
- Bases de datos de AWS
- ¿Qué es AWS EC2?
- Beneficios de la visualización de datos
- Los 7 principales competidores de AWS con características
- Conozca la lista de características de los servicios web de Amazon