

Introducción a las técnicas de ciencia de datos
En el mundo de hoy, donde los datos son el nuevo oro, existen diferentes tipos de análisis disponibles para que un negocio realice. El resultado de un proyecto de ciencia de datos varía mucho con el tipo de datos disponibles y, por lo tanto, el impacto también es variable. Dado que hay muchos tipos diferentes de análisis disponibles, se hace imprescindible comprender qué técnicas de línea de base deben seleccionarse. El objetivo esencial de las técnicas de ciencia de datos no es solo buscar información relevante, sino también detectar enlaces débiles que tienden a hacer que el modelo funcione mal.
¿Qué es la ciencia de datos?
La ciencia de datos es un campo que se extiende sobre varias disciplinas. Incorpora métodos, procesos, algoritmos y sistemas científicos para recopilar conocimientos y trabajar sobre ellos. Este campo incluye una variedad de géneros y es una plataforma común para la unificación de conceptos de estadística, análisis de datos y aprendizaje automático. En esto, el conocimiento teórico de las estadísticas junto con datos y técnicas en tiempo real en el aprendizaje automático trabajan de la mano para obtener resultados fructíferos para el negocio. Usando diferentes técnicas empleadas en la ciencia de datos, en el mundo de hoy podemos implicar una mejor toma de decisiones que de lo contrario podría pasar por alto el ojo humano y la mente. ¡Recuerde que la máquina nunca olvida! Para maximizar las ganancias en un mundo basado en datos, la magia de Data Science es una herramienta necesaria.
Diferentes tipos de técnica de ciencia de datos
En los siguientes párrafos, analizaremos las técnicas comunes de ciencia de datos utilizadas en cualquier otro proyecto. Aunque a veces la técnica de la ciencia de datos puede ser específica de un problema comercial y puede no caer en las categorías a continuación, está perfectamente bien denominarlos como tipos diversos. En un nivel alto, dividimos las técnicas en Supervisadas (sabemos impacto objetivo) y No supervisadas (No sabemos acerca de la variable objetivo que estamos tratando de lograr). En el siguiente nivel, las técnicas se pueden dividir en términos de
- El resultado que obtendríamos o cuál es la intención del problema comercial
- Tipo de datos utilizados.
Veamos primero la segregación basada en la intención.
1. Aprendizaje no supervisado
- Detección de anomalías
En este tipo de técnica, identificamos cualquier ocurrencia inesperada en todo el conjunto de datos. Dado que el comportamiento difiere del hecho real de un dato, los supuestos subyacentes son:
- La aparición de estas instancias es muy pequeña en número.
- La diferencia en el comportamiento es significativa.
Se explican los algoritmos de anomalías, como el Bosque de aislamiento, que proporciona una puntuación para cada registro en un conjunto de datos. Este algoritmo es un modelo basado en árbol. Utilizando este tipo de técnica de detección y su popularidad, se utilizan en varios casos de negocios, por ejemplo, vistas de páginas web, tasa de abandono, ingresos por clic, etc. En el siguiente gráfico podemos explicar cómo se ve la anomalía.
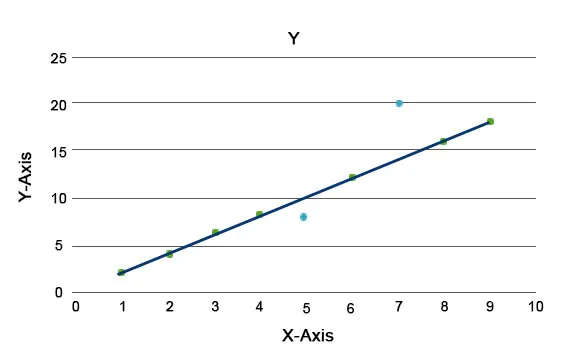
Aquí los que están en azul representan una anomalía en el conjunto de datos. Varían de la línea de tendencia regular y son menos frecuentes.
- Análisis de agrupamiento
A través de este análisis, la tarea principal es segregar todo el conjunto de datos en grupos para que la tendencia o los rasgos en los puntos de datos de un grupo sean bastante similares entre sí. En la terminología de la ciencia de datos, los llamamos agrupación. Por ejemplo, en el negocio minorista, existe un plan para escalar el negocio y se hace imprescindible saber cómo se comportarían los nuevos clientes en una nueva región en función de los datos pasados que tenemos. Se hace imposible diseñar una estrategia para cada individuo en una población, pero será útil agrupar a la población en grupos para que la estrategia sea efectiva en un grupo y sea escalable.
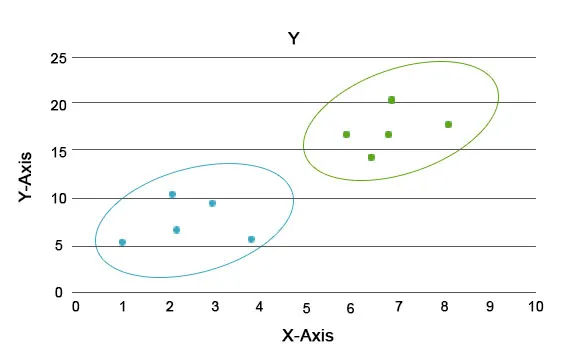
Aquí los colores azul y naranja son diferentes grupos que tienen rasgos únicos dentro de sí mismos.
- Análisis de asociación
Este análisis nos ayuda a construir relaciones interesantes entre los elementos de un conjunto de datos. Este análisis descubre relaciones ocultas y ayuda a representar elementos del conjunto de datos en forma de reglas de asociación o conjuntos de elementos frecuentes. La regla de asociación se divide en 2 pasos:
- Generación frecuente de conjuntos de elementos: en este caso, se genera un conjunto donde los elementos que ocurren con frecuencia se configuran juntos.
- Generación de reglas: el conjunto creado anteriormente se pasa a través de diferentes capas de formación de reglas para construir una relación oculta entre ellos. Por ejemplo, el conjunto puede caer en problemas conceptuales o de implementación o problemas de aplicación. Luego se ramifican en los árboles respectivos para construir las reglas de asociación.
Por ejemplo, APRIORI es un algoritmo de creación de reglas de asociación.
2. Aprendizaje supervisado
- Análisis de regresión
En el análisis de regresión, definimos la variable dependiente / objetivo y las variables restantes como variables independientes y eventualmente hipotetizamos cómo una o más variables independientes influyen en la variable objetivo. La regresión con una variable independiente se llama univariada y con más de una se conoce como multivariada. Comprendamos el uso de univariante y luego escalemos para multivariado.
Por ejemplo, y es la variable objetivo y x 1 es la variable independiente. Entonces, a partir del conocimiento de la línea recta, podemos escribir la ecuación como y = mx 1 + c. Aquí "m" determina qué tan fuertemente y es influenciado por x 1 . Si "m" está muy cerca de cero, significa que con un cambio en x 1, y no se ve muy afectado. Con un número mayor que 1, el impacto se vuelve más fuerte y un pequeño cambio en x 1 conduce a una gran variación en y. Similar a univariado, en multivariado puede escribirse como y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Aquí el impacto de cada variable independiente está determinado por su correspondiente “m”.
- Análisis de clasificación
De manera similar al análisis de agrupamiento, los algoritmos de clasificación se crean con la variable objetivo en forma de clases. La diferencia entre la agrupación y la clasificación radica en el hecho de que en la agrupación no sabemos en qué grupo caen los puntos de datos, mientras que en la clasificación sabemos a qué grupo pertenece. Y difiere de la regresión desde la perspectiva de que el número de grupos debe ser un número fijo, a diferencia de la regresión, es continuo. Hay un montón de algoritmos en el análisis de clasificación, por ejemplo, Máquinas de vectores de soporte, Regresión logística, Árboles de decisión, etc.
Conclusión
En conclusión, entendemos que cada tipo de análisis es vasto en sí mismo, pero aquí podemos proporcionar un pequeño sabor a diferentes técnicas. En las siguientes notas, tomaríamos cada una de ellas por separado y entraríamos en detalles sobre diferentes sub-técnicas empleadas en las técnicas de cada padre.
Artículo recomendado
Esta es una guía de técnicas de ciencia de datos. Aquí discutimos la introducción y los diferentes tipos de técnicas en ciencia de datos. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Herramientas de ciencia de datos | Top 12 herramientas
- Algoritmos de ciencia de datos con tipos
- Introducción a la carrera de ciencia de datos
- Ciencia de datos vs visualización de datos
- Ejemplos de regresión multivariante
- Crear árbol de decisión con ventajas
- Breve descripción del ciclo de vida de la ciencia de datos