
Introducción a los archivos R CSV
Los archivos CSV se usan ampliamente para almacenar la información en formato tabular, y cada línea es un registro de datos. Para leer, escribir o manipular datos en R, debemos tener algunos datos disponibles con nosotros. Los datos se pueden encontrar en Internet o se pueden recopilar de diversas fuentes, como encuestas. Usando R uno puede leer, escribir y editar los datos que están almacenados en un entorno externo. R puede leer y escribir datos de varios formatos como XML, CSV y Excel. En este artículo, veremos cómo se puede usar R para leer, escribir y realizar diferentes operaciones en archivos CSV.
Crear archivo CSV en R
En esta sección, veremos cómo se puede crear y exportar un marco de datos al archivo CSV en R. En el primero, crearemos un marco de datos que consta de variables empleado y salario respectivo.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
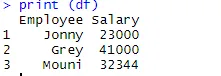
Una vez que se crea el marco de datos, es hora de que usemos la función de exportación de R para crear un archivo CSV en R. Para exportar el marco de datos a CSV, podemos usar el siguiente código.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
En la línea de código anterior, proporcionamos un directorio de ruta para nuestra fama de datos y almacenamos el marco de datos en formato CSV. En el caso anterior, el archivo CSV se guardó en mi escritorio personal. Este archivo en particular se usará en nuestro tutorial para realizar múltiples operaciones.
Lectura de archivos CSV en R
Al realizar análisis usando R, en muchos casos estamos obligados a leer los datos del archivo CSV. R es muy confiable mientras lee archivos CSV. En el ejemplo anterior, hemos creado el archivo, que usaremos para leer usando el comando read.csv. A continuación se muestra el ejemplo para hacerlo en R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

El comando anterior lee el archivo Employee.csv que está disponible en el escritorio y lo muestra en R studio. El comando de encabezado implica que el encabezado está disponible para el conjunto de datos y el comando sep implica que los datos están separados por comas.
Escribir archivos CSV en R
Escribir en un archivo CSV es una de las funcionalidades más útiles disponibles en R para un analista de datos. Esto se puede usar para escribir un archivo CSV editado en un nuevo archivo CSV para analizar los datos. El comando Write.csv se usa para escribir el archivo en CSV.
En el siguiente código df en el marco de datos en el que están disponibles nuestros datos, agregar se usa para especificar que el nuevo archivo se crea en lugar de agregar o sobrescribir en el archivo anterior. Append false sugiere que se cree un nuevo archivo CSV. Sep representa el campo separado por una coma.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
Operaciones CSV
Se requieren operaciones CSV para inspeccionar los datos una vez que se han cargado en el sistema. R tiene varias funcionalidades integradas para verificar e inspeccionar los datos. Estas operaciones proporcionan información completa sobre el conjunto de datos.
Uno de los comandos más utilizados es un resumen.
> summary(df)
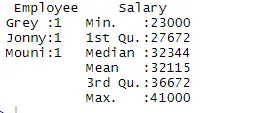
El comando resumen nos proporciona estadísticas en columnas. La variable numérica se describe de manera estadística que incluye resultados estadísticos como media, min, mediana y max. En el ejemplo anterior, dos variables que son Empleado y Salario están segregadas y se nos muestran estadísticas para la variable numérica que es Salario.
El comando Ver () se usa para abrir el conjunto de datos en otra pestaña y verificarlo manualmente.
> View(df)

La función Str proporcionará a los usuarios más detalles sobre la columna del conjunto de datos. En el siguiente ejemplo podemos ver que la variable Empleado tiene Factor como tipo de datos y la variable Salario tiene int (entero) como tipo de datos.
> str(df)

En muchos casos, necesitaremos ver el número total de filas disponibles en el caso del gran conjunto de datos, para lo cual podemos usar el comando nrow (). Por favor vea el ejemplo a continuación.
> # to show the total number of rows in the dataset
> nrow(df)

De manera similar para mostrar el número total de columnas, podemos usar el comando ncol ()
> ncol(df)

R nos permite mostrar el número deseado de filas con la ayuda del siguiente comando. Cuando su n número de filas disponibles en el conjunto de datos, podemos especificar el rango de filas que se mostrarán.
> # to display first 2 rows of the data
> df(1:2, )

La operación de datos se realiza en el gran conjunto de datos. Por ejemplo, descargué el conjunto de datos de código abierto de código postal de NI de Internet.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
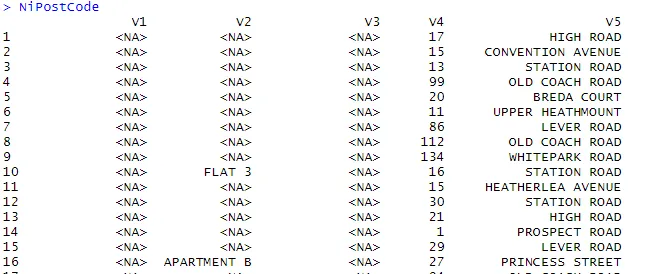
En el conjunto de datos anterior, podemos ver que faltan los nombres de encabezado y hay muchos valores nulos presentes. El conjunto de datos debe limpiarse para estar listo para el análisis. En el siguiente paso, los encabezados serán los nombres correspondientes.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Ahora, cuentemos el número de valores faltantes en el marco de datos y luego elimínelos en consecuencia.
> # count of all missing values
> table(is.na (NiPostCode))

Desde el comando anterior, podemos ver que el número total de espacios en blanco o NA en el marco de datos está cerca de 5445148. Eliminar todos los valores nulos dará como resultado la pérdida de la gran cantidad de datos, por lo tanto, es aconsejable eliminar las columnas donde más de la mitad Falta el 50% de los datos.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Conclusión
En este tutorial, hemos visto cómo se pueden crear, leer y agregar archivos CSV utilizando operaciones en R. Hemos aprendido cómo crear un nuevo conjunto de datos en R y luego importarlo al formato CSV. Además, hemos visto varias operaciones, como cambiar el nombre del encabezado y contar el número de filas y columnas.
Artículos recomendados
Esta es una guía para los archivos R CSV. Aquí discutimos la creación, lectura y escritura de archivos CSV en R con las Operaciones CSV. También puede consultar el siguiente artículo para obtener más información:
- JSON vs CSV
- Proceso de minería de datos
- Carreras en análisis de datos
- Excel vs CSV