

Diferencia entre MapReduce y Spark
Map Reduce es un marco de código abierto para escribir datos en HDFS y procesar datos estructurados y no estructurados presentes en HDFS. Map Reduce se limita al procesamiento por lotes y en otros Spark puede realizar cualquier tipo de procesamiento. SPARK es un motor de procesamiento independiente para el procesamiento en tiempo real que se puede instalar en cualquier sistema de archivos distribuidos como Hadoop. SPARK proporciona un rendimiento 10 veces más rápido que Map Reduce en disco y 100 veces más rápido que Map Reduce en una red en la memoria.
Necesidad de chispa
- Análisis iterativo: Map-reduce no es tan eficiente como un SPARK para resolver problemas que requieren análisis iterativos, ya que tiene que ir al disco para cada iteración.
- Analítica interactiva: Map-reduce se usa a menudo para ejecutar consultas ad-hoc para las cuales necesita acceder a la memoria en el disco, que de nuevo no es tan eficiente como SPARK porque este último se refiere a la memoria interna, que es más rápida.
- No es adecuado para OLTP: como funciona en el marco orientado a lotes, no es adecuado para una gran cantidad de transacciones cortas.
- No es adecuado para Graph: la biblioteca Apache Graph procesa el gráfico, lo que agrega más complejidad a Map Reduce.
- No es adecuado para operaciones triviales: para operaciones como un filtro y uniones, es posible que necesitemos reescribir los trabajos, lo que se vuelve más complejo debido al patrón clave-valor.
Comparación cabeza a cabeza entre MapReduce y Spark (infografía)
A continuación se muestran las 15 principales diferencias entre MapReduce y Spark

Diferencias clave entre MapReduce y Spark
A continuación se encuentran las listas de puntos, describa las diferencias clave entre MapReduce y Spark:
- Spark es adecuado para el tiempo real, ya que procesa el uso en memoria, mientras que MapReduce se limita al procesamiento por lotes.
- Spark tiene RDD (conjunto de datos distribuidos resilientes) que nos brinda operadores de alto nivel, pero en Map reduce necesitamos codificar todas y cada una de las operaciones, lo que lo hace relativamente difícil.
- Spark puede procesar gráficos y es compatible con la herramienta de aprendizaje automático.
- A continuación se muestra la diferencia entre el ecosistema MapReduce vs Spark.
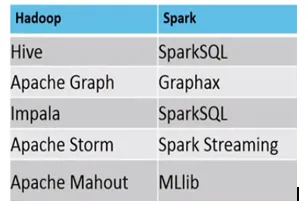
Ejemplo, donde MapReduce vs Spark son adecuados, son los siguientes
Spark: detección de fraude con tarjeta de crédito
MapReduce: Elaboración de informes regulares que requieren la toma de decisiones.
Tabla de comparación MapReduce vs Spark
| Bases de comparación | Mapa reducido | Chispa - chispear |
| Marco de referencia | Un marco de código abierto para escribir datos en HDFS y procesar datos estructurados y no estructurados presentes en HDFS. | Un marco de código abierto para un procesamiento de datos más rápido y de uso general. |
| Velocidad | Map-Reduce procesa los datos (lecturas y escrituras) del disco para que la filtración sea lenta en comparación con Spark. | Spark es al menos 10 veces más rápido en el disco y 100 veces más rápido en la memoria que el de Map Reduce. |
| Dificultad | Necesitamos codificar / manejar cada proceso. | Con la disponibilidad de RDD (conjunto de datos distribuidos resilientes), es fácil de programar. |
| Tiempo real | No es adecuado para la transacción OLTP solo para el modo Batch | Puede manejar el procesamiento en tiempo real. Usando SPARK Streaming. |
| Latencia | Marco informático de latencia de alto nivel | Marco informático de latencia de bajo nivel. |
| Tolerancia a fallos | Los demonios maestros comprueban los latidos del corazón de los demonios esclavos y, en caso de que los demonios esclavos fallen, los demonios maestros reprograman todas las operaciones pendientes y en progreso a otro esclavo. | Los RDD proporcionan tolerancia a fallas a SPARK. Se refieren al conjunto de datos presente en el almacenamiento externo como (HDFS, HBase) y funcionan en paralelo. |
| Programador | En Map Reduce usamos un programador externo como Oozie. | A medida que SPARK trabaja con la computación en memoria, actúa como su propio programador. |
| Costo | Map Reduce es comparativamente más barato en comparación con SPARK. | Como funciona en la memoria, requiere mucha RAM, por lo que es relativamente más costoso. |
| Plataforma desarrollada en | Map Reduce ha sido desarrollado utilizando Java. | SPARK ha sido desarrollado utilizando Scala. |
| Idioma soportado | Map Reduce básicamente admite C, C ++, Ruby, Groovy, Perl, Python. | Spark es compatible con Scala, Java, Python, R, SQL. |
| Soporte SQL | Map Reduce ejecuta consultas utilizando Hive Query Language. | Spark tiene su propio lenguaje de consulta conocido como Spark SQL. |
| Escalabilidad | En Map Reduce podemos agregar hasta n número de nodos. El mayor clúster de Hadoop tiene 14000 nodos. | En Spark también podemos agregar n número de nodos. El clúster Spark más grande tiene 8000 nodos. |
| Aprendizaje automático | Map Reduce admite la herramienta Apache Mahout para el aprendizaje automático. | Spark admite la herramienta MLlib para el aprendizaje automático. |
| Almacenamiento en caché | Map reduce no puede almacenar en caché los datos de la memoria, por lo que no es tan rápido en comparación con Spark. | Spark almacena en caché los datos en memoria para futuras iteraciones, por lo que es muy rápido en comparación con Map Reduce. |
| Seguridad | Map Reduce admite más proyectos y características de seguridad en comparación con Spark | La seguridad contra chispas aún no ha madurado como la de Map Reduce |
Conclusión - MapReduce vs Spark
Según la diferencia anterior entre MapReduce y Spark, está bastante claro que SPARK es un motor informático mucho más avanzado en comparación con Map Reduce. Spark es compatible con cualquier tipo de formato de archivo y también bastante más rápido que Map Reduce. La chispa también tiene capacidades de procesamiento gráfico y aprendizaje automático.
Por un lado, Map Reduce se limita al procesamiento por lotes y, por otro, Spark puede realizar cualquier tipo de procesamiento (por lotes, interactivo, iterativo, de transmisión, gráfico). Debido a la gran compatibilidad, Spark es el favorito de Data Scientist y, por lo tanto, reemplaza Map Reduce y crece rápidamente. Pero aún así necesitamos almacenar los datos en HDFS y en algún momento también podemos necesitar HBase. Por lo tanto, necesitamos ejecutar Spark y Hadoop para obtener lo mejor.
Artículos recomendados:
Esta ha sido una guía para MapReduce vs Spark, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- 7 cosas importantes sobre Apache Spark (Guía)
- Hadoop vs Apache Spark: cosas interesantes que debes saber
- Apache Hadoop vs Apache Spark | ¡Las 10 mejores comparaciones que debes conocer!
- ¿Cómo funciona MapReduce?
- Confluencia de tecnología y análisis de negocios