
Introducción al embolsado y alza
El embolsado y el refuerzo son los dos métodos de conjunto populares. Entonces, antes de comprender Bagging and Boosting, tengamos una idea de lo que es el aprendizaje conjunto. Es la técnica de usar múltiples algoritmos de aprendizaje para entrenar modelos con el mismo conjunto de datos para obtener una predicción en el aprendizaje automático. Después de obtener la predicción de cada modelo, utilizaremos técnicas de promediación de modelos como promedio ponderado, varianza o votación máxima para obtener la predicción final. Este método tiene como objetivo obtener mejores predicciones que el modelo individual. Esto da como resultado una mayor precisión, evitando el sobreajuste y reduce el sesgo y la covarianza. Dos métodos de conjunto populares son:
- Ensacado (agregación de Bootstrap)
- Impulsar
Harpillera:
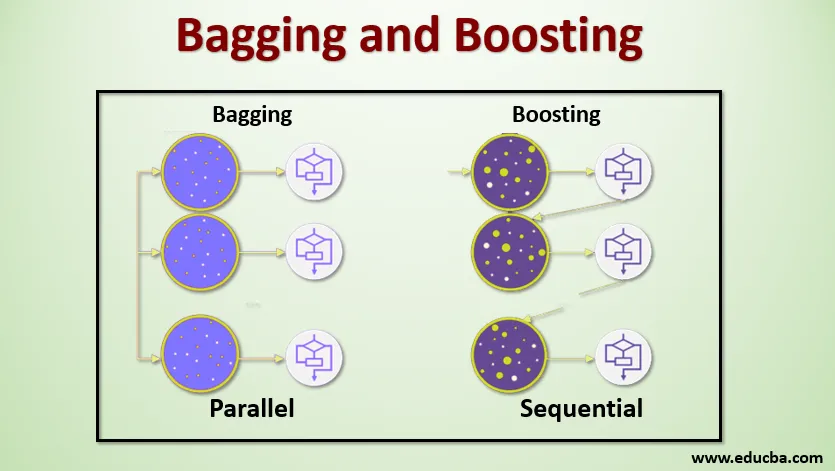
El ensacado, también conocido como Bootstrap Aggregating, se utiliza para mejorar la precisión y hace que el modelo sea más general al reducir la variación, es decir, al evitar el sobreajuste. En esto, tomamos múltiples subconjuntos del conjunto de datos de entrenamiento. Para cada subconjunto, tomamos un modelo con los mismos algoritmos de aprendizaje como árbol de decisión, regresión logística, etc. para predecir la salida del mismo conjunto de datos de prueba. Una vez que tenemos una predicción de cada modelo, usamos una técnica de promedio de modelo para obtener la salida de predicción final. Una de las técnicas famosas utilizadas en Bagging es Random Forest . En el bosque aleatorio, utilizamos múltiples árboles de decisión.
Impulso :
El refuerzo se usa principalmente para reducir el sesgo y la varianza en una técnica de aprendizaje supervisado. Se refiere a la familia de un algoritmo que convierte a los alumnos débiles (base de aprendizaje) en alumnos fuertes. El alumno débil son los clasificadores que son correctos solo hasta cierto punto con la clasificación real, mientras que los alumnos fuertes son los clasificadores que están bien correlacionados con la clasificación real. Pocas técnicas famosas de refuerzo son AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Entonces, ahora sabemos qué son las bolsas y el impulso y cuáles son sus roles en Machine Learning.
Trabajo de embolsado y refuerzo
Ahora comprendamos cómo funciona el embolsado y el refuerzo:
Harpillera
Para comprender el funcionamiento de Bagging, supongamos que tenemos un número N de modelos y un conjunto de datos D. Donde m es el número de datos yn es el número de características en cada dato. Y se supone que debemos hacer una clasificación binaria. Primero, dividiremos el conjunto de datos. Por ahora, dividiremos este conjunto de datos en entrenamiento y conjunto de pruebas solamente. Llamemos al conjunto de datos de entrenamiento como donde está el número total de ejemplos de entrenamiento.
Tome una muestra de registros del conjunto de entrenamiento y úselo para entrenar el primer modelo, digamos m1. Para el siguiente modelo, m2 remuestrea el conjunto de entrenamiento y toma otra muestra del conjunto de entrenamiento. Haremos lo mismo para el número N de modelos. Dado que estamos volviendo a muestrear el conjunto de datos de entrenamiento y tomando las muestras de él sin eliminar nada del conjunto de datos, es posible que tengamos dos o más registros de datos de entrenamiento comunes en múltiples muestras. Esta técnica de remuestreo del conjunto de datos de entrenamiento y de proporcionar la muestra al modelo se denomina Muestreo de fila con reemplazo. Supongamos que hemos entrenado cada modelo y ahora queremos ver la predicción en los datos de prueba. Dado que estamos trabajando en la salida de clasificación binaria puede ser 0 o 1. El conjunto de datos de prueba se pasa a cada modelo, y obtenemos una predicción de cada modelo. Digamos que de N modelos más de N / 2 predijeron que era 1, por lo tanto, al usar la técnica de promedio del modelo como el voto máximo, podemos decir que la salida pronosticada para los datos de prueba es 1.
Impulsar
Al impulsar, tomamos registros del conjunto de datos y los pasamos secuencialmente a los aprendices base, aquí los aprendices base pueden ser cualquier modelo. Supongamos que tenemos m número de registros en el conjunto de datos. Luego pasamos algunos registros al alumno base BL1 y lo entrenamos. Una vez que el BL1 se entrena, pasamos todos los registros del conjunto de datos y vemos cómo funciona el alumno Base. Para todos los registros que el alumno base clasifica incorrectamente, solo los tomamos y se los pasamos a otro alumno base, digamos BL2, y simultáneamente pasamos los registros incorrectos clasificados por BL2 para entrenar a BL3. Esto continuará a menos y hasta que especifiquemos un número específico de modelos básicos de alumnos que necesitamos. Finalmente, combinamos el resultado de estos aprendices básicos y creamos un alumno fuerte, como resultado, el poder de predicción del modelo mejora. Okay. Así que ahora sabemos cómo funcionan los embolsados y los refuerzos.
Ventajas y desventajas de embolsar y aumentar
A continuación se presentan las principales ventajas y desventajas.
Ventajas de embolsar
- La mayor ventaja del embolsado es que múltiples estudiantes débiles pueden funcionar mejor que un solo estudiante fuerte.
- Proporciona estabilidad y aumenta la precisión del algoritmo de aprendizaje automático que se utiliza en la clasificación estadística y la regresión.
- Ayuda a reducir la varianza, es decir, evita el sobreajuste.
Desventajas de embolsar
- Puede dar lugar a un alto sesgo si no se modela correctamente y, por lo tanto, puede dar lugar a un ajuste insuficiente.
- Como debemos usar múltiples modelos, se vuelve computacionalmente costoso y puede no ser adecuado en varios casos de uso.
Ventajas de impulsar
- Es una de las técnicas más exitosas para resolver los problemas de clasificación de dos clases.
- Es bueno para manejar los datos faltantes.
Desventajas de impulsar
- Impulsar es difícil de implementar en tiempo real debido a la mayor complejidad del algoritmo.
- La alta flexibilidad de estas técnicas da como resultado un número múltiple de parámetros que tienen un efecto directo sobre el comportamiento del modelo.
Conclusión
La conclusión principal es que Bagging and Boosting es un paradigma de aprendizaje automático en el que utilizamos múltiples modelos para resolver el mismo problema y obtener un mejor rendimiento. Y si combinamos adecuadamente a los alumnos débiles, podemos obtener un modelo estable, preciso y robusto. En este artículo, he dado una descripción básica de Bagging and Boosting. En los próximos artículos, conocerá las diferentes técnicas utilizadas en ambos. Finalmente, concluiré recordándoles que Bagging and Boosting se encuentran entre las técnicas más utilizadas de aprendizaje en conjunto. El verdadero arte de mejorar el rendimiento radica en su comprensión de cuándo usar qué modelo y cómo ajustar los hiperparámetros.
Artículos recomendados
Esta es una guía para embolsar y aumentar. Aquí discutimos la Introducción al embolsado y al refuerzo y está trabajando junto con las ventajas y desventajas. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Introducción a las técnicas de conjunto
- Categorías de algoritmos de aprendizaje automático
- Algoritmo de refuerzo de gradiente con código de muestra
- ¿Qué es el algoritmo de refuerzo?
- ¿Cómo crear un árbol de decisión?