

Introducción a los comandos de Hive
El comando Hive es una herramienta de infraestructura de almacenamiento de datos que se encuentra en la parte superior de Hadoop para resumir Big data. Procesa datos estructurados. Facilita la consulta y el análisis de datos. El comando Hive también se llama "esquema de lectura"; Hive no verifica los datos cuando se carga, la verificación ocurre solo cuando se emite una consulta. Esta propiedad de Hive lo hace rápido para la carga inicial. Es como copiar o simplemente mover un archivo sin poner restricciones ni controles. La colmena fue desarrollada por primera vez por Facebook. Apache Software Foundation lo retomó más tarde y lo desarrolló aún más.
Aquí están los componentes del comando Hive:
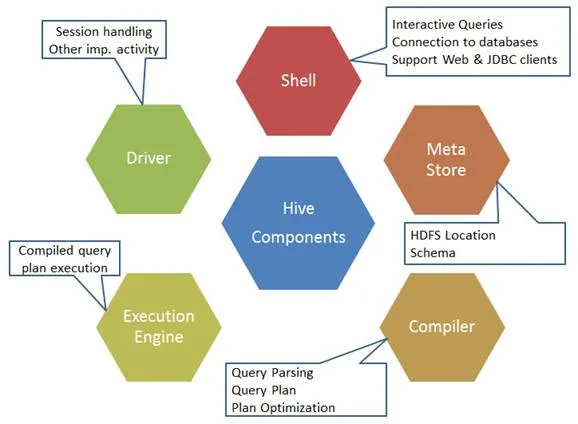
Fig. 1. Componentes de la colmena
https://www.developer.com/
Estas son las características del comando Hive que se enumeran a continuación:
- Los almacenes de colmena son conjuntos de datos sin procesar y procesados en Hadoop.
- Está diseñado para el procesamiento de transacciones en línea (OLTP). OLTP son los sistemas que facilitan datos de gran volumen en muy poco tiempo sin depender del servidor único.
- Es rápido, escalable y confiable.
- El lenguaje de consulta de tipo SQL proporcionado aquí se llama HiveQL o HQL. Esto facilita las tareas de ETL y otros análisis.
Fig 2. Propiedades de la colmena
Imágenes de fuentes: - Google
También hay algunas limitaciones del comando Hive, que se enumeran a continuación:
- Hive no admite subconsultas.
- Hive seguramente admite la sobreescritura, pero desafortunadamente, no admite la eliminación y las actualizaciones.
- Hive no está diseñado para OLTP, pero se usa para ello.
Para ingresar al shell interactivo de la colmena:
$ HIVE_HOME / bin / hive
Comandos básicos de la colmena
-
Crear
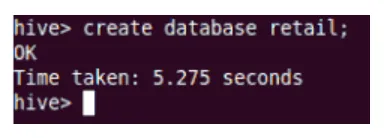
Esto creará la nueva base de datos en Hive.
-
soltar
La caída eliminará una tabla de Hive
-
Alterar
El comando Alter le ayudará a renombrar la tabla o las columnas de la tabla.
Por ejemplo:
colmena> ALTERAR TABLA empleado RENOMBRAR A empleado1;
-
mostrar
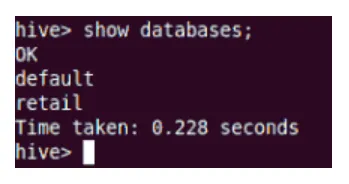
El comando Show mostrará todas las bases de datos que residen en Hive.
-
Describir
El comando Describir le ayudará con la información sobre el esquema de la tabla.
Comandos intermedios de la colmena
La colmena divide una tabla en particiones relacionadas en función de las columnas. Usando estas particiones, se hace más fácil consultar datos. Estas particiones se dividen aún más en cubos, para ejecutar consultas de manera eficiente en los datos.
En otras palabras, los depósitos distribuyen datos en el conjunto de clústeres calculando el código hash de la clave mencionada en la consulta.
-
Agregar partición
Agregar partición se puede lograr alterando la tabla. Supongamos que tiene la tabla "EMP", con campos como Id, Nombre, Salario, Departamento, Designación y yoj.
colmena> ALTERAR TABLA empleado
> AGREGAR PARTICIÓN (año = '2012')
ubicación '/ 2012 / part2012';
-
Renombrar partición
colmena> ALTERAR TABLA PARTICIÓN DE EMPLEADOS (año = '1203')
RENOMBRAR A LA PARTICIÓN (Yoj = '1203');
-
Partición de caída
colmena> CAMBIAR TABLA de empleados (SI EXISTE)
> PARTICIÓN (año = '1203');
-
Operadores relacionales
Los operadores relacionales consisten en un cierto conjunto de operadores, que ayudan a obtener información relevante.
Por ejemplo: Digamos que su tabla "EMP" se ve así:
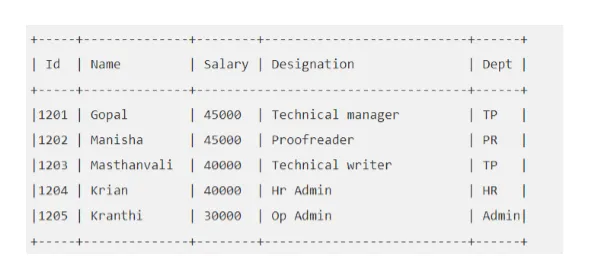
Ejecutemos la consulta Hive que nos traerá al empleado cuyo salario sea mayor a 30000.
colmena> SELECCIONAR * DESDE EMP DONDE Salario> = 40000;
-
Operadores aritméticos
Estos son operadores que ayudan en la ejecución de operaciones aritméticas en los operandos y, a su vez, siempre devuelven tipos de números.
Por ejemplo: para agregar dos números como 22 y 33
colmena> SELECCIONE 22 + 33 AGREGAR DE temp;
-
Operador lógico
Estos operadores deben ejecutar operaciones lógicas, que a cambio siempre devuelven Verdadero / Falso.
colmena> SELECCIONAR * DE EMP DONDE Salario> 40000 && Dept = TP;
Comandos avanzados de la colmena
-
Ver
Ver el concepto en Hive es similar al de SQL. La vista se puede crear al momento de ejecutar una instrucción SELECT.
Ejemplo:
colmena> CREAR VISTA EMP_30000 AS
SELECCIONAR * DESDE EMP
DONDE salario> 30000;
-
Cargando datos en la tabla
Colmena> Cargar datos en ruta local '/home/hduser/Desktop/AllStates.csv' en los estados de la tabla;
Aquí "Estados" es la tabla ya creada en Hive.
https://www.tutorialspoint.com/hive/
Hive tiene algunas funciones integradas que lo ayudan a obtener su resultado de una mejor manera.
Como redondo, piso, BIGINT etc.
-
Unirse
La cláusula Join puede ayudar a unir dos tablas basadas en el mismo nombre de columna.
Ejemplo:
colmena> SELECCIONAR c.ID, c.NAME, c.AGE, o.AMOUNT
DE CLIENTES c ÚNETE A PEDIDOS o
ENCENDIDO (c.ID = o.CUSTOMER_ID);
Hive admite todo tipo de combinaciones: combinación externa izquierda, combinación externa derecha, combinación externa completa.
Consejos y trucos para usar los comandos de la colmena
Hive hace que el procesamiento de datos sea tan fácil, directo y extensible, que el usuario presta menos atención para optimizar las consultas de Hive. Pero prestar atención a algunas cosas al escribir consultas de Hive seguramente traerá un gran éxito en la administración de la carga de trabajo y en el ahorro de dinero. A continuación hay algunos consejos al respecto:
- Particiones y cubos: Hive es una gran herramienta de datos, que puede consultar en grandes conjuntos de datos. Sin embargo, escribir la consulta sin comprender el dominio puede generar grandes particiones en Hive.
Si el usuario conoce el conjunto de datos, las columnas relevantes y muy utilizadas podrían agruparse en la misma partición. Esto ayudará a ejecutar la consulta de manera más rápida e ineficiente.
En definitiva el no. de mapeador y operaciones de E / S también se reducirán.
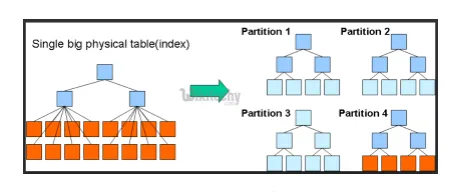
Fig 3. Particionamiento
Imágenes de fuentes: imagen de Google
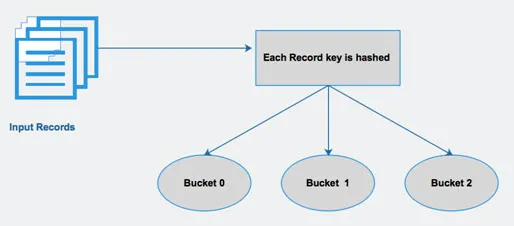
Higo 4 Bucketing
Imágenes de fuentes: - imagen de Google
- Ejecución paralela: Hive ejecuta la consulta en varias etapas. En algunos casos, estas etapas pueden depender de otras etapas, por lo tanto, no puede comenzar, una vez que se completa la etapa anterior. Sin embargo, las tareas independientes pueden ejecutarse en paralelo para ahorrar tiempo de ejecución general. Para habilitar la ejecución paralela en Hive:
establecer hive.exec.parallel = true;
Por lo tanto, esto mejorará la utilización del clúster.
- Muestreo en bloque: los datos de muestreo de una tabla permitirán explorar consultas sobre datos.
A pesar del rechazo, preferimos muestrear el conjunto de datos más al azar. El muestreo en bloque viene con varias sintaxis potentes, que ayudan a muestrear los datos de una manera diferente.
El muestreo se puede usar para encontrar aprox. información del conjunto de datos como la distancia promedio entre el origen y el destino.
Consultar el 1% de los grandes datos dará la respuesta perfecta. La exploración se vuelve mucho más fácil y efectiva.
Conclusión: comandos de Hive
Hive es una abstracción de nivel superior sobre HDFS, que proporciona un lenguaje de consulta flexible. Ayuda a consultar y procesar datos de una manera más fácil.
Hive puede combinarse con otros elementos de Big Data para aprovechar su funcionalidad de manera completa.
Artículos recomendados
Esta ha sido una guía para los comandos de Hive. Aquí hemos discutido los comandos de Hive básicos y avanzados y algunos comandos de Hive inmediatos. También puede consultar el siguiente artículo para obtener más información:
- Preguntas de la entrevista de la colmena
- Hive VS Hue - Las 6 mejores comparaciones útiles
- Comandos de Tableau
- Comandos de Adobe Photoshop
- Uso de la función ORDER BY en Hive
- Descargue e instale Hive paso a paso