
¿Qué es una colmena?
Antes de comprender los tipos de datos de la colmena primero estudiaremos la colmena. Hive es una técnica de almacenamiento de datos de Hadoop. Hadoop es el segmento de almacenamiento y procesamiento de datos de la plataforma Big data. Hive mantiene su posición para las técnicas de procesamiento de datos secuelas. Al igual que otros entornos secuentes, se puede llegar a la sección mediante consultas secuelas. Las principales ofertas de Hive son el análisis de datos, las consultas ad-hoc y el resumen de los datos almacenados desde una perspectiva de latencia, las consultas son mucho mayores.
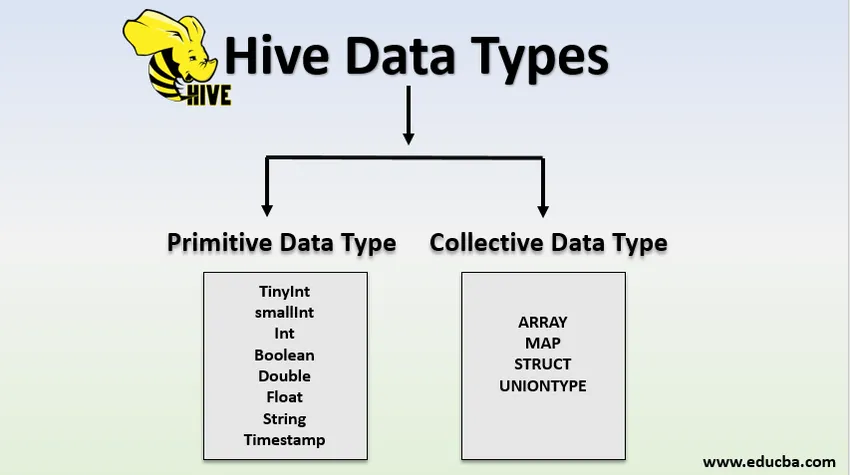
Tipos de datos de la colmena
Los tipos de datos se clasifican en dos tipos:
- Tipos de datos primitivos
- Tipos de datos colectivos
1. Tipos de datos primitivos
Los medios primitivos eran antiguos y antiguos. Todos los tipos de datos enumerados como primitivos son heredados. Las áreas de tipos de datos primitivos importantes se enumeran a continuación:
| Tipo | Tamaño (byte) | Ejemplo |
| TinyInt | 1 | 20 |
| SmallInt | 2 | 20 |
| En t | 4 4 | 20 |
| Empezando | 8 | 20 |
| Booleano | Booleano verdadero / falso | FALSO |
| Doble | 8 | 10.2222 |
| Flotador | 4 4 | 10.2222 |
| Cuerda | Secuencia de caracteres | A B C D |
| Marca de tiempo | Entero / flotante / cadena | 3/02/2012 12: 34: 56: 1234567 |
| Fecha | Entero / flotante / cadena | 2/3/2019 |
Los tipos de datos de Hive se implementan utilizando JAVA
Ej: Java Int se usa para implementar el tipo de datos Int aquí.
- Las matrices de caracteres no son compatibles con HIVE.
- Hive se basa en delimitadores para separar sus campos, la coordinación con Hadoop permite aumentar el rendimiento de escritura y el rendimiento de lectura.
- No se espera especificar la longitud de cada columna en la base de datos de la colmena.
- Los literales de cadena se pueden articular dentro de comillas dobles (") comillas simples (').
- En una versión más nueva de la colmena, se introducen los tipos Varchar y forman un especificador de intervalo de (entre 1 y 65535), por lo que para una cadena de caracteres, esto actúa como la mayor longitud de valor que puede acomodar. Cuando se inserta un valor que excede esta longitud, los elementos más a la derecha de esos valores se truncan. La longitud del carácter es la resolución con la figura de los puntos de código controlados por la cadena de caracteres.
- Todos los literales enteros (TINYINT, SMALLINT, BIGINT) se consideran básicamente tipos de datos INT, y solo la longitud excede el nivel int real que se transmuta en BIGINT o en cualquier otro tipo respectivo.
- Los literales decimales ofrecen valores definidos y una colección superior para valores de punto flotante en comparación con el tipo DOBLE. Aquí los valores numéricos se almacenan en su forma exacta, pero en el caso del doble, no se almacenan exactamente como valores numéricos.
Proceso de conversión de valor de fecha
| Casting Realizado | Resultado |
| elenco (fecha como fecha) | Mismo valor de fecha |
| emitir (marca de tiempo como fecha) | Se utiliza una zona horaria local para evaluar los valores de Año / mes / fecha aquí y se imprime en la salida. |
| cast (cadena como fecha) | Se solicitará un valor de fecha correspondiente como resultado de esta conversión, pero debemos asegurarnos de que la cadena tenga el formato 'AAAA-MM-DD'. Se devolverá un valor nulo cuando el valor de la cadena no pueda hacer una coincidencia válida. |
| reparto (fecha como marca de tiempo) | Según la zona horaria local actual, se creará un valor de marca de tiempo para este proceso de conversión |
| cast (fecha como cadena) | AAAA-MM-DD se forma para el valor de año / mes / fecha y la salida será de formato de cadena. |
2. Tipos de datos de recopilación
Hay cuatro tipos de datos de recopilación en la colmena, que también se denominan tipos de datos complejos.
- FORMACIÓN
- MAPA
- ESTRUCT
- TIPO DE UNIÓN
1. ARRAY: una secuencia de elementos de un tipo común que puede indexarse y el valor del índice comienza desde cero.
Código:
array ('anand', 'balaa', 'praveeen');
2. MAP: Estos son elementos que se declaran y recuperan usando pares clave-valor.
Código:
'firstvalue' -> 'balakumaran', 'lastvalue' -> 'pradeesh' is represented as map('firstvalue', 'balakumaran', 'last', 'PG'). Now 'balakumaran ' can be retrived with map('first').
3. STRUCT: Al igual que en C, la estructura es un tipo de datos que acumula un conjunto de campos que están etiquetados y pueden ser de cualquier otro tipo de datos.
Código:
For a column D of type STRUCT (Y INT; Z INT) the Y field can be retrieved by the expression DY
4. UNIONTYPE: Union puede contener cualquiera de los tipos de datos especificados.
Código:
CREATE TABLE test(col1 UNIONTYPE ) CREATE TABLE test(col1 UNIONTYPE )
Salida:

A continuación se enumeran varios delimitadores utilizados en tipos de datos complejos.
| Delimitador | Código | Descripción |
| \norte | \norte | Registro o delimitador de fila |
| A (Ctrl + A) | \ 001 | Delimitador de campo |
| B (Ctrl + B) | \ 002 | Estructuras y matrices |
| C (Ctrl + C) | \ 003 | MAP's |
Ejemplo de tipos de datos complejos
A continuación se muestran los ejemplos de tipos de datos complejos:
1. CREACIÓN DE MESA
Código:
create table store_complex_type (
emp_id int,
name string,
local_address STRUCT,
country_address MAP,
job_history array)
row format delimited fields terminated by ', '
collection items terminated by ':'
map keys terminated by '_';
2. DATOS DE LA TABLA DE MUESTRAS
Código:
100, Shan, 4th : CHN : IND : 600101, CHENNAI_INDIA, SI : CSC
101, Jai, 1th : THA : IND : 600096, THANJAVUR_INDIA, HCL : TM
102, Karthik, 5th : AP : IND : 600089, RENIKUNDA_INDIA, CTS : HCL
3. CARGANDO LOS DATOS
Código:
load data local inpath '/home/cloudera/Desktop/Hive_New/complex_type.txt' overwrite into table store_complex_type;
4. VER LOS DATOS
Código:
select emp_id, name, local_address.city, local_address.zipcode, country_address('CHENNAI'), job_history(0) from store_complex_type where emp_id='100';
Conclusión: tipos de datos de colmena
Al ser un DB relacional y, sin embargo, una Sequel conecta, el HIVE ofrece todas las propiedades clave de las bases de datos SQL habituales de una manera muy sofisticada, lo que la convierte en una de las unidades de procesamiento de datos estructurados más eficientes de Hadoop.
Artículos recomendados
Esta es una guía para el tipo de datos de Hive. Aquí discutimos dos tipos de tipos de datos de colmena con ejemplos adecuados. También puede consultar nuestros otros artículos relacionados para obtener más información:
- ¿Qué es una colmena?
- Alternativas de colmena
- Funciones incorporadas de la colmena
- Preguntas de la entrevista de la colmena
- Tipos de datos PL / SQL
- Ejemplos de funciones integradas de Python
- Diferentes tipos de datos SQL con ejemplos