

Preguntas y respuestas de la entrevista Splunk - Introducción
Así que finalmente ha encontrado el trabajo de sus sueños en Splunk, pero se pregunta cómo descifrar la entrevista de Splunk y cuáles podrían ser las posibles preguntas de la entrevista de Splunk para 2018. Cada entrevista es diferente y el alcance de un trabajo también es diferente. Teniendo esto en cuenta, hemos diseñado las preguntas y respuestas más comunes de la entrevista Splunk para 2018 para ayudarlo a tener éxito en su entrevista.A continuación se encuentran las preguntas y respuestas más útiles de la entrevista Splunk. Estas preguntas principales se dividen en dos partes:
Parte 1 - Preguntas de la entrevista de Splunk (Básico)
Esta primera parte cubre preguntas y respuestas básicas de la entrevista Splunk.
1. ¿Qué es Splunk? ¿Por qué se usa Splunk para analizar los datos de la máquina?
Responder:
Una de las herramientas de análisis más utilizadas es Microsoft Excel y el inconveniente es que Excel solo puede cargar hasta 1048576 filas y los datos de la máquina son generalmente enormes. Splunk es útil para tratar datos generados por máquina (big data), los datos de servidores, dispositivos o redes se pueden cargar fácilmente en Splunk y se pueden analizar para verificar cualquier visibilidad de amenaza, cumplimiento, seguridad, etc. También se puede usar para monitoreo de aplicaciones.
2.Explica cómo funciona Splunk
Responder:
Estas son las preguntas comunes de la entrevista Splunk formuladas en una entrevista. Los datos se cargan en Splunk utilizando el reenviador que actúa como una interfaz entre el entorno de Splunk y el mundo exterior, luego estos datos se envían a un indexador donde los datos se almacenan localmente o en una nube. El indexador indexa los datos de la máquina y los almacena en el servidor. Search Head es la GUI que Splunk proporciona para buscar y analizar (busca, visualiza, analiza y realiza otras funciones) los datos.
El servidor de implementación gestiona todos los componentes de Splunk, como el indexador, el reenviador y el cabezal de búsqueda en el entorno de Splunk. 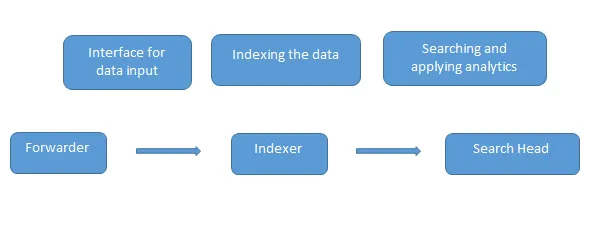
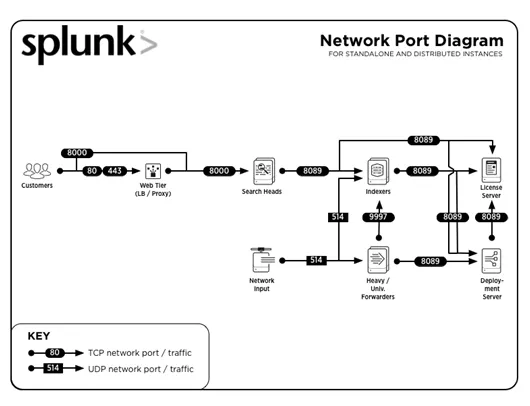
3. ¿Cuáles son los números de puerto comunes utilizados por Splunk?
Respuesta :
Los números de puertos comunes en los que se ejecutan los servicios (de forma predeterminada) son:
| Servicio | Número de puerto |
| API de gestión / REST | 8089 |
| Cabezal de búsqueda / indexador | 8000 |
| Cabeza de búsqueda | 8065, 8191 |
| Nodo par del clúster indexador / miembro principal del clúster de búsqueda | 9887 |
| Indexador | 9997 |
| Indexador / Reenviador | 514 |
Pasemos a las siguientes preguntas de la entrevista de Splunk.
4. ¿Por qué usar solo Splunk?
Responder:
Hay muchas alternativas para Splunk que le dan mucha competencia, algunas de ellas son las siguientes:
• ELK / Logstash (código abierto)
Elasticsearch se usa para buscar, es como el cabezal de búsqueda en Splunk, el alijo de registro es para la recolección de datos que es similar al reenviador utilizado en Splunk, y Kibana se usa para la visualización de datos (el cabezal de búsqueda hace lo mismo en Splunk)
• Graylog (código abierto con versión comercial)
Graylog es otra herramienta que fue nombrada el año pasado con su lanzamiento 1.0. Similar a la pila ELK, Graylog también tiene diferentes componentes, usa Elasticsearch como su componente principal, pero los datos se almacenan en Mongo DB y usan Apache Kafka. Tiene dos versiones, una versión central que está disponible de forma gratuita y la versión empresarial que viene con funciones como el archivo.
• Sumo Logic (servicio en la nube)
Entonces, lo que hace que Splunk sea el mejor de todos es que Splunk viene como un paquete único del recopilador de datos, el almacenamiento y la herramienta de análisis incorporada. Splunk también es escalable y proporciona soporte / ayuda profesional para su edición empresarial.
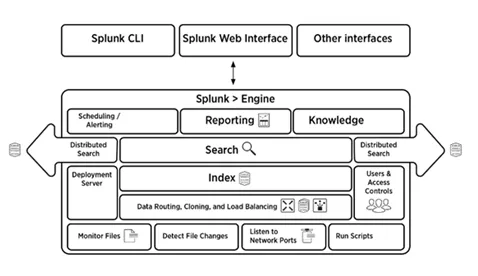
5. Brevemente, explique la arquitectura Splunk
Responder:
La siguiente imagen ofrece una breve descripción de la arquitectura Splunk y sus componentes.
Parte 2 - Preguntas de la entrevista de Splunk (Avanzado)
Veamos ahora las preguntas avanzadas de la entrevista de Splunk.
6. ¿Cuáles son los componentes de la arquitectura Splunk?
Responder:
Hay cuatro componentes en la arquitectura Splunk. Son:
- Indexador: indexa los datos de la máquina
- Reenviador: reenvía registros al índice
- Cabezal de búsqueda: proporciona GUI para buscar
- Servidor de implementación: administra los componentes de Splunk (indexador, reenviador y cabezal de búsqueda) en un entorno distribuido
7. Dé algunos casos de uso de objetos de conocimiento.
Respuesta :
Estas son las preguntas frecuentes de la entrevista Splunk en una entrevista. Los objetos de conocimiento se pueden usar en muchos dominios. Pocos ejemplos son:
Monitoreo de aplicaciones: Esto se puede usar para monitorear aplicaciones en tiempo real con alertas configuradas que notificarán a los administradores / usuarios cuando una aplicación falla.
Seguridad física: en el caso de una inundación / volcánica, etc., los datos se pueden utilizar para obtener información si su organización está tratando con dichos datos.
Seguridad de red: puede crear un entorno seguro mediante la inclusión en la lista negra de IP de dispositivos desconocidos, reduciendo así la pérdida de datos en cualquier organización.
Gestión de empleados: el desgaste de los empleados es uno de los desafíos que enfrenta cualquier organización y, durante el período de notificación, se puede realizar un seguimiento de la actividad del empleado para proteger los datos de la organización y así monitorear su actividad y restringir a cualquier otro empleado en el período de notificación para que no haga lo mismo .
8.Explique el factor de búsqueda (SF) y el factor de replicación (RF)
Responder:
Estas son las terminologías que se utilizan en las técnicas de agrupamiento de Splunk. El clúster de indexador es un grupo especialmente configurado de indexadores de Splunk Enterprise que replica datos externos y se utiliza para la recuperación ante desastres.
En términos de la búsqueda de documentación de Splunk, el factor se puede describir como "El número de copias de datos que se pueden buscar que mantiene un clúster indexador. El valor predeterminado del factor de búsqueda es 2 ", mientras que el factor de replicación se define como el número de copias de datos que mantiene el clúster.
El clúster indexador tiene un factor de búsqueda y un factor de replicación, mientras que el clúster del cabezal de búsqueda solo tiene un factor de búsqueda
Pasemos a las siguientes preguntas de la entrevista de Splunk.
9. ¿Qué son los cubos Splunk? Explica el ciclo de vida del cubo.
Responder:
Los directorios en los que se almacenan los datos indexados se conocen como cubos Splunk y estos tienen eventos de cierto período. El ciclo de vida del cubo Splunk incluye cuatro etapas: caliente, templado, frío, congelado y descongelado.
- Caliente : este depósito contiene los datos indexados recientemente y está abierto para escritura.
- Cálido : una vez que los datos caen en el cubo caliente, según sus políticas de datos, se mueven a los cubos calientes
- Frío: la siguiente etapa después del calentamiento es la etapa fría en la que los datos no se pueden editar.
- Congelado : de manera predeterminada, el indexador elimina los datos de los depósitos congelados, pero también se pueden archivar.
- Descongelado : la recuperación de información de archivos archivados (depósito congelado) se conoce como descongelamiento.
10. ¿Por qué debemos usar Splunk Alert? ¿Cuáles son las diferentes opciones al configurar Alertas?
Responder:
El estado de estar atento a cualquier posible error se conoce como alerta y en Splunk, las alertas del entorno pueden surgir debido a fallas de conexión o violaciones de seguridad o incumplimiento de las reglas creadas por el usuario.
Por ejemplo, el envío de notificaciones o un informe de los usuarios que no pudieron iniciar sesión después de utilizar sus tres intentos en un portal para el administrador de la aplicación.
Las diferentes opciones que están disponibles al configurar alertas son:
- Se puede crear un webhook para escribir las alertas en hipchat o GitHub.
- Agregue resultados, .csv o pdf o en línea con el cuerpo del mensaje para que se pueda identificar la causa raíz de la alerta.
- Se pueden crear tickets y se pueden acelerar las alertas desde una máquina o una IP.
Artículo recomendado
Esta ha sido una guía para la Lista de preguntas y respuestas de la entrevista de Splunk para que el candidato pueda tomar medidas enérgicas contra estas preguntas y respuestas de la entrevista de Splunk fácilmente. También puede consultar los siguientes artículos para obtener más información:
- Preguntas de la entrevista del sistema SAS: las 10 preguntas más útiles
- 10 excelentes preguntas de la entrevista de Tableau que debes saber
- Las 15 preguntas y respuestas más exitosas de la entrevista Oracle
- Preguntas de la entrevista de seguridad de red: las más frecuentes y las más frecuentes
- Splunk vs Nagios