

Introducción a Apache Flume
Apache Flume es un marco de ingestión de datos que escribe datos basados en eventos en el sistema de archivos distribuidos de Hadoop. Es un hecho conocido que Hadoop procesa Big data, surge la pregunta de cómo se transmiten los datos generados desde diferentes servidores web a Hadoop File System. La respuesta es Apache Flume. Flume está diseñado para la ingestión de datos de alto volumen a Hadoop de datos basados en eventos.
Considere un escenario en el que la cantidad de servidores web genera archivos de registro y estos archivos de registro deben transmitirse al sistema de archivos Hadoop. Flume recopila esos archivos como eventos y los ingiere a Hadoop. Aunque Flume se usa para transmitir a Hadoop, no existe una regla rígida de que el destino debe ser Hadoop. Flume es capaz de escribir en otros Frameworks como Hbase o Solr.
Arquitectura de canales
En general, la arquitectura Apache Flume se compone de los siguientes componentes:
- Fuente de canal
- Canal de canales
- Lavabo de canal
- Agente de canal
- Evento de canales
Veamos brevemente cada componente Flume
1. Fuente del canal
Una fuente Flume está presente en generadores de datos como Facebook o Twitter. Source recopila datos del generador y los transfiere al Canal Flume en forma de Eventos Flume. Flume admite varios tipos de fuentes, como Avro Flume Source, se conecta en el puerto de Avro y recibe eventos del cliente externo de Avro, Thrift Flume Source, se conecta en el puerto de Thrift y recibe eventos de transmisiones externas del cliente Thrift, Spooling Directory Source y Kafka Flume Source.
2. Canal de canales
Un almacén intermedio que almacena los eventos enviados por Flume Source hasta que Sink los consuma se llama Flume Channel. El canal actúa como un puente intermedio entre Source y Sink. Los canales de canal son de naturaleza transaccional.
Flume proporciona soporte para el canal de archivos y el canal de memoria. El canal de archivo es de naturaleza duradera, lo que significa que una vez que los datos se escriben en el canal no se perderán, aunque si el agente se reinicia. En la memoria, los eventos del canal se almacenan en la memoria, por lo que no es duradero pero sí de naturaleza muy rápida.
3. Sumidero de canal
Un sumidero Flume está presente en repositorios de datos como HDFS, HBase. El sumidero de canales consume eventos del canal y los almacena en tiendas de destino como HDFS. No existe una regla para que el receptor entregue eventos a la Tienda, en cambio, podemos configurarlo de tal manera que un receptor pueda enviar eventos a otro agente. Flume admite varios sumideros como HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
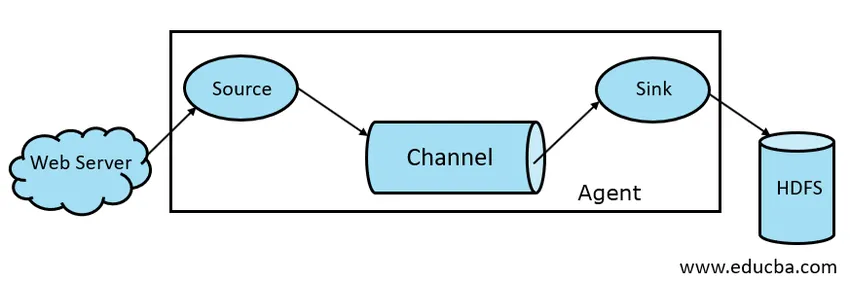
Fig 1.1 Arquitectura básica del canal
4. Agente de flujo
Un agente Flume es un proceso Java de larga duración que se ejecuta en la combinación Fuente - Canal - Sink. El canal puede tener más de un agente. Podemos considerar Flume como una colección de agentes Flume conectados que se distribuyen en la naturaleza.
5. Evento de canales
Un evento es la unidad de datos transportada en Flume . La representación general del objeto de datos en Flume se llama Evento. El evento se compone de una carga útil de una matriz de bytes con encabezados opcionales.
Trabajo de Flume
Un agente Flume es un proceso de Java que consiste en Fuente - Canal - Sumidero en su forma más simple. Source recopila datos del generador de datos en forma de eventos y los entrega al canal. Una fuente puede entregar a múltiples canales según el requisito. El despliegue en abanico es el proceso en el que una sola fuente escribirá en múltiples canales para que puedan enviar a múltiples sumideros.
Un evento es la unidad básica de datos que se transmite en Flume. El canal almacena los datos hasta que Sink los ingiera. Sink recopila los datos del canal y los entrega al almacenamiento de datos centralizado como HDFS o Sink puede reenviar esos eventos a otro agente de Flume según los requisitos.
Flume admite transacciones. Con el fin de lograr confiabilidad, Flume utiliza transacciones separadas de origen a canal y de canal a sumidero. Si los eventos no se entregan, la transacción se revierte y luego se vuelve a entregar.
Para comprender el funcionamiento de Flume, tomemos un ejemplo de la configuración de Flume donde la fuente es el directorio de spooling y el receptor es Hdfs. En este ejemplo, el agente Flume tiene la forma más simple, es decir, topología de fuente única - canal - sumidero que se configura mediante un archivo de propiedades de Java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
En el ejemplo de configuración anterior, el agente es la base con la que definimos otras propiedades. source1 y sink1 y channel1 son los nombres de source, sink y channel respectivamente y sus tipos y ubicaciones también se mencionan en consecuencia.
Ventajas de Apache Flume
- Flume es escalable, confiable y tolerante a fallas por naturaleza. Estas propiedades se analizan en detalle a continuación.
- Escalable: Flume es escalable horizontalmente, es decir, podemos agregar nuevos nodos según nuestros requisitos
- Fiable: Apache Flume tiene soporte para transacciones y garantiza que no se pierdan datos en el proceso de transmisión de datos. Tiene diferentes transacciones de origen a canal y de canal a origen.
- Flume es personalizable y proporciona soporte para varias fuentes y sumideros como Kafka, Avro, el directorio de spooling, Thrift, etc.
- En Flume, una sola fuente puede transmitir datos a múltiples canales y esos canales a su vez transmitirán los datos a múltiples sumideros, por lo que una sola fuente puede transmitir datos a múltiples sumideros. Este mecanismo se llama Fan out. Flume también es compatible con Fan Out.
- Flume proporciona el flujo constante de transmisión de datos, es decir, si la velocidad de lectura de datos aumenta y luego la velocidad de escritura de datos también aumenta.
- Aunque Flume generalmente escribe datos en el almacenamiento centralizado como HDFS o Hbase, podemos configurar Flume según nuestros requisitos, de modo que Sink pueda escribir datos en otro agente. Esto muestra la flexibilidad de Flume
- Apache Flume es de código abierto en la naturaleza.
Conclusión
En este artículo de Flume, los componentes de Flume y el funcionamiento de Flume se analizan en detalle. Flume es una plataforma flexible, confiable y escalable para transmitir datos a una tienda centralizada como HDFS. Su capacidad para integrarse con varias aplicaciones como Kafka, Hdfs, Thrift hace que sea una opción viable para la ingestión de datos.
Artículos recomendados
Esta ha sido una guía para Apache Flume. Aquí discutimos la arquitectura, el trabajo y las ventajas de Apache Flume. También puede echar un vistazo a los siguientes artículos para obtener más información:
- ¿Qué es Apache Flink?
- Diferencia entre Apache Kafka vs Flume
- Arquitectura de Big Data
- Herramientas Hadoop
- Aprenda los diferentes eventos de JavaScript