

Descripción general de las aplicaciones de Kafka
Uno de los campos de tendencia en la industria de TI es Big Data, donde la compañía maneja una gran cantidad de datos de clientes y obtiene información útil que ayuda a sus negocios y brinda a los clientes un mejor servicio. Uno de los desafíos es manejar y transferir estos grandes volúmenes de datos de un extremo a otro para su análisis o procesamiento, aquí es donde Kafka (un sistema de mensajería confiable) entra en juego, lo que ayuda en la recolección y transporte de un gran volumen de datos. en tiempo real. Kafka está diseñado para sistemas distribuidos de alto rendimiento y es una buena opción para aplicaciones de procesamiento de mensajes a gran escala. Kafka es compatible con muchas de las mejores aplicaciones comerciales e industriales de la actualidad. Hay una demanda de profesionales de Kafka que tengan fuertes habilidades y conocimientos prácticos.
En este artículo, aprenderemos sobre Kafka, sus características, casos de uso y comprenderemos algunas aplicaciones notables donde se usa.
¿Qué es kafka?
Apache Kafka se desarrolló en LinkedIn y más tarde se convirtió en un proyecto de código abierto de Apache. Apache Kafka es un sistema de mensajería rápido, tolerante a fallas, escalable y distribuido que permite la comunicación entre dos entidades, es decir, entre productores (generador del mensaje) y consumidores (receptor del mensaje) utilizando temas basados en mensajes y proporciona una plataforma para gestionar todos las alimentaciones de datos en tiempo real.
Las características que hacen que Apache Kafka sea mejor que otros sistemas de mensajería y sean aplicables a los sistemas en tiempo real son su alta disponibilidad, recuperación inmediata y automática de fallas de nodos y admite la entrega de mensajes de baja latencia. Estas características de Apache Kafka ayudan a integrarlo con sistemas de datos a gran escala y lo convierten en un componente ideal para la comunicación. 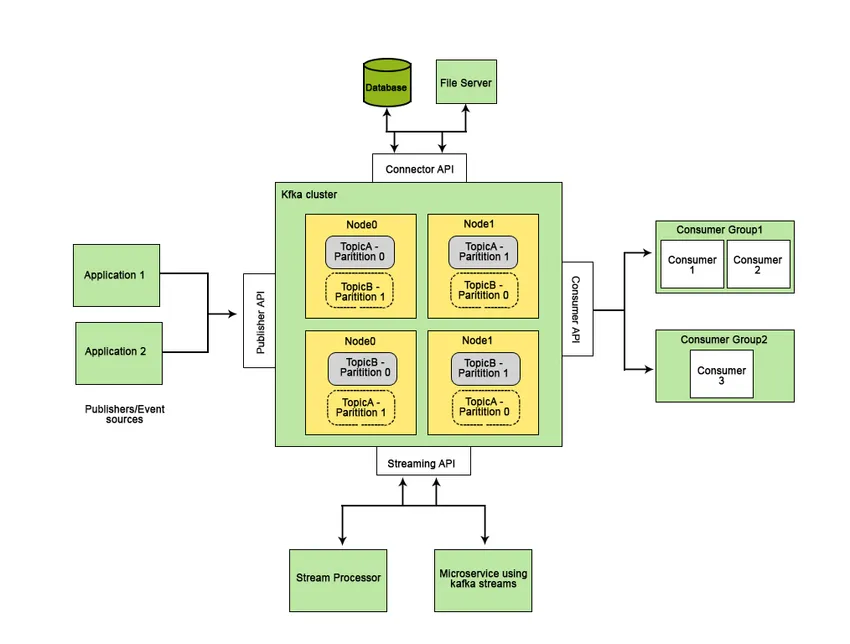
Las mejores aplicaciones de Kafka
En esta sección del artículo, veremos algunos casos de uso populares y ampliamente implementados y veremos una implementación real de Kafka.
Aplicaciones de la vida real
1. Twitter: actividad de procesamiento de flujo
Twitter es una plataforma de redes sociales que utiliza Storm-Kafka (herramienta de procesamiento de flujo de código abierto) como parte de su infraestructura de procesamiento de flujo, donde los datos de entrada (tweets) se consumen para la agregación, las transformaciones y el enriquecimiento para un mayor consumo o seguimiento actividades de procesamiento.
2. LinkedIn: procesamiento de secuencias y métricas
LinkedIn usa Kafka para la transmisión de datos y para la actividad de métricas operativas. LinkedIn utiliza Kafka para sus funciones adicionales, como Newsfeed, para consumir mensajes y realizar análisis de los datos recibidos.
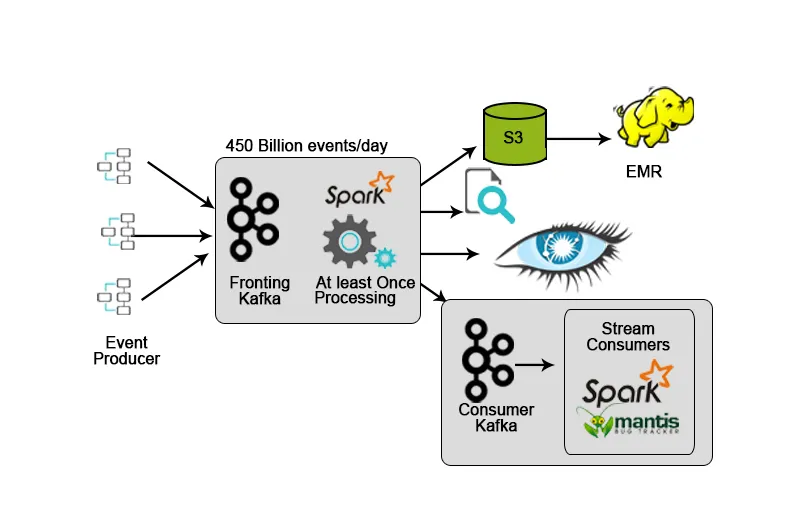
3. Netflix: monitoreo en tiempo real y procesamiento de flujo
Netflix tiene su propio marco de ingestión que descarga los datos de entrada en AWS S3 y utiliza Hadoop para ejecutar análisis de transmisiones de video, actividades de IU, eventos para mejorar la experiencia del usuario y Kafka para la ingestión de datos en tiempo real a través de API.
4. Hotstar: procesamiento de flujo
Hotstar presentó su propia plataforma de gestión de datos, Bifrost, donde Kafka se utiliza para la transmisión de datos, el monitoreo y el seguimiento de objetivos. Debido a su escalabilidad, disponibilidad y capacidades de baja latencia, Kafka fue una opción ideal para manejar los datos que la plataforma hotstar genera diariamente o en cualquier ocasión especial (transmisión en vivo de cualquier concierto, o cualquier partido deportivo en vivo, etc.) donde El volumen de datos aumenta significativamente.
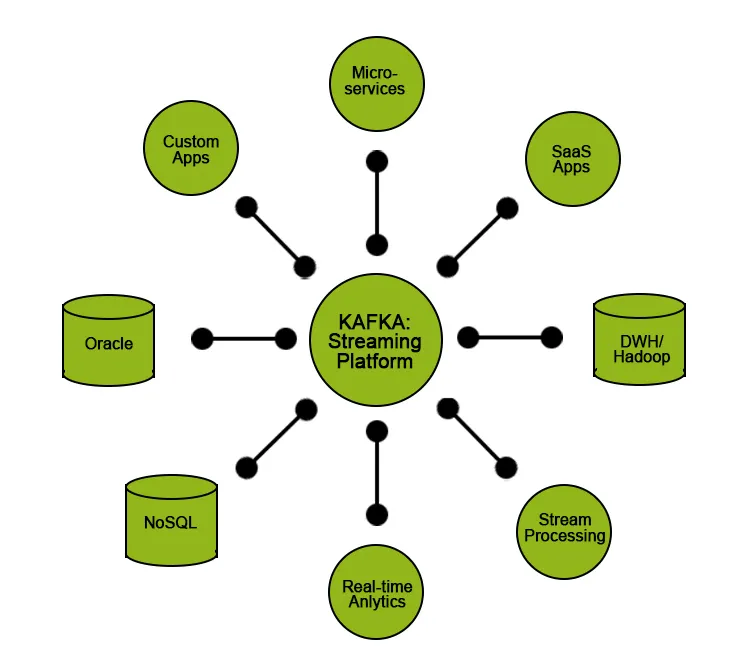
Apache Kafka se usa la mayor parte del tiempo como un bloque de construcción para desarrollar la arquitectura de transmisión de datos. Este tipo de arquitectura se utiliza en aplicaciones como una colección de registros de productos / servidores, análisis de flujo de clics y derivación de información de datos generados por la máquina.
Pero junto con Kafka, necesitamos utilizar recursos o herramientas adicionales para convertir el flujo de datos obtenido en datos significativos que ayuden a obtener información que se pueda utilizar en las decisiones basadas en datos. Por ejemplo, podríamos necesitar generar información a partir de los datos sin procesar obtenidos de dispositivos IoT, o datos obtenidos de plataformas de redes sociales en tiempo real y realizar algunos análisis o procesamientos y mostrarlos a la empresa para tomar mejores decisiones o ayudarlos a mejorar El desempeño de sus servicios.
Para este tipo de casos de uso, nos gustaría transmitir nuestros datos de entrada / datos sin procesar a un lago de datos, donde podemos almacenar nuestros datos y garantizar la calidad de los datos sin obstaculizar el rendimiento.
Una situación diferente, podríamos estar leyendo datos directamente de Kafka, es cuando necesitamos latencia de extremo a extremo extremadamente baja, como alimentar datos a aplicaciones en tiempo real.
Kafka presenta ciertas funcionalidades a sus usuarios:
- Publicar y suscribirse a los datos.
- Almacene los datos en el orden en que se generaron de manera eficiente.
- Procesamiento de datos en tiempo real / sobre la marcha.
Kafka se usa la mayor parte del tiempo para:
- Implementación de canales de transmisión de datos sobre la marcha que obtienen datos de manera confiable entre dos entidades en el sistema.
- Implementación de aplicaciones de transmisión sobre la marcha que transforman, manipulan o procesan las transmisiones de datos.
Casos de uso
A continuación se presentan algunos casos de uso ampliamente implementados de la aplicación Kafka:
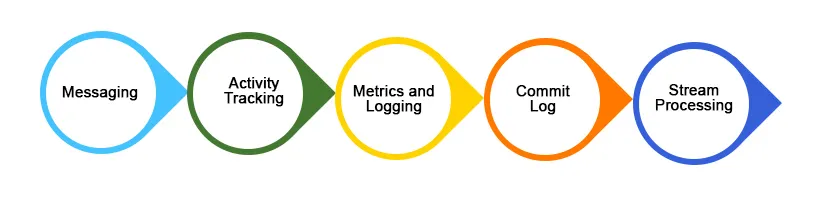
1. Mensajería
Kafka funciona mejor que otros sistemas de mensajería tradicionales como ActiveMQ, RabbitMQ, etc. En comparación, Kafka ofrece un mejor rendimiento, capacidad de partición incorporada, replicación y capacidades de tolerancia a fallas, lo que lo convierte en un mejor sistema de mensajería para aplicaciones de procesamiento a gran escala. .
2. Seguimiento de la actividad del sitio web
Las actividades de los usuarios (vistas de página, búsquedas o cualquier acción realizada) se pueden rastrear y alimentar para monitoreo o análisis en tiempo real a través de Kafka o usar Kafka para almacenar este tipo de datos en Hadoop o en el almacén de datos para su posterior procesamiento o manipulación. El seguimiento de actividad genera una gran cantidad de datos que deben transferirse a la ubicación deseada sin ningún tipo de pérdida de datos.
3. Agregación de registros
La agregación de registros es un proceso de recopilación / fusión de archivos de registro físicos de diferentes servidores de una aplicación en un único repositorio (servidor de archivos o HDFS) para su procesamiento. Kafka ofrece buen rendimiento, menor latencia de extremo a extremo en comparación con Flume.

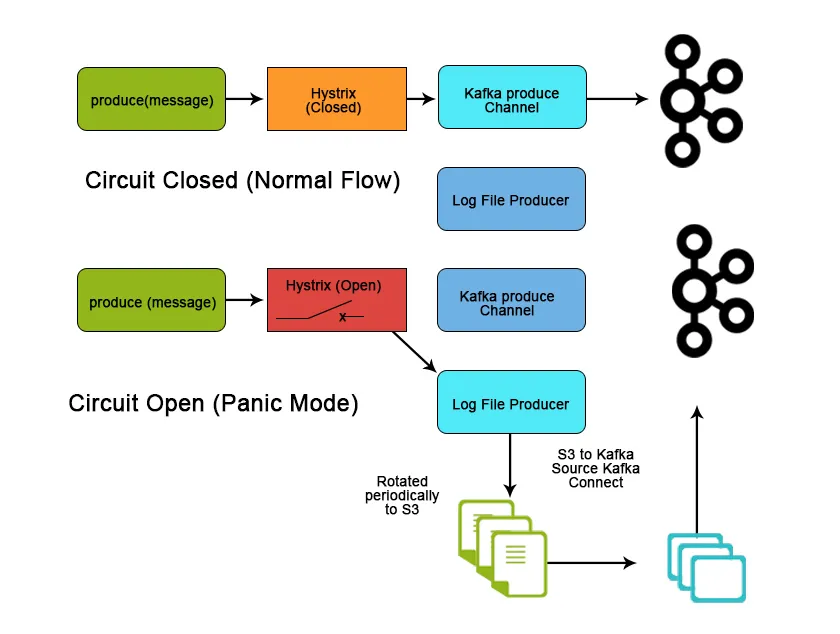
Conclusión
Kafka se usa mucho en el espacio de big data como una forma de ingerir y mover grandes cantidades de datos muy rápidamente debido a sus características de rendimiento y características que ayudan a lograr escalabilidad, confiabilidad y sostenibilidad. En este artículo, discutimos Apache Kafka sus características, casos de uso y aplicaciones y lo que lo convierte en una mejor herramienta para la transmisión de datos.
Artículos recomendados
Esta es una guía para las aplicaciones de Kafka. Aquí discutimos qué es Kafka junto con las principales aplicaciones de Kafka que incluyen casos de uso ampliamente implementados y algunas implementaciones de la vida real. También puede consultar los siguientes artículos para obtener más información.
- ¿Qué es kafka?
- ¿Cómo instalar Kafka?
- Preguntas de la entrevista de Kafka
- Apache Kafka vs Flume
- Los 8 mejores dispositivos de IoT que debes saber
- Kafka vs Kinesis | Diferencias con infografías
- Diferentes tipos de herramientas Kafka con componentes
- Conozca las principales diferencias de ActiveMQ vs Kafka