

Introducción a unirse en Spark SQL
Como sabemos, las uniones en SQL se usan para combinar datos o filas de dos o más tablas basadas en un campo común entre ellas. En este tema, vamos a aprender sobre Join in Spark SQL Join in Spark SQL.
En Spark SQL, Dataframe o Dataset son una estructura tabular en memoria que tiene filas y columnas que se distribuyen a través de múltiples nodos. Al igual que las tablas SQL normales, también podemos realizar operaciones de unión en Dataframe o Dataset presentes en Spark SQL en función de un campo común entre ellas.
Hay diferentes tipos de operaciones de unión disponibles en SQL. Dependiendo del caso de uso comercial, elegimos la operación Unir. En la siguiente sección, vamos a demostrar cada tipo de combinación con un ejemplo.
Tipos de unión en Spark SQL
Los siguientes son los diferentes tipos de combinaciones disponibles en Spark SQL:
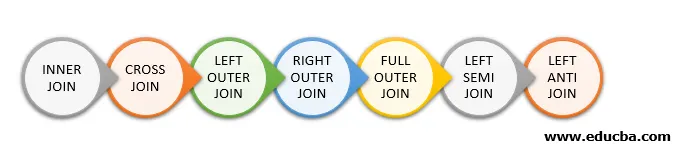
- UNIR INTERNAMENTE
- CROSS JOIN
- IZQUIERDA COMBINACIÓN EXTERNA
- UNIÓN EXTERIOR DERECHA
- UNIÓN EXTERIOR COMPLETA
- IZQUIERDA SEMI UNIRSE
- IZQUIERDA
Ejemplo de creación de datos
Utilizaremos los siguientes datos para demostrar los diferentes tipos de combinaciones:
Conjunto de datos del libro:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
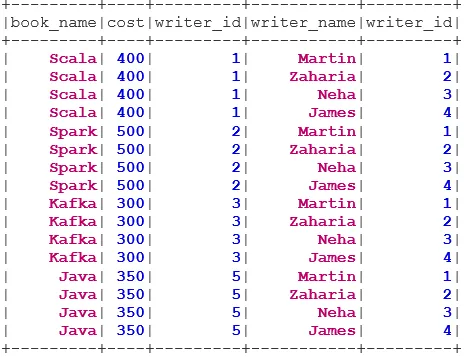
bookDS.show()

Conjunto de datos del escritor:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Tipos de uniones
A continuación se mencionan 7 tipos diferentes de uniones:
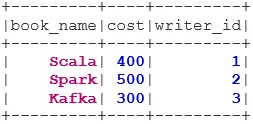
1. UNIÓN INTERNA
INNER JOIN devuelve el conjunto de datos que tiene las filas que tienen valores coincidentes en ambos conjuntos de datos, es decir, el valor del campo común será el mismo.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. UNIÓN CRUZADA
CROSS JOIN devuelve el conjunto de datos, que es el número de filas en el primer conjunto de datos multiplicado por el número de filas en el segundo conjunto de datos. Este tipo de resultado se denomina Producto cartesiano.
Requisito previo: para utilizar una unión cruzada, spark.sql.crossJoin.enabled debe establecerse en verdadero. De lo contrario, se lanzará la excepción.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. IZQUIERDA EXTERIOR UNIRSE
La IZQUIERDA EXTERIOR IZQUIERDA devuelve el conjunto de datos que tiene todas las filas del conjunto de datos izquierdo y las filas coincidentes del conjunto de datos derecho.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. UNIÓN EXTERIOR DERECHA
RIGHT OUTER JOIN devuelve el conjunto de datos que tiene todas las filas del conjunto de datos correcto y las filas coincidentes del conjunto de datos izquierdo.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. UNIÓN EXTERIOR COMPLETA
FULL OUTER JOIN devuelve el conjunto de datos que tiene todas las filas cuando hay una coincidencia en el conjunto de datos izquierdo o derecho.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. IZQUIERDA SEMI UNIRSE
El SEMI JOIN IZQUIERDO devuelve el conjunto de datos que tiene todas las filas del conjunto de datos izquierdo que tienen su correspondencia en el conjunto de datos derecho. A diferencia del LEFT OUTER JOIN, el conjunto de datos devuelto en LEFT SEMI JOIN contiene solo las columnas del conjunto de datos izquierdo.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. IZQUIERDA ANTI UNIRSE
ANTI SEMI JOIN devuelve el conjunto de datos que tiene todas las filas del conjunto de datos izquierdo que no tienen su coincidencia en el conjunto de datos derecho. También contiene solo las columnas del conjunto de datos izquierdo.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Conclusión: únete a Spark SQL
Unir datos es una de las operaciones más comunes e importantes para cumplir con nuestro caso de uso comercial. Spark SQL admite todos los tipos fundamentales de combinaciones. Al unirnos, también debemos considerar el rendimiento, ya que pueden requerir grandes transferencias de red o incluso crear conjuntos de datos más allá de nuestra capacidad de manejar. Para mejorar el rendimiento, Spark usa el optimizador de SQL para reordenar o presionar los filtros. Spark también restringe la unión peligrosa i. e CROSS JOIN. Para usar una unión cruzada, spark.sql.crossJoin.enabled debe establecerse en true explícitamente.
Artículos recomendados
Esta es una guía para unirse a Spark SQL. Aquí discutimos los diferentes tipos de combinaciones disponibles en Spark SQL con el ejemplo. También puede consultar el siguiente artículo.
- Tipos de combinaciones en SQL
- Tabla en SQL
- Consulta de inserción de SQL
- Transacciones en SQL
- Filtros PHP | ¿Cómo validar la entrada del usuario usando varios filtros?