

Descripción general de la arquitectura de minería de datos
La minería de datos es la forma de encontrar y explorar los patrones básicos o de nivel avanzado en un conjunto complicado de grandes conjuntos de datos que implica los métodos colocados en la intersección de las estadísticas, el aprendizaje automático y también los sistemas de bases de datos. Se puede decir que es un campo interdisciplinario de estadística y ciencias de la computación donde el objetivo es extraer la información utilizando métodos y técnicas inteligentes de un conjunto particular de datos mediante extracción y, por lo tanto, transformar los datos. Las actividades de gestión de datos y las actividades de preprocesamiento de datos junto con las consideraciones de inferencia también se tienen en cuenta. En este artículo, profundizaremos en la arquitectura de la minería de datos.
Arquitectura de minería de datos
La minería de datos es la técnica de extraer conocimiento interesante de un conjunto de grandes cantidades de datos que luego se almacenan en muchas fuentes de datos, como sistemas de archivos, almacenes de datos, bases de datos. Los componentes principales de la arquitectura de minería de datos implican:
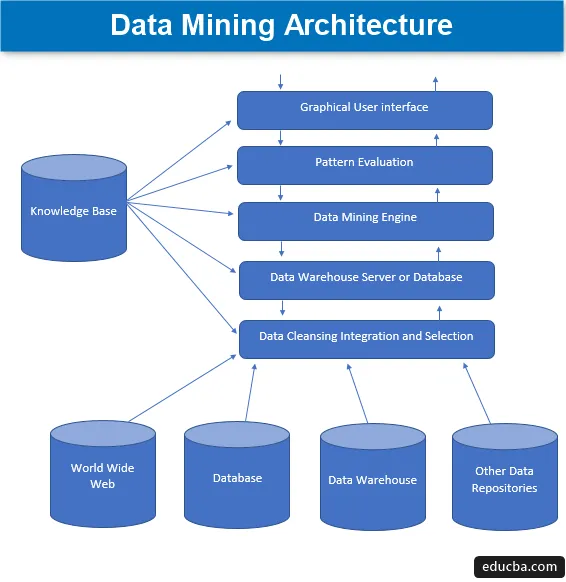
1. Fuentes de datos
Una gran variedad de documentos actuales, como el almacén de datos, la base de datos, www o popularmente llamada World Wide Web, que se convierte en las fuentes de datos reales. La mayoría de las veces, también puede darse el caso de que los datos no estén presentes en ninguna de estas fuentes doradas, sino solo en forma de archivos de texto, archivos sin formato o archivos de secuencia u hojas de cálculo, y luego los datos deben procesarse de manera muy de manera similar a como se haría el procesamiento de los datos recibidos de fuentes doradas. La mayor parte de la mayor parte de los datos actuales se recibe de Internet o de la red mundial, ya que todo lo que está presente en Internet hoy en día son datos de una forma u otra que forman alguna forma de unidades de depósito de información.
Antes de que los datos se procesen con anticipación, los diferentes procesos a través de los cuales pasan implican la limpieza, integración y selección de datos antes de que finalmente los datos se pasen a la base de datos o al servidor EDW (Enterprise Data Warehouse). El principal desafío que a veces se encuentra con este conjunto de datos son diferentes niveles de fuentes y una amplia gama de formatos de datos que forman los componentes de datos. Por lo tanto, los datos no se pueden usar directamente para el procesamiento en su estado ingenuo, sino que se procesan, transforman y elaboran de una manera mucho más útil. De esta forma, también se garantiza la fiabilidad y la integridad de los datos. Por lo tanto, el paso principal implica la recopilación de datos, la limpieza y la integración, y publicar que solo se transmiten los datos relevantes. Toda esta actividad forma parte de un conjunto separado de herramientas y técnicas.
2. Servidor de datos o base de datos
El servidor de la base de datos es el espacio real en el que se encuentran los datos una vez que se reciben de las diversas fuentes de datos. El servidor contiene el conjunto real de datos que está listo para ser procesado y, por lo tanto, gestiona la recuperación de datos. Toda esta actividad se basa en la solicitud de minería de datos de la persona.
3. Motor de minería de datos
En el caso de la minería de datos, el motor forma el componente central y es la parte más vital, o sea, la fuerza motriz que maneja todas las solicitudes y las administra y se utiliza para contener una serie de módulos. El número de módulos presentes incluye tareas de minería como la técnica de clasificación, la técnica de asociación, la técnica de regresión, la caracterización, la predicción y la agrupación, el análisis de series de tiempo, las ingenuas Bayes, las máquinas de vectores de soporte, los métodos de conjunto, las técnicas de refuerzo y ensacado, los bosques aleatorios, los árboles de decisión, etc.
4. Módulos de evaluación de patrones
Esta técnica de evaluación de los módulos es la principal responsable de medir el interés de todos los patrones que se utilizan para calcular el nivel básico del valor umbral y también se utiliza para interactuar con el motor de minería de datos para coordinar la evaluación de otros módulos. En general, el objetivo principal de este componente es buscar y buscar todos los patrones interesantes y utilizables que puedan hacer que los datos sean de una calidad comparativamente mejor.
5. Interfaz gráfica de usuario
Cuando los datos se comunican con los motores y entre varios patrones de evaluación de módulos, se hace necesario interactuar con los diversos componentes presentes y hacerlo más fácil de usar para que se pueda hacer un uso eficiente y efectivo de todos los componentes presentes y, por lo tanto, surge la necesidad de una interfaz gráfica de usuario conocida popularmente como GUI.
Esto se usa para establecer un sentido de contacto entre el usuario y el sistema de minería de datos, ayudando así a los usuarios a acceder y usar el sistema de manera eficiente y fácil para mantenerlos desprovistos de cualquier complejidad que haya surgido en el proceso. Esta es una forma de abstracción en la que solo los componentes relevantes se muestran a los usuarios y todas las complejidades y funcionalidades responsables de construir el sistema se ocultan por simplicidad. Cada vez que el usuario envía una consulta, el módulo interactúa con el conjunto general de un sistema de minería de datos para producir una salida relevante que podría mostrarse fácilmente al usuario de una manera mucho más comprensible.
6. Base de conocimiento
Este es el componente que forma la base del proceso general de minería de datos, ya que ayuda a guiar la búsqueda o en la evaluación del interés de los patrones formados. Esta base de conocimiento consta de las creencias de los usuarios y también de los datos obtenidos de las experiencias de los usuarios, que a su vez son útiles en el proceso de minería de datos. El motor puede obtener su conjunto de entradas de la base de conocimiento creada y, por lo tanto, proporciona resultados más eficientes, precisos y confiables.
La minería de datos es una de las técnicas más importantes hoy en día que se ocupa de la gestión y el procesamiento de datos que constituye la columna vertebral de cualquier organización. El análisis de datos en cualquier organización traerá resultados fructíferos. Todos y cada uno de los componentes de la técnica y arquitectura de minería de datos tienen su propia forma de realizar responsabilidades y también de completar la minería de datos de manera eficiente. Los diferentes módulos son necesarios para interactuar correctamente a fin de producir un resultado valioso y completar el procedimiento complejo de minería de datos con éxito al proporcionar el conjunto correcto de información a la empresa.
Artículos recomendados
Esta ha sido una guía para la arquitectura de minería de datos. Aquí discutimos los componentes principales de la arquitectura de minería de datos. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Herramienta de minería de datos
- Ventajas de la minería de datos
- ¿Qué es el agrupamiento en minería de datos?
- Preguntas y respuestas de la entrevista HTML5
- Técnicas más utilizadas de aprendizaje conjunto
- Algoritmos de modelos en minería de datos