

Descripción general de los tipos de agrupamiento
Antes de aprender los tipos de agrupación, comprendamos qué es la agrupación y por qué es tan importante en la industria del aprendizaje automático en este momento.
¿Qué es la agrupación? La agrupación en clúster es un proceso en el que el algoritmo divide los puntos de datos en un número determinado de grupos según el principio de que los puntos de datos similares permanecen cerca uno del otro y caen en el mismo grupo.
¿Por qué es tan importante ahora? Comprendamos que al ver un ejemplo, por ejemplo, hay una tienda de ropa en línea y quieren comprender mejor a sus clientes para que puedan hacer que su estrategia publicitaria sea más efectiva. No es posible que tengan un tipo único de estrategia para cada cliente, en lugar de esto, lo que pueden hacer es dividir a los clientes en un cierto número de grupos (en función de sus compras anteriores) y tener una estrategia separada de grupos separados. Esto hace que el negocio sea más efectivo, esta es la razón por la cual la agrupación es importante en la industria ahora.
Tipos de agrupamiento
En términos generales, los métodos de agrupación de técnicas se clasifican en dos tipos: métodos duros y métodos suaves. En el método Hard Clustering, cada punto de datos u observación pertenece a un solo cluster. En el método de agrupación suave, cada punto de datos no pertenecerá completamente a un grupo, sino que puede ser miembro de más de un grupo, tiene un conjunto de coeficientes de membresía correspondientes a la probabilidad de estar en un grupo determinado.
Actualmente, hay diferentes tipos de métodos de agrupación en uso, aquí en este artículo veamos algunos de los más importantes como la agrupación jerárquica, la agrupación de particiones, la agrupación difusa, la agrupación basada en la densidad y la agrupación basada en el modelo de distribución. Ahora analicemos cada uno de estos con un ejemplo:
1. Particionamiento en clúster
La agrupación en particiones es un tipo de técnica de agrupación que divide el conjunto de datos en un número establecido de grupos. (Por ejemplo, el valor de K en KNN y se decidirá antes de entrenar el modelo). También se puede llamar como un método basado en centroide. En este enfoque, el centro del clúster (centroide) se forma de tal manera que la distancia de los puntos de datos en ese clúster es mínima cuando se calcula con otros centroides del clúster. Un ejemplo más popular de este algoritmo es el algoritmo KNN. Así es como se ve un algoritmo de agrupamiento de particionamiento
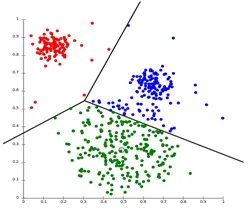
2. Agrupación jerárquica
El agrupamiento jerárquico es un tipo de técnica de agrupamiento, que divide ese conjunto de datos en varios grupos, donde el usuario no especifica el número de grupos que se generarán antes de entrenar el modelo. Este tipo de técnica de agrupación también se conoce como métodos basados en conectividad. En este método, no se realizará una partición simple del conjunto de datos, mientras que nos proporciona la jerarquía de los clústeres que se fusionan entre sí después de una cierta distancia. Una vez que se realiza la agrupación jerárquica en el conjunto de datos, el resultado será una representación de puntos de datos (Dendogram) basada en un árbol, que se dividen en grupos. Así es como se ve una agrupación jerárquica después de completar el entrenamiento
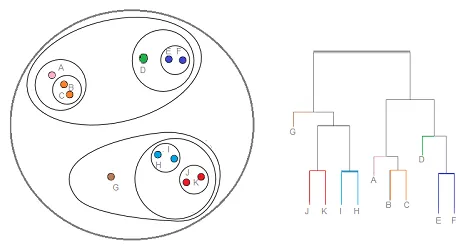
Enlace de origen: agrupación jerárquica
En Particionamiento en clúster y agrupación jerárquica, una diferencia principal que podemos notar es que en la partición en clúster especificaremos previamente el valor de cuántos clústeres queremos que se divida el conjunto de datos y no preespecifiquemos este valor en el agrupamiento jerárquico .
3. Agrupación basada en densidad
En este agrupamiento, los grupos de técnicas se formarán mediante la segregación de varias regiones de densidad basadas en diferentes densidades en el gráfico de datos. La agrupación espacial basada en densidad y la aplicación con ruido (DBSCAN) es el algoritmo más utilizado en este tipo de técnica. La idea principal detrás de este algoritmo es que debe haber un número mínimo de puntos que contengan cerca de un radio dado para cada punto en el grupo. Hasta ahora, en las técnicas de agrupación discutidas anteriormente, si observa a fondo, podemos notar una cosa común en todas las técnicas que tienen la forma de agrupaciones formadas, ya sea esféricas u ovaladas o cóncavas. DBSCAN puede formar grupos en diferentes formas, este tipo de algoritmo es más adecuado cuando el conjunto de datos contiene ruido o valores atípicos. Así es como se ve un algoritmo de agrupamiento espacial basado en la densidad después de completar el entrenamiento.
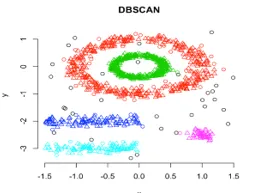
Enlace de origen: Agrupación basada en densidad
4. Clustering basado en modelos de distribución
En este tipo de agrupación, las agrupaciones técnicas se forman mediante la identificación por la probabilidad de que todos los puntos de datos en la agrupación provengan de la misma distribución (Normal, Gaussiana). El algoritmo más popular en este tipo de técnica es la agrupación de Expectación-Maximización (EM) utilizando modelos de mezcla gaussiana (GMM).
Las técnicas de agrupamiento normales como el agrupamiento jerárquico y el agrupamiento de particionamiento no se basan en modelos formales, KNN en el agrupamiento de particionamiento produce resultados diferentes con diferentes valores de K. Como KNN y KMN consideran la media para el centro del clúster, en algunos casos no es lo más adecuado con los modelos de mezcla gaussiana. Suponemos que los puntos de datos están distribuidos por Gauss, de esta manera tenemos dos parámetros para describir la forma de la media del clúster y la desviación estándar. De esta forma, para cada grupo se asigna una distribución gaussiana, para obtener los valores óptimos de estos parámetros (media y desviación estándar) se está utilizando un algoritmo de optimización llamado Expectation Maximization. Así es como se ve EM - GMM después del entrenamiento.
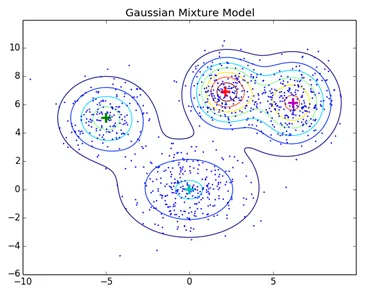
Enlace de origen: agrupación basada en modelos de distribución
5. Agrupamiento difuso
Pertenece a una rama de las técnicas de agrupación de métodos blandos, mientras que todas las técnicas de agrupación mencionadas anteriormente pertenecen a técnicas de agrupación de métodos duros. En este tipo de técnica de agrupamiento, los puntos están cerca del centro, tal vez una parte del otro grupo en mayor grado que los puntos en el borde del mismo grupo. La probabilidad de que un punto pertenezca a un grupo dado es un valor que se encuentra entre 0 y 1. El algoritmo más popular en este tipo de técnica es FCM (Algoritmo Fuzzy C-significa) Aquí, el centroide de un grupo se calcula como la media de todos los puntos, ponderados por su probabilidad de pertenecer al grupo.
Conclusión - Tipos de agrupamiento
Estas son algunas de las diferentes técnicas de agrupación que se utilizan actualmente y en este artículo, hemos cubierto un algoritmo popular en cada técnica de agrupación. Tenemos que elegir el tipo de tecnología que usamos, en función de nuestro conjunto de datos y los requisitos que debemos cumplir.
Artículos recomendados
Esta ha sido una guía de Tipos de agrupamiento. Aquí discutimos diferentes tipos de agrupamiento con sus ejemplos. También puede echar un vistazo a los siguientes artículos para obtener más información:
- Algoritmo de agrupamiento jerárquico
- Agrupación en Machine Learning
- Tipos de algoritmos de aprendizaje automático
- Tipos de técnicas de análisis de datos
- ¿Cómo usar y eliminar la jerarquía en Tableau?
- Guía completa de tipos de análisis de datos