
Introducción a la regresión de Poisson en R
La regresión de Poisson es un tipo de regresión que es similar a la regresión lineal múltiple, excepto que la respuesta o la variable dependiente (Y) es una variable de conteo. La variable dependiente sigue la distribución de Poisson. El predictor o las variables independientes pueden ser de naturaleza continua o categórica. En cierto modo, es similar a la Regresión logística que también tiene una variable de respuesta discreta. La comprensión previa de la distribución de Poisson y su forma matemática es muy esencial para aprovecharla para la predicción. En R, la regresión de Poisson se puede implementar de una manera muy efectiva. R ofrece un conjunto integral de funcionalidades para su implementación.
Implementando la regresión de Poisson
Ahora procederemos a comprender cómo se aplica el modelo. La siguiente sección ofrece un procedimiento paso a paso para lo mismo. Para esta demostración, estamos considerando el conjunto de datos "gala" del paquete "lejano". Pertenece a la diversidad de especies en las Islas Galápagos. Hay un total de 7 variables en el conjunto de datos. Usaremos la regresión de Poisson para definir una relación entre el número de especies de plantas (Especies) con otras variables en el conjunto de datos.
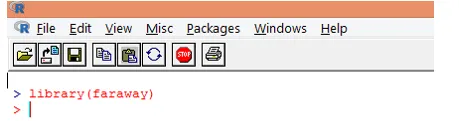
1. Primero cargue el paquete "lejano". En caso de que el paquete no esté presente, descárguelo usando la función install.packages ().
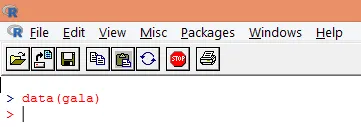
2. Una vez que se carga el paquete, cargue el conjunto de datos "gala" en R usando la función data () como se muestra a continuación.
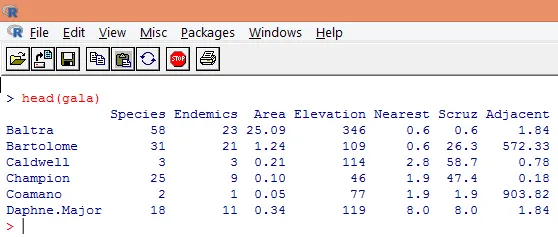
3. Los datos cargados deben visualizarse para estudiar la variable y verificar si hay alguna discrepancia. Podemos visualizar los datos completos o solo las primeras filas usando la función head () como se muestra en la siguiente captura de pantalla.
4. Para obtener más información sobre el conjunto de datos, podemos usar la funcionalidad de ayuda en R como se muestra a continuación. Genera la documentación R como se muestra en la captura de pantalla posterior a la siguiente captura de pantalla.


5. Si estudiamos el conjunto de datos como se mencionó en los pasos anteriores, entonces podemos encontrar que Species es una variable de respuesta. Ahora estudiaremos un resumen básico de las variables predictoras.
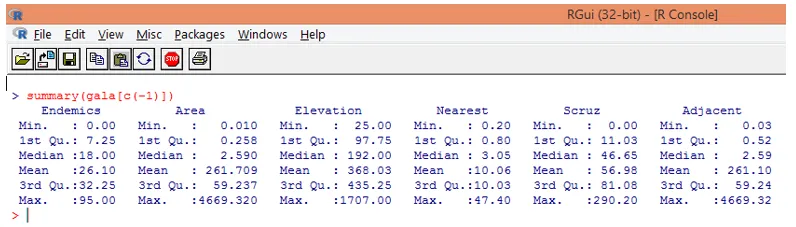
Tenga en cuenta que, como se puede ver arriba, hemos excluido la variable Especies. La función de resumen nos da información básica. Solo observe los valores medios para cada una de estas variables, y podemos encontrar que existe una gran diferencia, en términos del rango de valores, entre la primera mitad y la segunda mitad, por ejemplo, para el valor mediano de la variable Área es 2.59, pero el máximo el valor es 4669.320.
6. Ahora que hemos terminado con el análisis básico, generaremos un histograma para las especies para verificar si la variable sigue la distribución de Poisson. Esto se ilustra a continuación.

El código anterior genera un histograma para la variable Especie junto con una curva de densidad superpuesta sobre él.
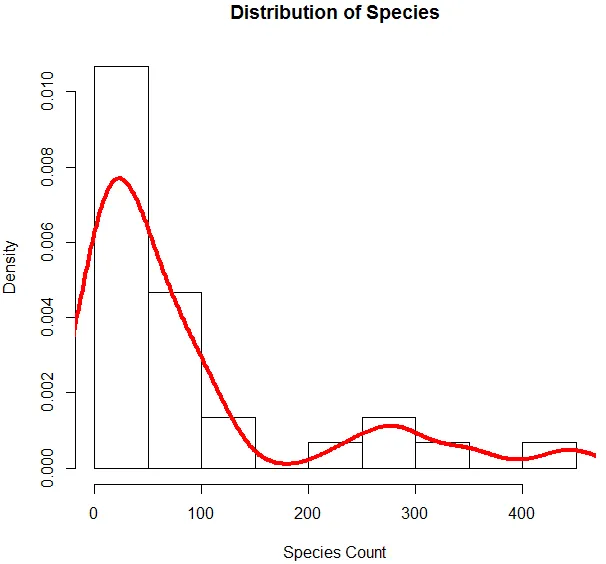
La visualización anterior muestra que Species sigue una distribución de Poisson, ya que los datos están sesgados a la derecha. También podemos generar un diagrama de caja, para obtener más información sobre el patrón de distribución como se muestra a continuación.
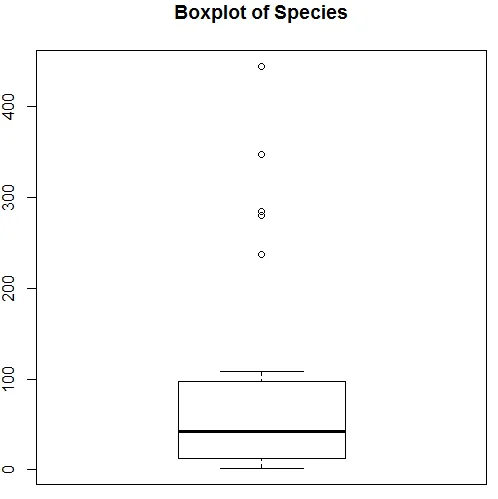
7. Una vez realizado el análisis preliminar, ahora aplicaremos la regresión de Poisson como se muestra a continuación.
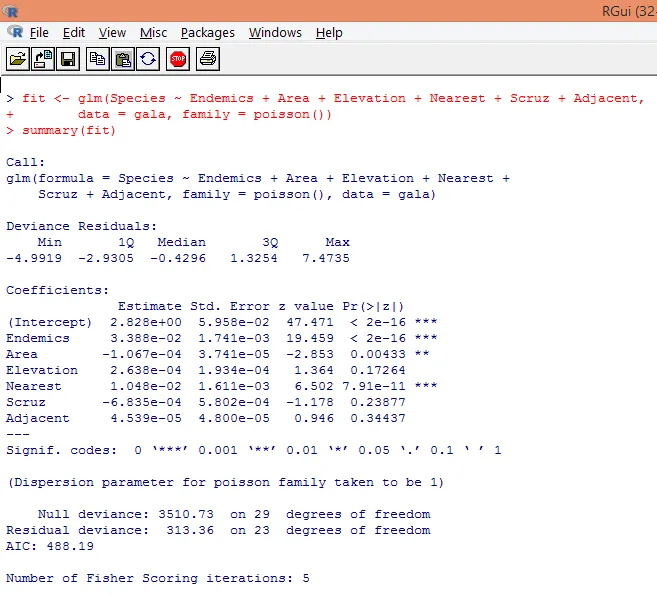
Con base en el análisis anterior, encontramos que las variables Endémicas, Área y Nearest son significativas y solo su inclusión es suficiente para construir el modelo de regresión de Poisson correcto.
8. Construiremos un modelo de regresión de Poisson modificado teniendo en cuenta solo tres variables, a saber. Endémicas, área y más cercano. Veamos qué resultados obtenemos.
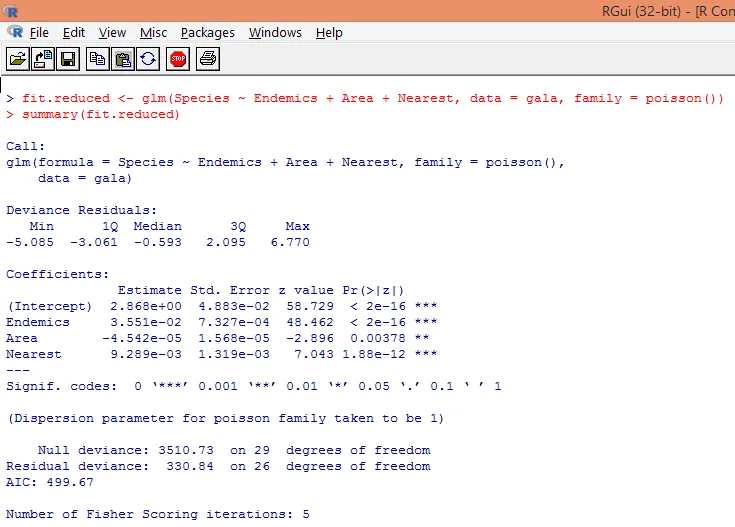
La salida produce desviaciones, parámetros de regresión y errores estándar. Podemos ver que cada uno de los parámetros es significativo en el nivel p <0.05.
9. El siguiente paso es interpretar los parámetros del modelo. Los coeficientes del modelo se pueden obtener examinando los coeficientes en la salida anterior o usando la función coef ().
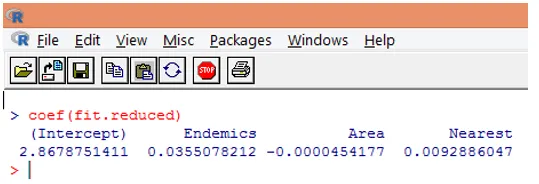
En la regresión de Poisson, la variable dependiente se modela como el registro del loge medio condicional (l). El parámetro de regresión de 0.0355 para Endemics indica que un aumento de una unidad en la variable está asociado con un aumento de 0.04 en el número medio de especies de Log, manteniendo constantes otras variables. La intersección es un número medio de Log de especies cuando cada uno de los predictores es igual a cero.
10. Sin embargo, es mucho más fácil interpretar los coeficientes de regresión en la escala original de la variable dependiente (número de especies, en lugar del número de registro de especies). La exponenciación de los coeficientes permitirá una fácil interpretación. Esto se hace de la siguiente manera.
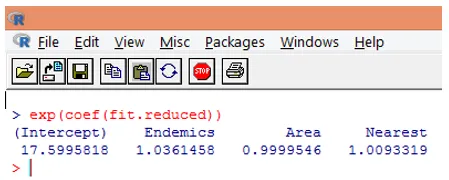
De los hallazgos anteriores, podemos decir que un aumento de unidad en el Área multiplica el número esperado de especies por 0.9999, y un aumento de la unidad en el número de especies endémicas representadas por Endemics multiplica el número de especies por 1.0361. El aspecto más importante de la regresión de Poisson es que los parámetros exponenciados tienen un efecto multiplicativo en lugar de aditivo en la variable de respuesta.
11. Utilizando los pasos anteriores, obtuvimos un modelo de regresión de Poisson para predecir el número de especies de plantas en las Islas Galápagos. Sin embargo, es muy importante verificar la sobredispersión. En la regresión de Poisson, la varianza y las medias son iguales.
La sobredispersión ocurre cuando la varianza observada de la variable de respuesta es mayor que la predicha por la distribución de Poisson. El análisis de la dispersión excesiva se vuelve importante, ya que es común con los datos de conteo y puede afectar negativamente los resultados finales. En R, la sobredispersión se puede analizar utilizando el paquete "qcc". El análisis se ilustra a continuación.
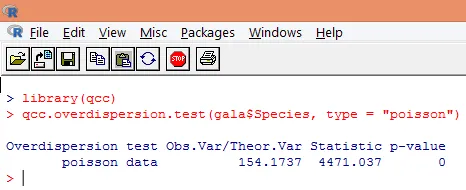
La prueba significativa anterior muestra que el valor p es menor que 0.05, lo que sugiere fuertemente la presencia de sobredispersión. Intentaremos ajustar un modelo usando la función glm (), reemplazando family = “Poisson” por family = “quasipoisson”. Esto se ilustra a continuación.
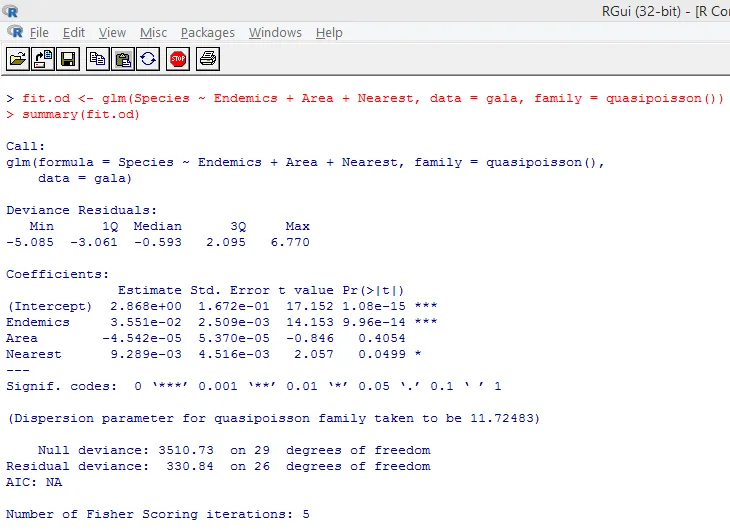
Estudiando de cerca el resultado anterior, podemos ver que las estimaciones de los parámetros en el enfoque cuasi-Poisson son idénticas a las producidas por el enfoque de Poisson, aunque los errores estándar son diferentes para ambos enfoques. Además, en este caso, para Área, el valor p es mayor que 0.05, lo que se debe a un error estándar mayor.
Importancia de la regresión de Poisson
- La regresión de Poisson en R es útil para predicciones correctas de la variable discreta / cuenta.
- Nos ayuda a identificar aquellas variables explicativas que tienen un efecto estadísticamente significativo en la variable de respuesta.
- La regresión de Poisson en R es la más adecuada para eventos de naturaleza "rara", ya que tienden a seguir una distribución de Poisson frente a eventos comunes que generalmente siguen una distribución normal.
- Es adecuado para la aplicación en casos donde la variable de respuesta es un número entero pequeño.
- Tiene amplias aplicaciones, ya que la predicción de variables discretas es crucial en muchas situaciones. En medicina, puede usarse para predecir el impacto de la droga en la salud. Se usa mucho en análisis de supervivencia como la muerte de organismos biológicos, fallas de sistemas mecánicos, etc.
Conclusión
La regresión de Poisson se basa en el concepto de distribución de Poisson. Es otra categoría que pertenece al conjunto de técnicas de regresión que combina las propiedades de las regresiones tanto lineales como logísticas. Sin embargo, a diferencia de la regresión logística que genera solo salida binaria, se usa para predecir una variable discreta.
Artículos recomendados
Esta es una guía para la regresión de Poisson en R. Aquí discutimos la introducción Implementación de la regresión de Poisson e importancia de la regresión de Poisson. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- GLM en R
- Generador de números aleatorios en R
- Fórmula de regresión
- Regresión logística en R
- Regresión lineal vs regresión logística | Principales diferencias