

¿Qué es la función colmena?
Como sabemos hoy, Hadoop es una de las tecnologías versátiles en big data. Hadoop tiene la capacidad de hacer frente a grandes conjuntos de datos, pero como el crecimiento de los datos es proporcional, escribir programas de reducción de mapas se vuelve difícil. Para realizar consultas SQL, presente en HDFS, Hadoop introdujo una de estas tecnologías llamada apache Hive, iniciada por Facebook. La colmena es muy utilizada por el analista de datos. Se implementan para tres funcionalidades, a saber: resumen de datos, análisis de datos en archivos distribuidos y consulta de datos. Hive proporciona consultas similares a SQL llamadas HQL: el lenguaje de consulta alta admite DML, funciones definidas por el usuario. El compilador de Hive convierte internamente esta consulta en trabajos de reducción de mapas que simplifica el trabajo de Hadoop al escribir programas complejos. Podríamos encontrar una colmena en aplicaciones como almacenamiento de datos, visualización de datos y análisis ad-hoc, google analytics. La ventaja clave es que utilizan el conocimiento de SQL, que es una habilidad básica implementada entre los científicos de datos y los profesionales de software.
Diferentes funciones de la colmena en detalle
Hive admite diferentes tipos de datos que no se encuentran en otros sistemas de bases de datos. incluye un mapa, matriz y estructura. Hive tiene algunas funciones integradas para realizar varias funciones matemáticas y aritméticas para un propósito especial. Las funciones en la colmena se pueden clasificar en los siguientes tipos. Son funciones integradas y funciones definidas por el usuario.
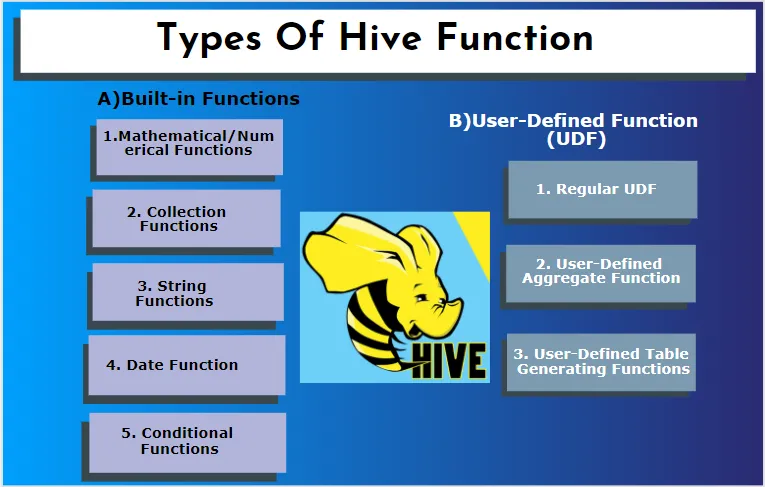
A) Funciones incorporadas
Estas funciones extraen datos de las tablas de la colmena y procesan los cálculos. Algunas de las funciones integradas son:
1. Funciones matemáticas / numéricas
Estas funciones se utilizan principalmente para cálculos matemáticos. Estas funciones se usan en consultas SQL.
| Nombre de la función | Ejemplo | Descripción |
| ABS (doble x) | Colmena> seleccione ABS (-200) de tmp; | Devolverá el valor absoluto de un número. |
| TECHO (doble x) | Colmena> seleccione CEIL (8.5) de tmp; | Obtendrá el entero más pequeño mayor o igual al valor x. |
| Rand (), rand (int semilla) | Colmena> seleccione Rand () de tmp;
Rand (0-9) | Devuelve un número aleatorio, depende del valor inicial, los números aleatorios generados serían deterministas. |
| Pow (doble x, doble y) | Colmena> seleccione Pow (5, 2) de tmp; | Devuelve el valor x elevado a la potencia y. |
| PISO (doble y) | Colmena> seleccione PISO (11.8) de tmp; | Devuelve un entero máximo menor o igual que para dar el valor y. |
| CAD (doble a) | Colmena> seleccione Exp (30) de tmp; | Devolverá el valor exponente de 30. los valores del algoritmo natural. |
| PMOD (int a, int b) | Colmena> seleccione PMOD (2, 4) de tmp; | Da el módulo positivo del número. |
2. Funciones de colección
Volcar todos los elementos juntos y devolver elementos individuales depende del tipo de datos incluido.
| Nombre de la función | Ejemplo | Descripción |
| Map_values (Mapa) | Colmena> seleccionar valores del mapa ('hola', 45) | Obtiene elementos de matriz desordenados. |
| Tamaño (mapa) | Colmena> seleccionar tamaño (mapa) | Devuelve el número de elementos en el mapa de tipo de datos. |
| Array_contains (Array b) | Colmena> seleccione array_contains (a (10)) | Devuelve VERDADERO si la matriz contiene el valor. |
| Sort_array (matriz a) | Colmena> seleccione sort_array ((10, 3, 6, 1, 7)) | Ordena la matriz de entrada en orden ascendente de acuerdo con el orden natural de los elementos de la matriz y devuelve el valor. |
3. Funciones de cadena
El uso de funciones de cadena de análisis de datos se realiza de forma excelente
| Split (string s, string pat) | Hive> select split ('educba ~ hive ~ Hadoop, ' ~ ') salida: (“educba”, ”hive”, ”Hadoop”) | Divide la cadena alrededor de expresiones de pat y devuelve una matriz. |
| carga (string s, int Len, pad pad) | Colmena> seleccionar carga ('EDUCBA', 6, 'H') | Devuelve cadenas con relleno derecho con la longitud de la cadena. (carácter de almohadilla). |
| Longitud (cadena str) | Colmena> seleccionar longitud ('educba') | Esta función devuelve la longitud de la cadena. |
| Rtrim (cadena a) | Colmena> seleccione rtrim ('TEMA');
Salida: 'Tema' | Devuelve el resultado recortando espacios de los extremos derechos. |
| Concat (cadena m, cadena n) | Colmena> select concat ('data', 'ware') Resultado: Dataware | Resulta en la cadena haciendo la concatenación de dos cadenas, esto puede tomar cualquier cantidad de entradas. |
| Reverso (cadena s) | Colmena> seleccionar reversa ('Móvil') | Devuelve el resultado de una cadena invertida. |
4. Función de fecha
Es necesario tener formato de datos en la colmena para evitar un error nulo en la salida. Es necesario tener compatibilidad de fecha para ir con las funciones de fecha introducidas en la colmena.
| Unix_timestamp (Fecha de cadena, patrón de cadena) | Colmena> seleccione Marca de tiempo Unix_ ('2019-06-08', 'aaaa-mm-dd'); Resultado: 124576 400 tiempo empleado: 0.146 segundos | Esta función devuelve la fecha al formato específico y devuelve segundos entre la fecha y las horas de Unix. |
| Unix_timestamp (fecha de cadena) | Colmena> seleccione Marca de tiempo Unix_ ('2019-06-08 09:20:10', 'aaaa-mm-dd'); | Devuelve la fecha en formato 'aaaa-MM-dd HH: mm: ss' en la marca de tiempo de Unix. |
| Hora (fecha de cadena) | Colmena> seleccione hora ('2019-06-08 09:20:10'); Resultado: 09 horas | Devuelve la hora de la marca de tiempo |
5. Funciones condicionales
| If (prueba booleana, valor T verdadero, t falso) | Colmena> seleccione SI (1 = 1, 'VERDADERO', 'FALSO') como IF_CONDITION_TEST; | Comprueba con la condición si el valor es verdadero devuelve 1 y falso devuelve 0. |
| No es nulo (b) | Colmena> Seleccionar no es nulo (nulo); | Esto obtiene declaraciones no nulas. si nulo devuelve falso. |
| Fusión (valor1, valor2) | Ejemplo: colmena> select coalesce (Null, null, 4, null, 6). devuelve 4. | Primero recupera valores no nulos de la lista de valores. |
B) Función definida por el usuario (UDF)
Hive utiliza funciones específicas del usuario de acuerdo con los requisitos del cliente, está escrito en la programación de Java. Se implementa mediante dos interfaces, a saber, API simple y API compleja. Se invocan desde la consulta de la colmena. Tres tipos de UDF:
1. UDF regular
Funciona en una mesa con una sola fila. Se crea creando una clase java, luego empaquetándolos en un archivo .jar, el siguiente paso es verificar con una ruta de clase de la colmena. luego finalmente ejecutándolos en una consulta de la colmena.
2. Función agregada definida por el usuario
Utilizan funciones agregadas como avg / mean implementando cinco métodos init (), iterate (), partial (), merge (), terminate ().
3. Funciones de generación de tablas definidas por el usuario
Funciona con una sola fila en una tabla y da como resultado varias filas.
Conclusión
En conclusión, hemos aprendido cómo trabajar en la plataforma de la colmena con funciones integradas y funciones definidas por el usuario en detalle a través de este artículo. La mayoría de las organizaciones tienen programadores y desarrolladores de SQL para trabajar en el proceso del lado del servidor, pero una colmena apache es una herramienta poderosa que les ayuda a usar el marco Hadoop sin conocimiento previo sobre programas y reducción de mapas. Hive ayuda a los nuevos usuarios a comenzar y explorar el análisis de datos sin ninguna barrera.
Artículos recomendados
Esta es una guía para la función Hive. Aquí discutimos el Concepto, dos tipos diferentes de funciones y subfunciones en Hive. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Principales funciones de cadena en Hive
- Preguntas de la entrevista de la colmena
- ¿Qué es RMAN Oracle?
- ¿Qué es el modelo de cascada?
- Introducción a la arquitectura de la colmena
- Orden de la colmena por