
Introducción al ciclo de vida de la ciencia de datos
El ciclo de vida de la ciencia de datos gira en torno al uso del aprendizaje automático y otros métodos analíticos para producir ideas y predicciones a partir de los datos con el fin de lograr un objetivo comercial. Todo el proceso implica varios pasos, como limpieza de datos, preparación, modelado, evaluación de modelos, etc. Es un proceso largo y puede tardar varios meses en completarse. Por lo tanto, es muy importante tener una estructura general a seguir para cada problema en cuestión. La estructura mundialmente reconocida para resolver cualquier problema analítico se denomina Proceso estándar de la industria cruzada para minería de datos o marco CRISP-DM.
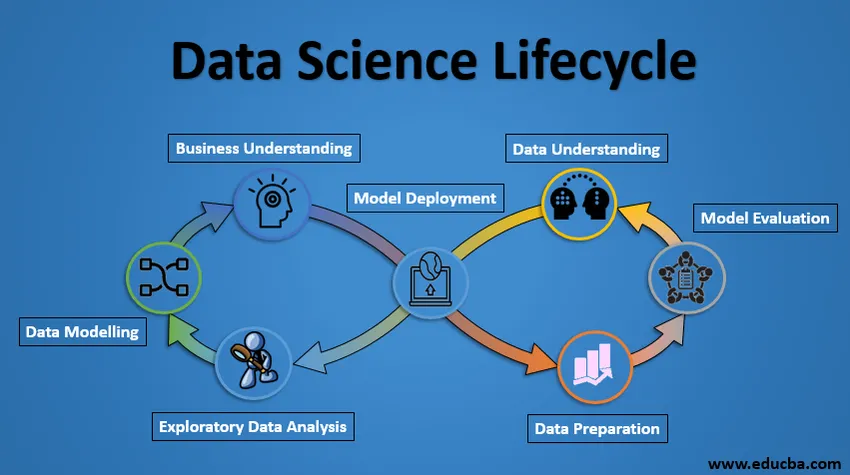
Ciclo de vida de la ciencia de datos
A continuación se muestra el proyecto Lifecycle of Data Science.
1. Entendimiento empresarial
Todo el ciclo gira en torno al objetivo comercial. ¿Qué resolverá si no tiene un problema preciso? Es extremadamente importante comprender claramente el objetivo del negocio porque ese será su objetivo final del análisis. Después de una comprensión adecuada, solo podemos establecer el objetivo específico de análisis que esté sincronizado con el objetivo comercial. Debe saber si el cliente desea reducir la pérdida de crédito, o si desea predecir el precio de un producto, etc.
2. Comprensión de datos
Después de la comprensión empresarial, el siguiente paso es la comprensión de los datos. Esto implica la recopilación de todos los datos disponibles. Aquí debe trabajar estrechamente con el equipo de negocios, ya que realmente conocen qué datos están presentes, qué datos podrían usarse para este problema comercial y otra información. Este paso implica describir los datos, su estructura, su relevancia, su tipo de datos. Explore los datos usando diagramas gráficos. Básicamente, extraer cualquier información que pueda obtener sobre los datos simplemente explorando los datos.
3. Preparación de datos
Luego viene la etapa de preparación de datos. Esto incluye pasos como seleccionar los datos relevantes, integrar los datos fusionando los conjuntos de datos, limpiarlos, tratar los valores faltantes eliminándolos o imputándolos, tratar datos erróneos eliminándolos, también verificar valores atípicos usando diagramas de cajas y manejarlos . Al construir nuevos datos, derivar nuevas características de los existentes. Formatee los datos en la estructura deseada, elimine las columnas y características no deseadas. La preparación de datos es la que lleva más tiempo pero podría decirse que es el paso más importante en todo el ciclo de vida. Su modelo será tan bueno como sus datos.
4. Análisis de datos exploratorios
Este paso implica tener una idea acerca de la solución y los factores que la afectan, antes de construir el modelo real. La distribución de datos dentro de diferentes variables de una característica se explora gráficamente usando gráficos de barras, las relaciones entre las diferentes características se capturan a través de representaciones gráficas como diagramas de dispersión y mapas de calor. Muchas otras técnicas de visualización de datos se utilizan ampliamente para explorar cada característica individualmente, y combinándolas con otras características.
5. Modelado de datos
El modelado de datos es el corazón del análisis de datos. Un modelo toma los datos preparados como entrada y proporciona la salida deseada. Este paso incluye elegir el tipo de modelo apropiado, si el problema es un problema de clasificación, un problema de regresión o un problema de agrupamiento. Después de elegir la familia de modelos, entre los diversos algoritmos entre esa familia, debemos elegir cuidadosamente los algoritmos para implementarlos e implementarlos. Necesitamos ajustar los hiperparámetros de cada modelo para lograr el rendimiento deseado. También debemos asegurarnos de que haya un equilibrio correcto entre rendimiento y generalización. No queremos que el modelo aprenda los datos y funcione mal en los nuevos datos.
6. Evaluación del modelo
Aquí se evalúa el modelo para verificar si está listo para implementarse. El modelo se prueba con datos no vistos, evaluado en un conjunto de métricas de evaluación cuidadosamente pensado. También debemos asegurarnos de que el modelo se ajuste a la realidad. Si no obtenemos un resultado satisfactorio en la evaluación, debemos repetir todo el proceso de modelado hasta alcanzar el nivel deseado de métricas. Cualquier solución de ciencia de datos, un modelo de aprendizaje automático, como un ser humano, debería evolucionar, debería ser capaz de mejorar con nuevos datos, adaptarse a una nueva métrica de evaluación. Podemos construir múltiples modelos para un determinado fenómeno, pero muchos de ellos pueden ser imperfectos. La evaluación del modelo nos ayuda a elegir y construir un modelo perfecto.
7. Implementación del modelo
El modelo después de una evaluación rigurosa finalmente se implementa en el formato y canal deseados. Este es el paso final en el ciclo de vida de la ciencia de datos. Cada paso en el ciclo de vida de la ciencia de datos explicado anteriormente debe ser trabajado cuidadosamente. Si algún paso se ejecuta incorrectamente, afectará el siguiente paso y todo el esfuerzo se desperdiciará. Por ejemplo, si los datos no se recopilan correctamente, perderá información y no creará un modelo perfecto. Si los datos no se limpian correctamente, el modelo no funcionará. Si el modelo no se evalúa correctamente, fallará en el mundo real. Desde la comprensión comercial hasta la implementación del modelo, cada paso debe recibir la atención, el tiempo y el esfuerzo adecuados.
Artículos recomendados
Esta es una guía para el ciclo de vida de la ciencia de datos. Aquí discutimos una descripción general del ciclo de vida de la ciencia de datos y los pasos que conforman un ciclo de vida de la ciencia de datos. También puede consultar nuestros artículos relacionados para obtener más información:
- Introducción a los algoritmos de ciencia de datos
- Ciencia de datos vs ingeniería de software | Top 8 comparaciones útiles
- Tipos de diferencia de técnicas de ciencia de datos
- Habilidades de ciencia de datos con tipos