
¿Qué es la regresión lineal en R?
La regresión lineal es el algoritmo más popular y ampliamente utilizado en el campo de la estadística y el aprendizaje automático. La regresión lineal es una técnica de modelado para comprender la relación entre las variables de entrada y salida. Aquí las variables deben ser numéricas. La regresión lineal proviene del hecho de que la variable de salida es una combinación lineal de variables de entrada. La salida generalmente se representa con “y”, mientras que la entrada se representa con “x”.
La regresión lineal en R se puede clasificar de dos maneras
-
Si mple Regresión lineal
Esta es la regresión donde la variable de salida es una función de una sola variable de entrada. Representación de regresión lineal simple:
y = c0 + c1 * x1
-
Regresión lineal múltiple
Esta es la regresión donde la variable de salida es una función de una variable de entrada múltiple.
y = c0 + c1 * x1 + c2 * x2
En los dos casos anteriores, c0, c1, c2 son los coeficientes que representan los pesos de regresión.
Regresión lineal en R
R es una herramienta estadística muy poderosa. Entonces, veamos cómo se puede realizar la regresión lineal en R y cómo se pueden interpretar sus valores de salida.
Vamos a preparar un conjunto de datos, para realizar y comprender la regresión lineal en profundidad ahora.
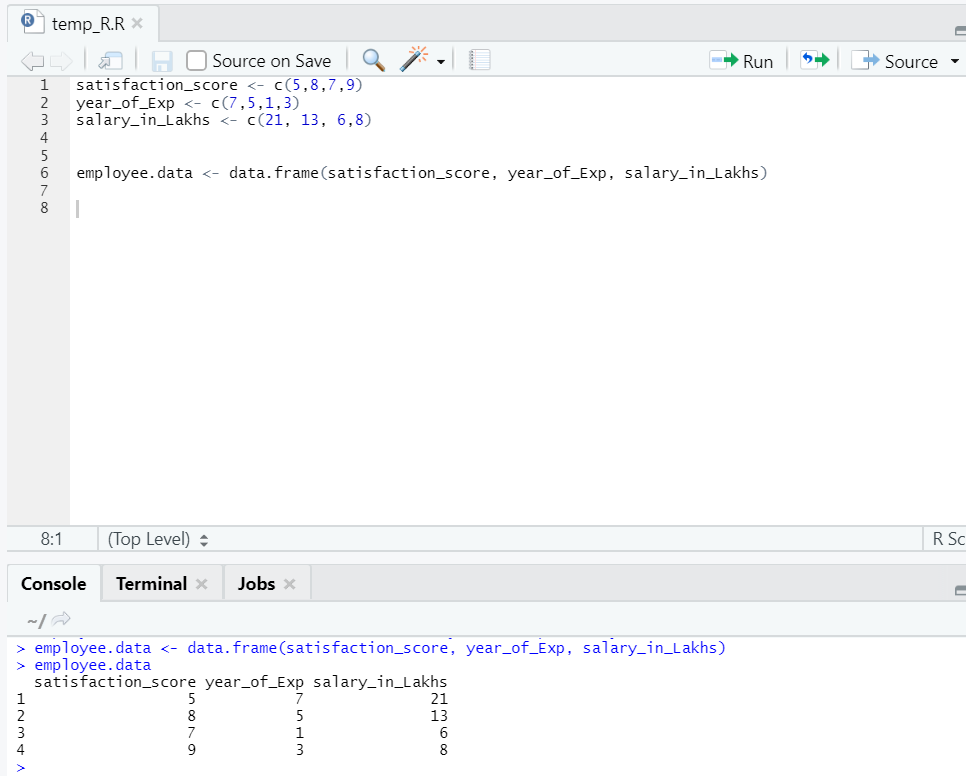
Ahora tenemos un conjunto de datos, donde "satisfacción_puntuación" y "año_de_Exp" son la variable independiente. "Salario_en_lakhs" es la variable de salida.
En referencia al conjunto de datos anterior, el problema que queremos abordar aquí mediante regresión lineal es:
Estimación del salario de un empleado, basado en su año de experiencia y puntaje de satisfacción en su empresa.
Código R de regresión lineal:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
La salida del código anterior será:
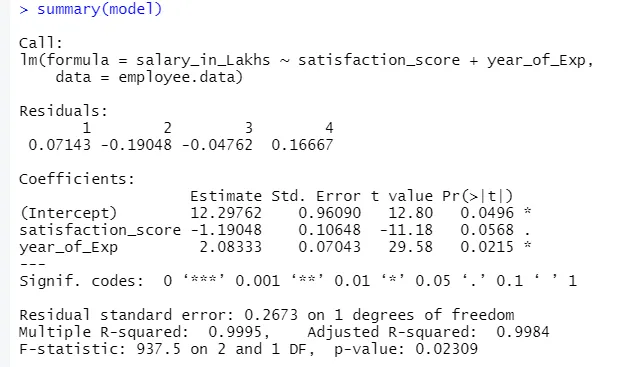
La fórmula de la regresión se convierte
Y = 12.29-1.19 * puntaje de satisfacción + 2.08 × 2 * año_de_Exp
En el caso, uno tiene múltiples entradas al modelo.
Entonces el código R puede ser:
modelo <- lm (salario_en_Lakhs ~., data = employee.data)
Sin embargo, si alguien quiere seleccionar una variable entre múltiples variables de entrada, existen múltiples técnicas como "Eliminación hacia atrás", "Selección hacia adelante", etc., disponibles para hacerlo también.
Interpretación de la regresión lineal en R
A continuación se presentan algunas interpretaciones de regresión lineal en r que son las siguientes:
1. Residuos
Esto se refiere a la diferencia entre la respuesta real y la respuesta predicha del modelo. Entonces, para cada punto, habrá una respuesta real y una respuesta pronosticada. Por lo tanto, los residuos serán tantos como las observaciones. En nuestro caso tenemos cuatro observaciones, por lo tanto, cuatro residuos.

2 coeficientes
Yendo más lejos, encontraremos la sección de coeficientes, que representa la intersección y la pendiente. Si se quiere predecir el salario de un empleado en función de su experiencia y puntaje de satisfacción, se necesita desarrollar una fórmula modelo basada en la pendiente y la intercepción. Esta fórmula te ayudará a predecir el salario. La intersección y la pendiente ayudan al analista a encontrar el mejor modelo que se adapte adecuadamente a los puntos de datos.
Pendiente: representa la inclinación de la línea.
Intercepción: la ubicación donde la línea corta el eje.
Comprendamos cómo se realiza la formación de fórmulas en función de la pendiente y la intersección.
Digamos que la intersección es 3 y la pendiente es 5.
Entonces, la fórmula es y = 3 + 5x . Esto significa que si x aumenta en una unidad, y aumenta en 5.
a.Coeficiente - Estimación
En esto, la intersección denota el valor promedio de la variable de salida, cuando toda la entrada se convierte en cero. Entonces, en nuestro caso, el salario en lakhs será de 12.29Lakhs como promedio, considerando el puntaje de satisfacción y la experiencia es cero. Aquí la pendiente representa el cambio en la variable de salida con un cambio unitario en la variable de entrada.
b. Coeficiente: error estándar
El error estándar es la estimación del error que podemos obtener al calcular la diferencia entre el valor real y el valor predicho de nuestra variable de respuesta. A su vez, esto informa sobre la confianza para relacionar las variables de entrada y salida.
c. Coeficiente - valor t
Este valor da la confianza para rechazar la hipótesis nula. Cuanto mayor es el valor lejos de cero, mayor es la confianza para rechazar la hipótesis nula y establecer la relación entre la salida y la variable de entrada. En nuestro caso, el valor también está lejos de cero.
d. Coeficiente - Pr (> t)
Este acrónimo básicamente representa el valor p. Cuanto más cerca esté de cero, más fácil podremos rechazar la hipótesis nula. La línea que vemos en nuestro caso, este valor es cercano a cero, podemos decir que existe una relación entre el paquete salarial, el puntaje de satisfacción y el año de experiencias.

Error estándar residual
Esto representa el error en la predicción de la variable de respuesta. Cuanto más bajo es, mayor es la precisión del modelo.
Múltiple R-cuadrado, R-cuadrado ajustado
R-cuadrado es una medida estadística muy importante para comprender qué tan cerca se han ajustado los datos en el modelo. Por lo tanto, en nuestro caso, qué tan bien nuestro modelo de regresión lineal representa el conjunto de datos.
El valor R cuadrado siempre se encuentra entre 0 y 1. La fórmula es:

Cuanto más cercano sea el valor a 1, mejor describirá el modelo los conjuntos de datos y su varianza.
Sin embargo, cuando aparece más de una variable de entrada en la imagen, se prefiere el valor R cuadrado ajustado.
Estadística F
Es una medida sólida para determinar la relación entre la entrada y la variable de respuesta. Cuanto mayor sea el valor que 1, mayor es la confianza en la relación entre la variable de entrada y salida.
En nuestro caso es "937.5", que es relativamente más grande considerando el tamaño de los datos. Por lo tanto, el rechazo de la hipótesis nula se vuelve más fácil.
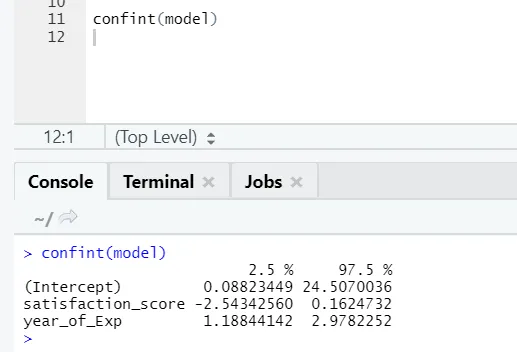
Si alguien quiere ver el intervalo de confianza para los coeficientes del modelo, esta es la forma de hacerlo:
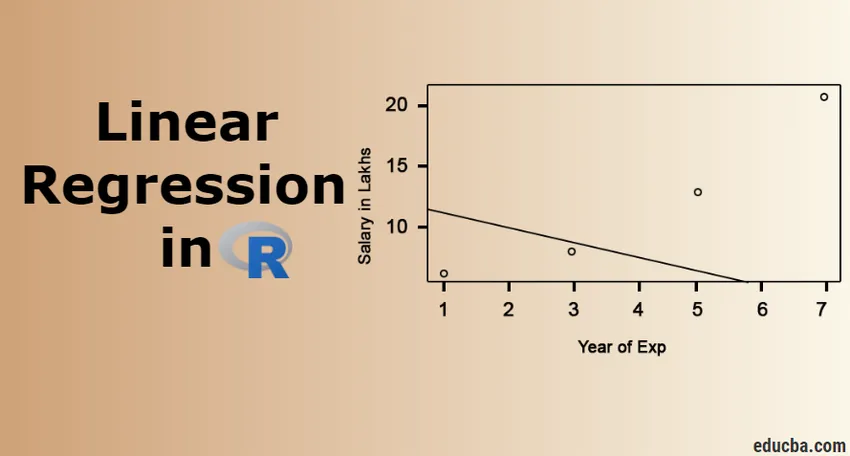
Visualización de regresión
Código R:
plot (salario_en_Lakhs ~ satisfacción_puntuación + año_de_Exp, datos = empleado.datos)
abline (modelo)
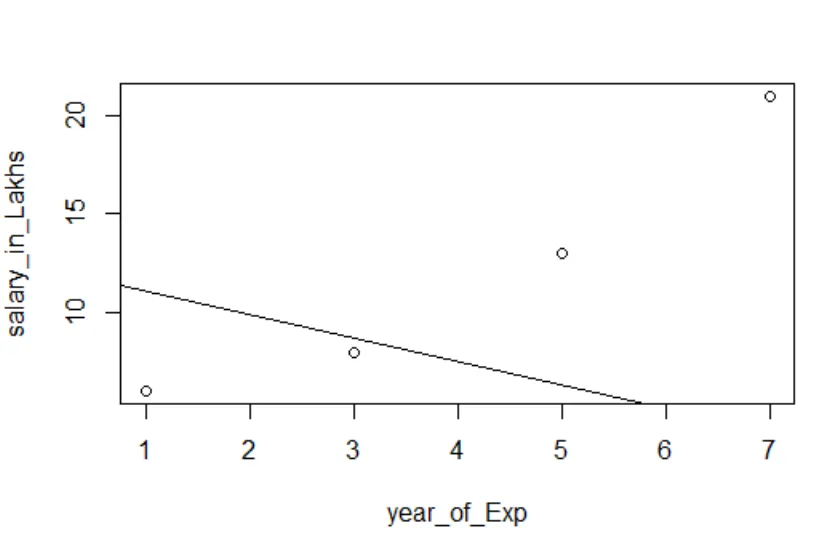
Siempre es mejor reunir más y más puntos, antes de adaptarse a un modelo.
Conclusión: regresión lineal en R
La regresión lineal es un modelo simple, fácil de ajustar, fácil de entender pero muy potente. Vimos cómo se puede realizar una regresión lineal en R. También intentamos interpretar los resultados, lo que puede ayudarlo a optimizar el modelo. Una vez que uno se sienta cómodo con la regresión lineal simple, debería intentar la regresión lineal múltiple. Junto con esto, como la regresión lineal es sensible a los valores atípicos, uno debe analizarla antes de saltar directamente a la regresión lineal.
Artículos recomendados
Esta es una guía de Regresión lineal en R. Aquí hemos discutido ¿qué es la Regresión lineal en R? categorización, visualización e interpretación de R. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Modelado predictivo
- Regresión logística en R
- Árbol de decisión en R
- R Preguntas de la entrevista
- Principales diferencias de regresión vs clasificación
- Guía para el árbol de decisión en el aprendizaje automático
- Regresión lineal vs regresión logística | Principales diferencias