

¿Qué es AWS Kinesis?
Kinesis es una plataforma que ayuda a recopilar, procesar y analizar la transmisión de datos en Amazon Web Services. La transmisión de datos es una gran cantidad de datos que se generan a partir de diferentes fuentes, como redes sociales, sensores IoT, pronóstico del tiempo, atención médica, etc. Estos se utilizan en la creación de aplicaciones según los requisitos del usuario. Algunas de las aplicaciones comunes incluyen análisis predictivos en Big Data, Machine Learning, etc. En este tema, aprenderemos sobre AWS Kinesis.
Servicios de AWS Kinesis
Antes de pasar a los servicios, primero comprendamos algunas terminologías utilizadas en Kinesis.
Terminología
| Término | Definición |
| Registro de datos | Unidad de datos almacenada en el flujo de datos de Kinesis. Se compone de blob de datos, número de secuencia y una clave de partición |
| Casco | Conjunto de la secuencia de registros de datos. El número de fragmentos se puede aumentar o disminuir si se aumenta la velocidad de datos. |
| Periodo de retención | El período de tiempo en el que se puede acceder a los datos después de agregarlos a la secuencia.
Período de retención predeterminado: 24 horas |
| Productor | Alimenta registros de datos en Kinesis Stream |
| Consumidor | Obtiene registros de Kinesis Stream y los procesa. |
Kinesis ofrece 3 servicios básicos. Son:
1. Kinesis Streams
Kinesis Stream consiste en un conjunto de secuencias de registros de datos conocidos como Fragmentos. Estos fragmentos tienen una capacidad fija que puede proporcionar una velocidad máxima de lectura de 2 MB / segundo y una velocidad de escritura de 1 MB / segundo. La capacidad máxima de una secuencia es la suma de la capacidad de cada fragmento.
Trabajo de kinesis:
- Los datos producidos por IoT y otras fuentes que se conocen como Productores se introducen en los Kinesis Streams para su almacenamiento en fragmentos.
- Esta información estará disponible en Shard por un máximo de 24 horas.
- Si necesita ser almacenado por más de este tiempo predeterminado, el usuario puede aumentar a un período de retención de 7 días.
- Una vez que los datos llegan a los fragmentos, las instancias de EC2 pueden tomar estos datos para diferentes propósitos.
- Las instancias EC2 que recuperan datos se conocen como Consumidores.
- Después del procesamiento de datos, se alimenta a uno de los servicios web de Amazon, como Simple Storage Service (S3), DynamoDB, Redshift, etc.
2. Kinesis Firehose
Kinesis Firehose es útil para mover datos a servicios web de Amazon como Redshift, servicio de almacenamiento simple, Elastic Search, etc. Es una parte de la plataforma de transmisión que no administra ningún recurso. Los productores de datos se configuran de tal manera que los datos deben enviarse a Kinesis Firehose y luego los envía automáticamente al destino correspondiente.
Trabajo de Kinesis Firehose:
- Como se mencionó en el trabajo de AWS Kinesis Streams, Kinesis Firehose también obtiene datos de productores como teléfonos móviles, computadoras portátiles, EC2, etc. Pero esto no tiene que tomar datos en fragmentos o aumentar los períodos de retención como Kinesis Streams. Es porque Kinesis Firehose lo hace automáticamente.
- Los datos se analizan automáticamente y se envían al servicio de almacenamiento simple.
- Como no hay un período de retención, los datos deben analizarse o enviarse a cualquier almacenamiento, según los requisitos del usuario.
- Si los datos deben enviarse a Redshift, primero deben trasladarse al Servicio de almacenamiento simple y deben copiarse a Redshift desde allí.
- Pero, en el caso de Elastic Search, los datos se pueden alimentar directamente de forma similar al Servicio de almacenamiento simple.
3. Kinesis Analytics
Kinesis Firehose permite ejecutar las consultas SQL en los datos que están presentes en Kinesis Firehose. Usando estas consultas SQL, los datos pueden almacenarse en Redshift, Simple Storage Service, ElasticSearch, etc.
Arquitectura de AWS Kinesis
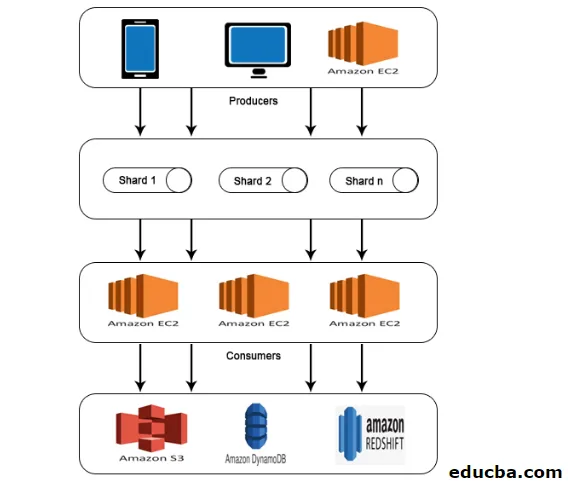
AWS Kinesis Architecture consta de
- Productores
- Fragmentos
- Los consumidores
- Almacenamiento
De manera similar al trabajo explicado en AWS Kinesis Data Stream, los datos de los productores se introducen en fragmentos donde los datos se procesan y analizan. Los datos analizados luego se mueven a instancias EC2 para realizar ciertas aplicaciones. Por último, los datos se almacenarán en cualquiera de los servicios web de Amazon, como S3, Redshift, etc.
¿Cómo usar AWS kinesis?
Para trabajar con AWS Kinesis, se deben realizar los siguientes dos pasos.
1. Instale la interfaz de línea de comandos (CLI) de AWS.
La instalación de la interfaz de línea de comandos es diferente para diferentes sistemas operativos. Por lo tanto, instale CLI según su sistema operativo.
Para usuarios de Linux, use el comando sudo pip install AWS CLI
Asegúrese de tener una versión de Python 2.6.5 o superior. Después de descargar, configúrelo con el comando de configuración de AWS. Luego, se le pedirán los siguientes detalles como se muestra a continuación.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Para usuarios de Windows, descargue el instalador MSI apropiado y ejecútelo.
2. Realizar operaciones de Kinesis usando CLI
Tenga en cuenta que las secuencias de datos de Kinesis no están disponibles para el nivel gratuito de AWS. Por lo tanto, las transmisiones de Kinesis creadas se cobrarán.
Ahora veamos algunas operaciones de kinesis en CLI.
- Crear secuencia
Cree una secuencia KStream con Shard count 2 usando el siguiente comando.
aws kinesis create-stream --stream-name KStream --shard-count 2
Comprueba si la transmisión se ha creado.
aws kinesis describe-stream --stream-name KStream
Si se crea, aparecerá un resultado similar al siguiente ejemplo.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Poner registro
Ahora, se puede insertar un registro de datos usando el comando put-record. Aquí, un registro que contiene una prueba de datos se inserta en la secuencia.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Si la inserción es exitosa, la salida se mostrará como se muestra a continuación.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Obtener registro
Primero, el usuario necesita obtener el iterador de fragmento que representa la posición de la secuencia para el fragmento.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Luego, ejecute el comando utilizando el iterador de fragmento obtenido.
aws kinesis get-records --shard-iterator ###########
Se obtendrá una salida de muestra como se muestra a continuación.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Limpiar
Para evitar cargos, la secuencia creada se puede eliminar con el siguiente comando.
aws kinesis delete-stream --stream-name KStream
Conclusión
AWS Kinesis es una plataforma que recopila, procesa y analiza la transmisión de datos para varias aplicaciones como aprendizaje automático, análisis predictivo, etc. La transmisión de datos puede tener cualquier formato, como audio, video, datos de sensores, etc.
Artículos recomendados
Esta es una guía de AWS Kinesis. Aquí discutimos cómo usar AWS Kinesis y también su Servicio con trabajo y Arquitectura. También puede consultar el siguiente artículo para obtener más información:
- Arquitectura de AWS
- ¿Qué es AWS Lambda?
- Tecnologías de Big Data
- Arquitectura de minería de datos
- Servicios de almacenamiento de AWS
- Guía para competidores de AWS con características