
Diferencias entre Data Scientist y Machine Learning
Un científico de datos es un experto responsable de recopilar, examinar e interpretar grandes volúmenes de datos para reconocer formas de ayudar a una empresa a mejorar las operaciones y obtener una ventaja viable sobre sus rivales. Sigue un enfoque interdisciplinario. Se encuentra entre la conexión de matemática, estadística, ingeniería de software, inteligencia artificial y pensamiento de diseño. Se trata de la recopilación de datos, limpieza, análisis, visualización, modelo de validación, predicción de experimentos, diseño, pruebas e hipótesis, muchos más. El aprendizaje automático es una división de la inteligencia artificial que utiliza la ciencia de datos para alcanzar sus objetivos. El aprendizaje automático se centra principalmente en algoritmos, estructuras polinómicas y adición de palabras. Consiste en un grupo de algoritmos, máquinas y les permite aprender sin estar claramente programados para ello.
Científico de datos
Este rol de Data Scientist es una rama del rol de las estadísticas que incluye el uso de la versión avanzada de tecnologías analíticas, incluido el aprendizaje automático y el modelado predictivo, para proporcionar visiones más allá del análisis estadístico. La petición de habilidades de ciencia de datos ha crecido significativamente en los últimos años a medida que las empresas buscan recopilar información útil de las enormes cantidades de datos estructurados, semiestructurados y no estructurados que una gran empresa produce y se conoce colectivamente como big data. El objetivo de todos los pasos es simplemente obtener información de los datos.
Tareas estándar:
- Asigne, agregue y sintetice datos de varias fuentes estructuradas y no estructuradas
- Explore, desarrolle y aplique el aprendizaje inteligente a datos del mundo real, proporcione hallazgos importantes y acciones exitosas basadas en ellos
- Analizar y proporcionar datos recopilados en la organización.
- Diseñe y cree nuevos procesos para modelado, minería de datos e implementación
- Desarrollar prototipos, algoritmos, modelos predictivos, prototipos.
- Realizar solicitudes de análisis de datos y comunicar sus hallazgos y decisiones.
Además, hay tareas más específicas según el dominio en el que el empleador esté trabajando o el proyecto se esté implementando.
Datos sin procesar -> Ciencia de datos ---> Información práctica
Aprendizaje automático
El puesto de Ingeniero de Aprendizaje Automático es más "técnico". ML Engineer tiene más en común con la Ingeniería de Software clásica que con Data Scientist. Le ayuda a aprender la función objetivo que traza las entradas a la variable objetivo y / o las variables independientes a las variables dependientes.
Las tareas estándar de ML Engineer son generalmente como Data Scientist. También debe poder trabajar con datos, experimentar con varios algoritmos de Machine Learning que resolverán la tarea, crear prototipos y soluciones listas para usar.
El conocimiento y las habilidades requeridas para este puesto también se superponen con Data Scientist. De las diferencias clave, destacaría:
- Fuertes habilidades de programación en uno o más lenguajes populares (generalmente Python y Java), así como en bases de datos;
- Menos énfasis en la capacidad de trabajar en entornos de análisis de datos, pero más énfasis en algoritmos de Machine Learning;
- R y Python para modelar son preferibles a Matlab, SPSS y SAS;
- Posibilidad de utilizar bibliotecas listas para usar para varias pilas en la aplicación, por ejemplo, Mahout, Lucene para Java, NumPy / SciPy para Python;
- Capacidad para crear aplicaciones distribuidas utilizando Hadoop y otras soluciones.
Como puede ver, el puesto de Ingeniero de ML (o más limitado) requiere más conocimiento en Ingeniería de Software y, en consecuencia, es muy adecuado para desarrolladores experimentados. Muy a menudo, el caso funciona cuando el desarrollador habitual debe resolver la tarea de ML para su deber, y comienza a comprender los algoritmos y bibliotecas necesarios.
Comparación directa entre el científico de datos y el aprendizaje automático
A continuación se muestran las 5 principales diferencias entre el científico de datos y el ingeniero de aprendizaje automático 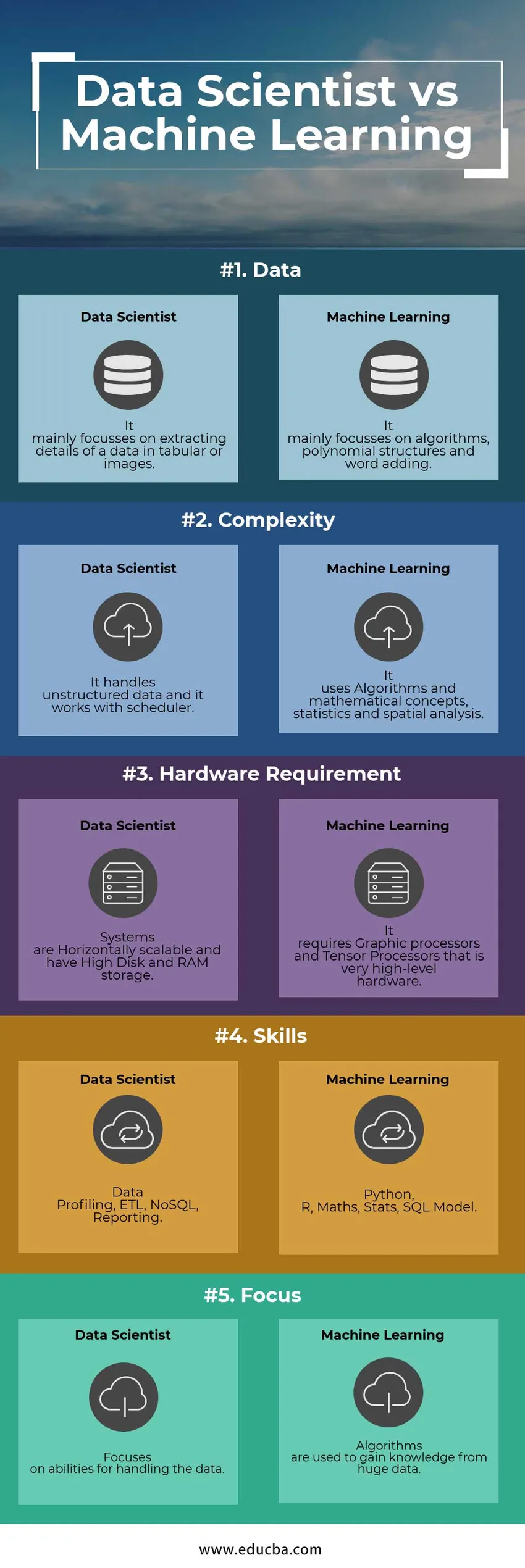
Diferencia clave entre el científico de datos y el aprendizaje automático
A continuación se encuentran las listas de puntos, describa las diferencias clave entre el científico de datos y el ingeniero de aprendizaje automático
- El aprendizaje automático y las estadísticas son parte de la ciencia de datos. La palabra aprendizaje en aprendizaje automático significa que los algoritmos dependen de algunos datos, utilizados como un conjunto de entrenamiento, para ajustar algunos parámetros del modelo o algoritmo. Esto abarca muchas técnicas, como la regresión, la ingenua Bayes o la agrupación supervisada. Pero no todas las técnicas encajan en esta categoría. Por ejemplo, la agrupación no supervisada, una técnica estadística y de ciencia de datos, tiene como objetivo detectar agrupaciones y estructuras de agrupaciones sin ningún conocimiento previo o conjunto de capacitación para ayudar al algoritmo de clasificación. Se necesita un ser humano para etiquetar los grupos encontrados. Algunas técnicas son híbridas, como la clasificación semi-supervisada. Algunas técnicas de detección de patrones o de estimación de densidad encajan en esta categoría.
- Sin embargo, la ciencia de datos es mucho más que aprendizaje automático. Los datos, en la ciencia de los datos, pueden provenir o no de una máquina o un proceso mecánico (los datos de la encuesta se pueden recopilar manualmente, los ensayos clínicos involucran un tipo específico de datos pequeños) y puede que no tenga nada que ver con el aprendizaje, como acabo de comentar. Pero la principal diferencia es el hecho de que la ciencia de datos cubre todo el espectro del procesamiento de datos, no solo los aspectos algorítmicos o estadísticos. La ciencia de datos también cubre la integración de datos, la arquitectura distribuida, el aprendizaje automático, la visualización de datos, los paneles y la ingeniería de Big Data.
Tabla comparativa de Data Scientist vs Machine Learning
Las siguientes son las listas de puntos, describa las comparaciones entre el científico de datos y el ingeniero de aprendizaje automático:
| Característica | Científico de datos | Aprendizaje automático |
| Datos | Se centra principalmente en la extracción de detalles de datos en tablas o imágenes. | Se centra principalmente en algoritmos, estructuras polinómicas y adición de palabras. |
| Complejidad | Maneja datos no estructurados y funciona con el planificador. | Utiliza algoritmos y conceptos matemáticos, estadísticas y análisis espacial. |
| Requisito de hardware | Los sistemas son escalables horizontalmente y tienen un alto almacenamiento en disco y RAM | Requiere procesadores gráficos y procesadores de tensor que es hardware de muy alto nivel |
| Habilidades | Perfiles de datos, ETL, NoSQL, Informes | Python, R, Matemáticas, Estadísticas, Modelo SQL |
| Atención | Se centra en las habilidades para manejar los datos. | Los algoritmos se utilizan para obtener conocimiento a partir de grandes datos. |
Conclusión: Data Scientist vs Machine Learning
El aprendizaje automático lo ayuda a aprender la función objetivo que traza las entradas a la variable objetivo y / o las variables independientes a las variables dependientes
Un científico de datos explora mucho los datos y llega a la estrategia general de cómo abordarlos. Es responsable de hacer preguntas dentro de los datos y encontrar qué respuestas se pueden obtener razonablemente de los datos. La ingeniería de características pertenece al ámbito de Data Scientist. La creatividad también juega un papel aquí y un ingeniero de Machine Learning conoce más herramientas y puede construir modelos dados un conjunto de características y datos, según las instrucciones del Científico de datos. El ámbito del preprocesamiento de datos y la extracción de características pertenece al ingeniero de ML.
La ciencia y el examen de datos utilizan el aprendizaje automático para este tipo de validación y creación arquetípica. Es vital tener en cuenta que todos los algoritmos en la creación de este modelo pueden no provenir del aprendizaje automático. Pueden llegar desde muchos otros campos. El modelo desea ser relevante siempre. Si las situaciones cambian, entonces el modelo que creamos anteriormente puede ser irrelevante. Los requisitos del modelo deben verificarse para garantizar su certeza en diferentes momentos y deben adaptarse si su certeza se reduce.
La ciencia de datos es un gran dominio. Si tratamos de ponerlo en marcha, tendría adquisición de datos, almacenamiento de datos, procesamiento previo de datos o limpieza de datos, patrones de aprendizaje en los datos (a través del aprendizaje automático), uso del aprendizaje para las predicciones. Esta es una forma de entender cómo el aprendizaje automático se adapta a la ciencia de datos.
Artículo recomendado
Esta ha sido una guía de las diferencias entre el científico de datos y el ingeniero de aprendizaje automático, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- Minería de datos vs aprendizaje automático: 10 mejores cosas que debe saber
- Aprendizaje automático versus análisis predictivo: 7 diferencias útiles
- Data Scientist vs Business Analyst: descubra las 5 increíbles diferencias
- Data Scientist vs Data Engineer - 7 comparaciones asombrosas
- Preguntas de la entrevista de ingeniería de software | Superior y más preguntado