
 Diferencias entre el aprendizaje supervisado y el aprendizaje profundo
Diferencias entre el aprendizaje supervisado y el aprendizaje profundo
En el aprendizaje supervisado, los datos de capacitación que usted proporciona al algoritmo incluyen las soluciones deseadas, llamadas etiquetas. Una tarea típica de aprendizaje supervisado es la clasificación. El filtro de spam es un buen ejemplo de esto: está entrenado con muchos correos electrónicos de ejemplo junto con su clase (spam o ham), y debe aprender cómo clasificar nuevos correos electrónicos.
El aprendizaje profundo es un intento de imitar la actividad en capas de neuronas en la neocorteza, que es aproximadamente el 80% del cerebro donde se produce el pensamiento (en un cerebro humano, hay alrededor de 100 mil millones de neuronas y 100 ~ 1000 billones de sinapsis). Se llama profundo porque tiene más de una capa oculta de neuronas que ayudan a tener múltiples estados de transformación de características no lineales.
Comparación directa de aprendizaje supervisado versus aprendizaje profundo (infografía)
A continuación se muestra la comparación entre los 5 principales entre el aprendizaje supervisado y el aprendizaje profundo 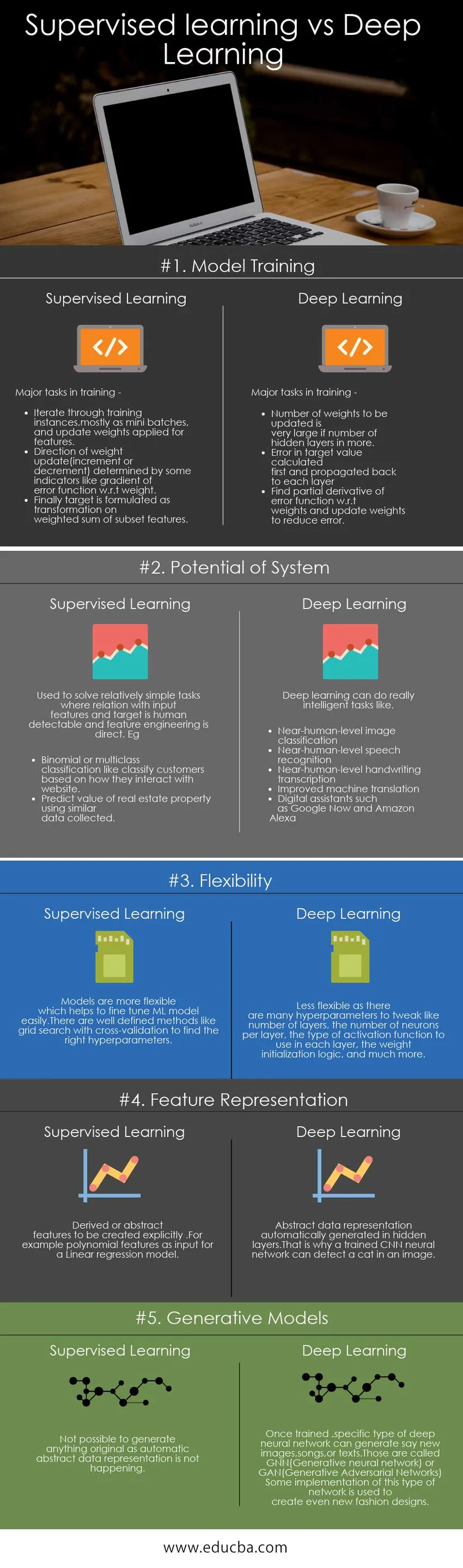
Diferencias clave entre el aprendizaje supervisado y el aprendizaje profundo
Tanto el aprendizaje supervisado como el aprendizaje profundo son opciones populares en el mercado; Discutamos algunas de las principales diferencias entre el aprendizaje supervisado y el aprendizaje profundo:
● Modelos principales -
Los modelos supervisados importantes son:
○ Vecinos k-más cercanos: se utilizan para clasificación y regresión
○ Regresión lineal: para predicción / regresión
○ Regresión logística: para clasificación
○ Máquinas de vectores de soporte (SVM): se utilizan para clasificación y regresión
○ Árboles de decisión y bosques aleatorios: tareas de clasificación y regresión
Redes neuronales profundas más populares:
● Perceptrones multicapa (MLP) : tipo más básico. Esta red es generalmente la fase de inicio de la construcción de otra red profunda más sofisticada y se puede usar para cualquier problema de regresión supervisada o clasificación
● Autoencoders (AE) : la red tiene algoritmos de aprendizaje no supervisados para el aprendizaje de funciones, la reducción de dimensiones y la detección de valores atípicos.
● Red neuronal de convolución (CNN) : particularmente adecuada para datos espaciales, reconocimiento de objetos y análisis de imágenes utilizando estructuras de neuronas multidimensionales. Una de las principales razones de la popularidad del aprendizaje profundo últimamente se debe a las CNN.
● Red neuronal recurrente (RNN) : los RNN se utilizan para el análisis de datos secuenciados, como series de tiempo, análisis de sentimientos, PNL, traducción de idiomas, reconocimiento de voz, subtítulos de imágenes. Uno de los tipos más comunes de modelo RNN es la red de memoria de corto plazo (LSTM).
● Datos de capacitación : como se mencionó anteriormente, los modelos supervisados necesitan datos de capacitación con etiquetas. Pero el aprendizaje profundo puede manejar datos con o sin etiquetas. Algunas arquitecturas de redes neuronales pueden estar sin supervisión, como los codificadores automáticos y las máquinas de Boltzmann restringidas.
● Selección de características : algunos modelos supervisados son capaces de analizar características y un subconjunto de características para determinar el objetivo. Pero la mayoría de las veces esto debe manejarse en la fase de preparación de datos. Pero en Deep Neural Networks, surgen nuevas características y las características no deseadas se descartan a medida que avanza el aprendizaje.
● Representación de datos : en los modelos supervisados clásicos, no se crea la abstracción de alto nivel de las características de entrada. Modelo final que intenta predecir la salida aplicando transformaciones matemáticas en un subconjunto de características de entrada.
Pero en las redes neuronales profundas, las abstracciones de las características de entrada se forman internamente. Por ejemplo, al traducir texto, la red neuronal primero convierte el texto de entrada a codificación interna y luego transforma esa representación abstracta en el idioma de destino.
● Marco: los modelos ML supervisados son compatibles con muchos marcos genéricos ML en diferentes idiomas: Apache Mahout, Scikit Learn, Spark ML son algunos de estos.
Los marcos de aprendizaje de Majority Deep proporcionan una abstracción amigable para el desarrollador para crear una red fácilmente, se encargan de distribuir la computación y tienen soporte para GPU. Caffe, Caffe2, Theano, Torch, Keras, CNTK, TensorFlow son marcos populares. ahora con el apoyo activo de la comunidad.
Tabla comparativa de aprendizaje supervisado vs aprendizaje profundo
A continuación se muestra una comparación clave entre el aprendizaje supervisado y el aprendizaje profundo
| La base de comparación entre el aprendizaje supervisado y el aprendizaje profundo | Aprendizaje supervisado | Aprendizaje profundo |
| Entrenamiento modelo | Tareas principales en el entrenamiento -
| Tareas principales en el entrenamiento -
|
| Potencial del sistema | Se usa para resolver tareas relativamente simples donde la relación con las características de entrada y el objetivo es detectable por el hombre y la ingeniería de características es directa. P.ej :
| El aprendizaje profundo puede hacer tareas realmente inteligentes como
|
| Flexibilidad | Los modelos son más flexibles, lo que ayuda a afinar fácilmente el modelo ML. Existen métodos bien definidos como la búsqueda de cuadrícula con validación cruzada para encontrar los hiperparámetros correctos | Menos flexible ya que hay muchos hiperparámetros para ajustar como una serie de capas, la cantidad de neuronas por capa, el tipo de función de activación a usar en cada capa, la lógica de inicialización del peso y mucho más. |
| Representación de funciones | Características derivadas o abstractas que se crearán explícitamente. Por ejemplo, características polinómicas como entrada para un modelo de regresión lineal | Representación de datos abstractos generada automáticamente en capas ocultas. Es por eso que una red neuronal CNN capacitada puede detectar un gato en una imagen. |
| Modelos generativos | No es posible generar nada original ya que la representación automática de datos abstractos no está sucediendo | Una vez entrenado, un tipo específico de red neuronal profunda puede generar, por ejemplo, nuevas imágenes, canciones o textos. Esos se llaman GNN (red neuronal generativa) o GAN (redes adversas generativas)
Algunas implementaciones de este tipo de red se utilizan para crear incluso nuevos diseños de moda. |
Conclusión: aprendizaje supervisado vs aprendizaje profundo
La precisión y la capacidad de DNN (Deep Neural Network) han aumentado mucho en los últimos años. Es por eso que ahora los DNN son un área de investigación activa y, creemos, tiene el potencial de desarrollar un Sistema inteligente general. Al mismo tiempo, es difícil razonar por qué un DNN da una salida particular que hace que el ajuste de una red sea realmente difícil. Por lo tanto, si se puede resolver un problema utilizando modelos ML simples, se recomienda encarecidamente utilizarlo. Debido a este hecho, una regresión lineal simple tendrá relevancia incluso si se desarrolla un sistema inteligente general utilizando DNN.
Artículo recomendado
Esta ha sido una guía de las principales diferencias entre el aprendizaje supervisado y el aprendizaje profundo. Aquí también discutimos las diferencias clave de Aprendizaje supervisado vs Aprendizaje profundo con infografías y la tabla de comparación. También puede echar un vistazo a los siguientes artículos:
- Aprendizaje supervisado vs Aprendizaje de refuerzo
- Aprendizaje supervisado vs aprendizaje no supervisado
- Redes neuronales vs aprendizaje profundo
- Aprendizaje automático versus análisis predictivo
- TensorFlow vs Caffe: ¿Cuáles son las diferencias?
- ¿Qué es el aprendizaje supervisado?
- ¿Qué es el aprendizaje por refuerzo?
- Las 6 mejores comparaciones entre CNN y RNN