

Introducción a AWS EMR
AWS EMR proporciona muchas funcionalidades que nos facilitan las cosas, algunas de las tecnologías son:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Lambda amazónica
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
Uno de los principales servicios proporcionados por AWS EMR y con el que vamos a tratar es Amazon EMR.
EMR, comúnmente llamado Elastic Map Reduce, ofrece una forma fácil y accesible de manejar el procesamiento de grandes cantidades de datos. Imagine un escenario de big data en el que tenemos una gran cantidad de datos y estamos realizando un conjunto de operaciones sobre ellos, digamos que se está ejecutando un trabajo de Map-Reduce, uno de los principales problemas que enfrenta la aplicación Bigdata es el ajuste del programa, nosotros a menudo les resulta difícil ajustar nuestro programa de tal manera que todos los recursos asignados se consuman correctamente. Debido a este factor de ajuste anterior, el tiempo necesario para el procesamiento aumenta gradualmente. Elastic Map Reduce el servicio de Amazon, es un servicio web que proporciona un marco que gestiona todas estas características necesarias para el procesamiento de Big Data de una manera rentable, rápida y segura. Desde la creación de clústeres hasta la distribución de datos en varias instancias, todas estas cosas se administran fácilmente con Amazon EMR. Los servicios aquí disponibles son a pedido, lo que significa que podemos controlar los números en función de los datos que tenemos que son rentables y escalables.
Razones para usar AWS EMR
Entonces, ¿por qué usar AMR lo que lo hace mejor de los demás? A menudo nos encontramos con un problema muy básico en el que no podemos asignar todos los recursos disponibles a través del clúster a ninguna aplicación, AMAZON EMR se ocupa de estos problemas y, según el tamaño de los datos y la demanda de la aplicación, asigna el recurso necesario. Además, al ser de naturaleza elástica podemos cambiarlo en consecuencia. EMR tiene una gran compatibilidad de aplicaciones, ya sea Hadoop, Spark, HBase, lo que facilita el procesamiento de datos. Admite varias operaciones ETL de forma rápida y rentable. También se puede usar para MLIB en Spark. Podemos realizar varios algoritmos de aprendizaje automático en su interior. Ya se trate de datos por lotes o de transmisión de datos en tiempo real, EMR es capaz de organizar y procesar ambos tipos de datos.
Funcionamiento de AWS EMR
Ahora veamos este diagrama del clúster de Amazon EMR e intentaremos comprender cómo funciona realmente:
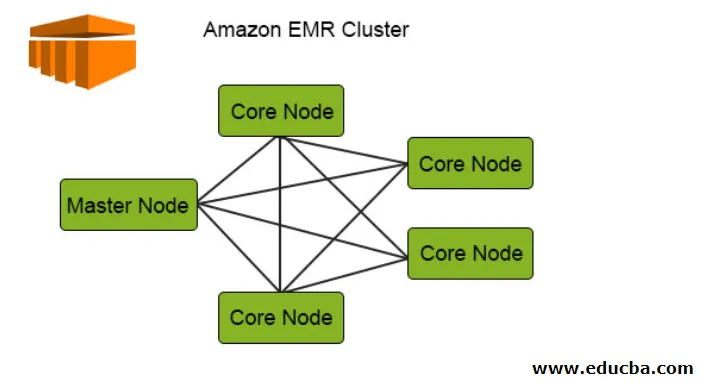
El siguiente diagrama muestra la distribución de clúster de EMR interno. Vamos a ver eso en detalle:
1. Los Clusters son el componente central en la arquitectura de Amazon EMR. Son una colección de instancias EC2 llamadas nodos. Cada nodo tiene sus roles específicos dentro del clúster denominados como tipo de nodo y, en función de sus roles, podemos clasificarlos en 3 tipos:
- Nodo maestro
- Nodo central
- Nodo de tarea
2. El nodo maestro, como su nombre lo indica, es el maestro responsable de administrar el clúster, ejecutar los componentes y la distribución de datos a través de los nodos para su procesamiento. Simplemente realiza un seguimiento de si todo se gestiona correctamente y funciona bien y funciona en caso de falla.
3. El nodo central tiene la responsabilidad de ejecutar la tarea y almacenar los datos en HDFS en el clúster. Todas las partes de procesamiento son manejadas por el Nodo central y los datos después de ese procesamiento se colocan en la ubicación HDFS deseada.
4. El Nodo de tarea es opcional solo tiene el trabajo para ejecutar la tarea, esto no almacena los datos en HDFS.
5. Siempre después de enviar un trabajo, tenemos varios métodos para elegir cómo deben completarse los trabajos. Ya sea desde la terminación del clúster después de la finalización del trabajo hasta un clúster de larga ejecución utilizando la consola EMR y la CLI para enviar pasos, tenemos todo el privilegio de hacerlo.
6. Podemos ejecutar directamente el trabajo en el EMR conectándolo con el nodo maestro a través de las interfaces y herramientas disponibles que ejecutan trabajos directamente en el clúster.
7. También podemos ejecutar nuestros datos en varios pasos con la ayuda de EMR, todo lo que tenemos que hacer es enviar uno o más pasos ordenados en el clúster EMR. Los datos se almacenan como un archivo y se procesan de manera secuencial. Comenzando desde el "estado pendiente hasta el estado completado", podemos rastrear los pasos de procesamiento y encontrar los errores que también se encuentran en 'No se pudo cancelar'. Todos estos pasos se pueden rastrear fácilmente hasta esto.
8. Una vez que se termina toda la instancia, se alcanza el estado completado para el clúster.
Arquitectura para AWS EMR
La arquitectura de EMR se presenta a partir de la parte de almacenamiento a la parte de Aplicación.
- La primera capa viene con la capa de almacenamiento que incluye diferentes sistemas de archivos utilizados con nuestro clúster. Ya sea desde HDFS a EMRFS al sistema de archivos local, todos estos se utilizan para el almacenamiento de datos en toda la aplicación. El almacenamiento en caché de los resultados intermedios durante el procesamiento de MapReduce se puede lograr con la ayuda de estas tecnologías que vienen con EMR.
- La segunda capa viene con la administración de recursos para el clúster, esta capa es responsable de la administración de recursos para los clústeres y nodos sobre la aplicación. Básicamente, esto ayuda como herramientas de administración que ayudan a distribuir uniformemente los datos sobre el clúster y la administración adecuada. La herramienta de administración de recursos predeterminada que utiliza EMR es YARN, que se introdujo en Apache Hadoop 2.0. Administra de manera centralizada los recursos para múltiples marcos de procesamiento de datos. Se encarga de toda la información necesaria para el buen funcionamiento del clúster, desde la salud del nodo hasta la distribución de recursos con gestión de memoria.
- La tercera capa viene con el marco de procesamiento de datos, esta capa es responsable del análisis y el procesamiento de datos. EMR admite muchos marcos que juegan un papel importante en el procesamiento paralelo y eficiente de datos. Parte del marco que admite y que conocemos es APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- La cuarta capa incluye la aplicación y programas como HIVE, PIG, biblioteca de transmisión, algoritmos ML que son útiles para procesar y administrar grandes conjuntos de datos.
Ventajas de AWS EMR
Veamos ahora algunos de los beneficios de usar EMR:
- Alta velocidad: dado que todos los recursos se utilizan correctamente, el tiempo de procesamiento de la consulta es comparativamente más rápido que el de las otras herramientas de procesamiento de datos.
- Procesamiento de datos a granel: sea más grande que el tamaño de datos EMR tiene la capacidad de procesar una gran cantidad de datos en un tiempo amplio.
- Pérdida mínima de datos: dado que los datos se distribuyen a través del clúster y se procesan paralelamente a través de la red, existe una mínima posibilidad de pérdida de datos y, además, la tasa de precisión de los datos procesados es mejor.
- Rentable: al ser rentable, es más barato que cualquier otra alternativa disponible que lo haga fuerte sobre el uso de la industria. Dado que el precio es menor, podemos acomodar una gran cantidad de datos y procesarlos dentro del presupuesto.
- AWS Integrated: está integrado con todos los servicios de AWS que facilita la disponibilidad bajo un techo para que la seguridad, el almacenamiento y la conexión en red estén integrados en un solo lugar.
- Seguridad: viene con un increíble grupo de seguridad para controlar el tráfico entrante y saliente; además, el uso de los roles de IAM lo hace más seguro, ya que ofrece varios permisos que aseguran los datos.
- Monitoreo e implementación: tenemos herramientas de monitoreo adecuadas para todas las aplicaciones que se ejecutan en clústeres EMR que lo hacen transparente y fácil para la parte de análisis, además viene con una función de autodespliegue donde la aplicación se configura e implementa automáticamente.
Hay muchas más ventajas de tener EMR como una mejor opción para otro método de cálculo de clúster.
Precios de AWS EMR
EMR viene con una increíble lista de precios que atrae a los desarrolladores o al mercado hacia ella. Dado que viene con una función de fijación de precios a pedido, podemos usarla por poco más de una hora y por la cantidad de nodos en nuestro clúster. Podemos pagar una tarifa por segundo por cada segundo que usemos con un minuto como mínimo. También podemos elegir nuestras instancias para utilizarlas como instancias reservadas o instancias puntuales, lo que supone un gran ahorro de costes.
Podemos calcular la factura total a través de una calculadora mensual simple desde el siguiente enlace: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Para obtener más detalles sobre los detalles de precios exactos, puede consultar el documento a continuación de Amazon: -
https://aws.amazon.com/emr/pricing/
Conclusión
En el artículo anterior, vimos cómo EMR se puede utilizar para el procesamiento justo de grandes datos con todos los recursos utilizados de manera convencional.
Tener EMR resuelve nuestro problema básico de procesamiento de datos y reduce en gran medida el tiempo de procesamiento, siendo rentable, es fácil y conveniente de usar.
Artículo recomendado
Esta ha sido una guía para AWS EMR. Aquí discutimos una introducción a AWS EMR a lo largo de su trabajo y la arquitectura, así como las ventajas. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Alternativas de AWS
- Comandos de AWS
- Servicios de AWS
- Preguntas de la entrevista de AWS
- Servicios de almacenamiento de AWS
- Los 7 principales competidores de AWS
- Lista de características de los servicios web de Amazon