
Introducción a las técnicas de conjunto
El aprendizaje conjunto es una técnica de aprendizaje automático que toma la ayuda de varios modelos básicos y combina sus resultados para producir un modelo optimizado. Este tipo de algoritmo de aprendizaje automático ayuda a mejorar el rendimiento general del modelo. Aquí el modelo base que se usa más comúnmente es el clasificador de árbol de decisión. Un árbol de decisión básicamente funciona en varias reglas y proporciona un resultado predictivo, donde las reglas son los nodos y sus decisiones serán sus hijos y los nodos hoja constituirán la decisión final. Como se muestra en el ejemplo de un árbol de decisión.
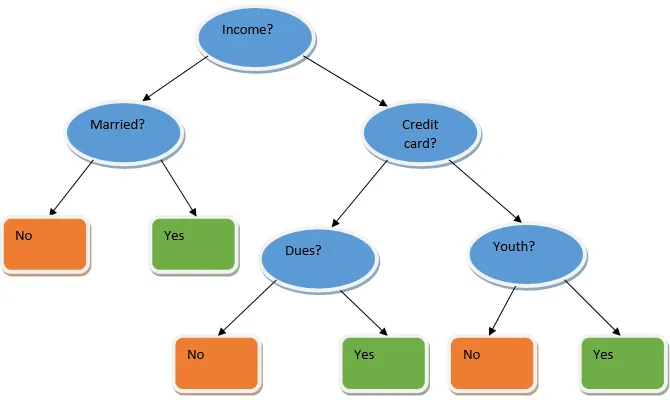
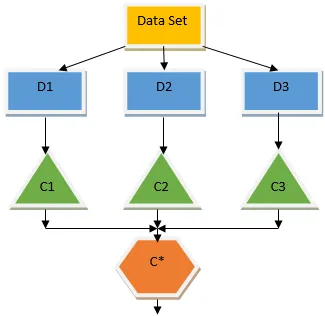
El árbol de decisión anterior básicamente habla sobre si una persona / cliente puede recibir un préstamo o no. Una de las reglas para la elegibilidad de préstamos sí es que si (ingreso = Sí y & Casado = No) Entonces Préstamo = Sí, así es como funciona un clasificador de árbol de decisión. Incorporaremos estos clasificadores como un modelo base múltiple y combinaremos su salida para construir un modelo predictivo óptimo. La figura 1.b muestra la imagen general de un algoritmo de aprendizaje conjunto.
Tipos de técnicas de conjuntos
Diferentes tipos de conjuntos, pero nuestro enfoque principal estará en los dos tipos siguientes:
- Harpillera
- Impulsar
Estos métodos ayudan a reducir la varianza y el sesgo en un modelo de aprendizaje automático. Ahora intentemos comprender qué es el sesgo y la varianza. El sesgo es un error que ocurre debido a suposiciones incorrectas en nuestro algoritmo; un sesgo alto indica que nuestro modelo es demasiado simple / poco ajustado. La varianza es el error causado por la sensibilidad del modelo a fluctuaciones muy pequeñas en el conjunto de datos; una variación alta indica que nuestro modelo es altamente complejo / sobreajustado. Un modelo ML ideal debería tener un equilibrio adecuado entre sesgo y varianza.
Bootstrap Agregando / Embolsado
El ensacado es una técnica de conjunto que ayuda a reducir la variación en nuestro modelo y, por lo tanto, evita el sobreajuste. El ensacado es un ejemplo del algoritmo de aprendizaje paralelo. El ensacado funciona según dos principios.
- Bootstrapping: a partir del conjunto de datos original, se consideran diferentes poblaciones de muestra con reemplazo.
- Agregación: promediando los resultados de todos los clasificadores y proporcionando un resultado único, para esto, utiliza el voto mayoritario en el caso de la clasificación y el promedio en el caso del problema de regresión. Uno de los famosos algoritmos de aprendizaje automático que utilizan el concepto de embolsado es un bosque aleatorio.
Bosque al azar
En el bosque aleatorio de la muestra aleatoria extraída de la población con reemplazo y se selecciona un subconjunto de características del conjunto de todas las características, se construye un árbol de decisión. De estos subconjuntos de características, cualquier característica que ofrezca la mejor división se selecciona como la raíz del árbol de decisión. El subconjunto de características debe elegirse al azar a cualquier costo; de lo contrario, terminaremos produciendo solo trenzas correlacionadas y la varianza del modelo no mejorará.
Ahora que hemos construido nuestro modelo con las muestras tomadas de la población, la pregunta es ¿cómo validamos el modelo? Como estamos considerando las muestras con reemplazo, por lo tanto, no se considerarán todas las muestras y algunas de ellas no se incluirán en ninguna bolsa, estas se denominan muestras de bolsa. Podemos validar nuestro modelo con estas muestras OOB (fuera de bolsa). Los parámetros importantes a considerar en un bosque aleatorio es el número de muestras y el número de árboles. Consideremos 'm' como el subconjunto de características y 'p' es el conjunto completo de características, ahora como regla general, siempre es ideal elegir
- m as√y un tamaño mínimo de nodo como 1 para un problema de clasificación.
- m como P / 3 y el tamaño mínimo de nodo debe ser 5 para un problema de regresión.
El myp deben tratarse como parámetros de ajuste cuando tratamos un problema práctico. El entrenamiento se puede finalizar una vez que el error OOB se estabilice. Un inconveniente del bosque aleatorio es que cuando tenemos 100 características en nuestro conjunto de datos y solo un par de características son importantes, entonces este algoritmo funcionará mal.
Impulsar
Boosting es un algoritmo de aprendizaje secuencial que ayuda a reducir el sesgo en nuestro modelo y la varianza en algunos casos de aprendizaje supervisado. También ayuda a convertir a los alumnos débiles en alumnos fuertes. El refuerzo funciona según el principio de ubicar secuencialmente a los alumnos débiles y asigna un peso a cada punto de datos después de cada ronda; Se asigna más peso al punto de datos mal clasificado en la ronda anterior. Este método secuencial ponderado de entrenamiento de nuestro conjunto de datos es la diferencia clave con respecto al embolsado.
La figura 3.a muestra el enfoque general para impulsar
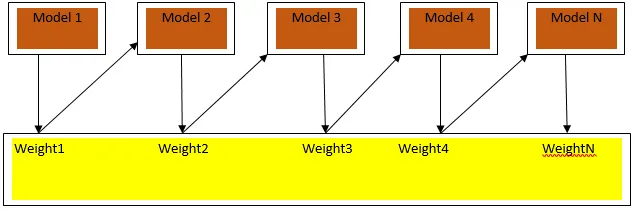
Las predicciones finales se combinan en función de la votación por mayoría ponderada en el caso de clasificación y la suma ponderada en el caso de regresión. El algoritmo de refuerzo más utilizado es el refuerzo adaptativo (Adaboost).
Impulso adaptativo
Los pasos involucrados en el algoritmo Adaboost son los siguientes:
- Para los n puntos de datos dados, definimos el objetivo con clase e inicializamos todos los pesos a 1 / n.
- Ajustamos los clasificadores al conjunto de datos y elegimos la clasificación con el error de clasificación menos ponderado
- Asignamos pesos para el clasificador mediante una regla general basada en la precisión, si la precisión es superior al 50%, entonces el peso es positivo y viceversa.
- Actualizamos los pesos de los clasificadores al final de la iteración; Actualizamos más peso para el punto mal clasificado para que en la próxima iteración lo clasifiquemos correctamente.
- Después de toda la iteración, obtenemos el resultado final de predicción basado en el voto mayoritario / promedio ponderado.
Adaboosting funciona eficientemente con estudiantes débiles (menos complejos) y con clasificadores de alto sesgo. Las principales ventajas de Adaboosting son que es rápido, no hay parámetros de ajuste similares al caso de embolsado y no hacemos suposiciones sobre los estudiantes débiles. Esta técnica no proporciona un resultado preciso cuando
- Hay más valores atípicos en nuestros datos.
- El conjunto de datos es insuficiente.
- Los alumnos débiles son muy complejos.
También son susceptibles al ruido. Los árboles de decisión que se producen como resultado del aumento tendrán una profundidad limitada y una alta precisión.
Conclusión
Las técnicas de aprendizaje en conjunto se utilizan ampliamente para mejorar la precisión del modelo; tenemos que decidir qué técnica usar según nuestro conjunto de datos. Pero estas técnicas no son preferidas en algunos casos donde la interpretabilidad es importante, ya que perdemos la interpretación a costa de la mejora del rendimiento. Estos tienen una enorme importancia en la industria del cuidado de la salud, donde una pequeña mejora en el rendimiento es muy valiosa.
Artículos recomendados
Esta es una guía de técnicas de conjunto. Aquí discutimos la introducción y dos tipos principales de técnicas de conjunto. También puede consultar nuestros otros artículos relacionados para obtener más información.
- Técnicas de esteganografía
- Técnicas de aprendizaje automático
- Técnicas de Team Building
- Algoritmos de ciencia de datos
- Técnicas más utilizadas de aprendizaje conjunto