

¿Qué es el algoritmo MapReduce?
El algoritmo MapReduce está inspirado principalmente en el modelo de programación funcional. Se utiliza para procesar y generar grandes datos. Estos conjuntos de datos pueden ejecutarse simultáneamente y distribuirse en un clúster. Un programa MapReduce consiste principalmente en un procedimiento de mapa y un método de reducción para realizar la operación de resumen, como contar o obtener algunos resultados. El sistema MapReduce funciona en servidores distribuidos que se ejecutan en paralelo y gestionan todas las comunicaciones entre diferentes sistemas. El modelo es una estrategia especial de estrategia dividir-aplicar-combinar que ayuda en el análisis de datos. El mapeo lo realiza la clase Mapper y reduce la tarea la realiza la clase Reducer.
Comprender el algoritmo MapReduce
El algoritmo MapReduce funciona principalmente en tres pasos:
- Función de mapa
- Función aleatoria
- Reducir la función
Discutamos cada función y sus responsabilidades.
1. Función de mapa
Este es el primer paso del algoritmo MapReduce. Toma los conjuntos de datos y los distribuye en subtareas más pequeñas. Esto se realiza en dos pasos, división y mapeo. La división toma el conjunto de datos de entrada y divide el conjunto de datos mientras que la asignación toma esos subconjuntos de datos y realiza la acción requerida. La salida de esta función es un par clave-valor.
2. Función aleatoria
Esto también se conoce como función de combinación e incluye fusión y clasificación. La fusión combina todos los pares clave-valor. Todos estos tendrán las mismas claves. La ordenación toma la entrada del paso de fusión y clasifica todos los pares clave-valor haciendo uso de las claves. Este paso también volverá a los pares clave-valor. La salida se ordenará.
3. Reducir la función
Este es el último paso de este algoritmo. Toma los pares clave-valor del shuffle y reduce la operación.
¿Cómo los algoritmos de MapReduce facilitan el trabajo?
Los sistemas de bases de datos relacionales tienen un servidor centralizado que ayuda a almacenar y procesar los datos. Estos eran generalmente sistemas centralizados. Cuando entran varios archivos en la imagen, el procesamiento es tedioso y crea un cuello de botella mientras procesa múltiples archivos. MapReduce asigna el conjunto de datos y convierte el conjunto de datos donde todos los datos se dividen en tuplas y la tarea de reducción tomará el resultado de este paso y combinará estas tuplas de datos en los conjuntos más pequeños. Funciona en diferentes fases y crea pares clave-valor que pueden distribuirse en diferentes sistemas.
¿Qué se puede hacer con los algoritmos de MapReduce?
MapReduce se puede usar con una variedad de aplicaciones. Se puede utilizar para búsquedas distribuidas basadas en patrones, clasificación distribuida, inversión de gráficos de enlaces web, estadísticas de registro de acceso web. También puede ayudar a crear y trabajar en múltiples clústeres, cuadrículas de escritorio y entornos informáticos voluntarios. También se pueden crear entornos dinámicos en la nube, entornos móviles y también entornos informáticos de alto rendimiento. Google hizo uso de MapReduce, que regenera el Índice de Google de la World Wide Web. Al usarlo, los antiguos programas ad hoc se actualizan y han ejecutado diferentes tipos de análisis. También integró los resultados de búsqueda en vivo sin reconstruir el índice completo. Todas las entradas y salidas se almacenan en el sistema de archivos distribuido. Los datos transitorios se almacenan en un disco local.
Trabajando con el algoritmo MapReduce
Para trabajar con el algoritmo MapReduce, debe conocer el proceso completo de cómo funciona. Los datos que se ingieren pasan por los siguientes pasos:
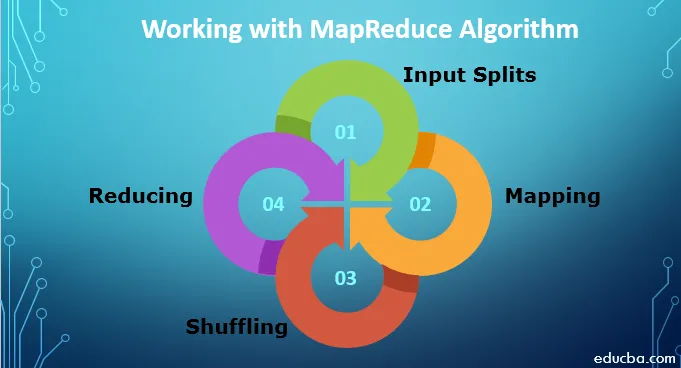
1. Divisiones de entrada: cualquier dato de entrada que provenga del trabajo MapReduce se divide en partes iguales conocidas como divisiones de entrada. Es una porción de entrada que puede ser consumida por cualquiera de los mapeadores.
2. Asignación: una vez que los datos se dividen en fragmentos, pasa por la fase de asignación en el programa de reducción de mapas. Estos datos divididos se pasan a la función de mapeo que produce diferentes valores de salida.
3. Barajar: Una vez que se realiza el mapeo, los datos se envían a esta fase. Su trabajo es amalgamar los registros requeridos de la fase anterior.
4. Reducción: en esta fase, la salida de la fase de mezcla se agrega. En esta fase, todos los valores se barajan y se agrupan por agregación para que devuelva un único valor de salida. Crea un resumen del conjunto de datos completo.
Ventajas del algoritmo MapReduce
Las aplicaciones que usan MapReduce tienen las siguientes ventajas:
- Se les ha proporcionado convergencia y buen rendimiento de generalización.
- Los datos se pueden manejar haciendo uso de aplicaciones intensivas en datos.
- Proporciona alta escalabilidad.
- Contar cualquier ocurrencia de cada palabra es fácil y tiene una colección masiva de documentos.
- Se puede utilizar una herramienta genérica para buscar herramientas en muchos análisis de datos.
- Ofrece tiempo de equilibrio de carga en grandes grupos.
- También ayuda en el proceso de extracción de contextos de ubicación del usuario, situaciones, etc.
- Puede acceder rápidamente a grandes muestras de encuestados.
¿Por qué debemos usar el algoritmo MapReduce?
MapReduce es una aplicación que se utiliza para el procesamiento de grandes conjuntos de datos. Estos conjuntos de datos se pueden procesar en paralelo. MapReduce puede crear potencialmente grandes conjuntos de datos y una gran cantidad de nodos. Estos grandes conjuntos de datos se almacenan en HDFS, lo que facilita el análisis de datos. Puede procesar cualquier tipo de datos como estructurados, no estructurados o semiestructurados.
¿Por qué necesitamos el algoritmo MapReduce?
MapReduce está creciendo rápidamente y ayuda en la computación paralela. Ayuda a determinar el precio de los productos y ayuda a obtener los mayores beneficios. También ayuda a predecir y recomendar análisis. Permite a los programadores ejecutar modelos sobre diferentes conjuntos de datos y utiliza técnicas estadísticas avanzadas y técnicas de aprendizaje automático que ayudan a predecir datos. Filtra y envía los datos a diferentes nodos dentro del clúster y funciona según el mapeador y la función reductora.
¿Cómo te ayudará esta tecnología en el crecimiento profesional?
Hadoop es uno de los trabajos más buscados en estos días. Está acelerando la tasa y la oportunidad que está creciendo muy rápido en este campo. Habrá un boom en esta área aún más. Los profesionales de TI que trabajan en Java tienen un punto positivo, ya que son las personas más buscadas. Además, los desarrolladores, los arquitectos de datos, el almacén de datos y los profesionales de BI pueden eliminar grandes cantidades de salario al aprender esta tecnología.
Conclusión
MapReduce es la base del framework Hadoop. Al aprender esto, seguramente podrá ingresar al mercado de análisis de datos. Puede aprenderlo a fondo y conocer cómo se procesan grandes conjuntos de datos y cómo esta tecnología está trayendo un cambio con el procesamiento y almacenamiento de datos.
Artículos recomendados
Esta es una guía de los algoritmos de MapReduce. Aquí discutimos el concepto, comprensión, trabajo, necesidad, ventajas y crecimiento profesional. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Preguntas de la entrevista de MapReduce
- ¿Qué es MapReduce en Hadoop?
- ¿Cómo funciona MapReduce?
- ¿Qué es MapReduce?
- Diferencias entre Hadoop y MapReduce
- Diferentes operaciones relacionadas con tuplas