
¿Qué es cassandra?
Cassandra es una base de datos NoSQL que es una base de datos distribuida de igual a igual. Se ejecuta en un clúster que tiene nodos homogéneos. Está hecho de tal manera que puede manejar grandes volúmenes de datos. Al manejar estos datos, también debería ser capaz de proporcionar una alta capacidad. Cassandra proporciona alta en todo cuando se trata de operaciones de lectura y escritura. La arquitectura del grupo de Cassandra no tiene maestros, esclavos ni líderes específicos. Al usarlo de esta manera, se asegura de que no haya un único punto de falla. Echemos un vistazo a la arquitectura en detalle.
Arquitectura Cassandra
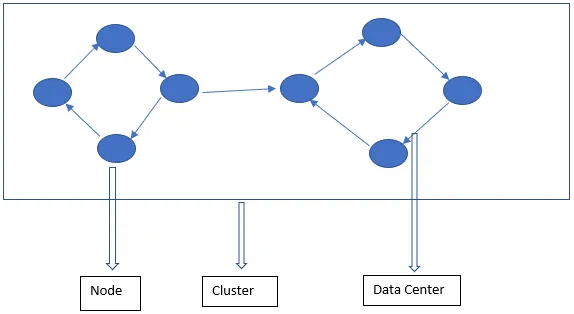
La arquitectura de Cassandra se compone principalmente de nodo, clúster y centro de datos. Además de estos, también hay otros componentes. Cassandra es una base de datos de fila almacenada. Permite a los usuarios autorizados conectarse a cualquier nodo en cualquier centro de datos usando el CQL.
Estructuras clave en Cassandra
Estas son las siguientes estructuras clave en Cassandra:
- Nodo: aquí es donde se almacenan los datos. Es el componente más básico de Cassandra. Se puede considerar como un único servidor en un rack. Asegura que no haya un único punto de falla.
- Centro de datos: un centro de datos es una colección de nodos. Esto puede ser físico o virtual. Dependiendo de la carga de trabajo, los centros de datos se dividen y se eligen. El factor de replicación se decide sobre la base del centro de datos. Dependiendo de este factor de replicación, los datos se pueden escribir en diferentes centros de datos.
- Clúster: el clúster comprende uno o más centros de datos. Los grupos generalmente abarcan diferentes ubicaciones físicas.
Además de estos, los otros componentes que juegan un papel en Cassandra son los siguientes.
1. Confirmar registro
Los datos que se comprometen para mantener la durabilidad de los datos se almacenan en el registro de confirmación. Los datos se mueven a una tabla de cadenas ordenadas (explicada a continuación). Una vez que se realiza este movimiento, el registro de confirmación se puede archivar, eliminar o reciclar.
2. Tabla SS
Esta tabla, como se mencionó en el punto anterior, almacena las tablas de registro o memoria a intervalos regulares. Es un archivo de datos inmutable. Las tablas SS pueden almacenar datos con frecuencia de manera secuencial. Anexan datos y mantienen información para cada tabla de Cassandra.
3. Tabla CQL
La tabla de Cassandra Query es una colección de columnas ordenadas que pueden obtener una fila de esta tabla. Hay columnas almacenadas en esta tabla donde se pueden obtener datos haciendo uso de la clave primaria.
4. Filtro de floración
Es un tipo simple de caché donde hay algoritmos no deterministas almacenados para la prueba. Comprueba si un elemento es miembro del conjunto o no. Generalmente se accede a estos filtros después de cada consulta que se ejecuta.
Componentes clave para configurar Cassandra
Hay los siguientes componentes en Cassandra:
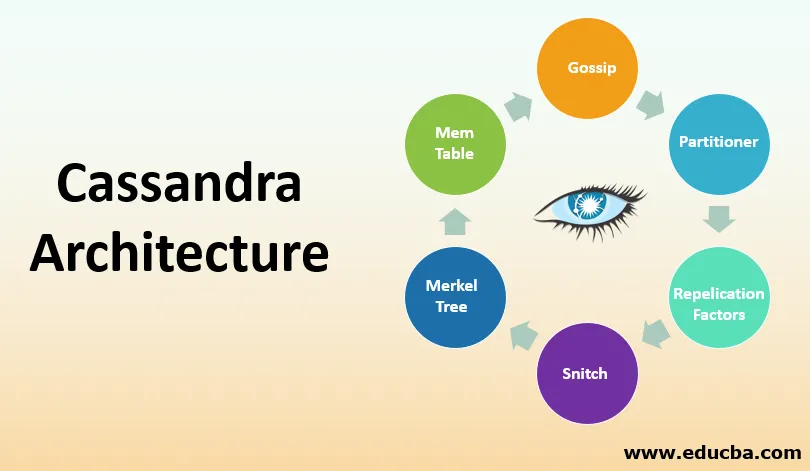
1. Chismes
- Como su nombre lo indica, tiene que haber comunicación entre pares para descubrir y compartir la ubicación y el estado de la información sobre todos los nodos.
- Esta información debe persistir en local para que cada nodo pueda usar la información tan pronto como un nodo deba reiniciarse. Los nodos descubren información sobre otros nodos mediante el intercambio de información.
- Esto se puede hacer para un máximo de tres nodos. La información no se comparte con todos los nodos que están presentes en el clúster o centro de datos. La información se comparte con algunos nodos, pero finalmente la información de estado atraviesa todo el clúster.
2. Particionador
- El particionador decide qué nodo debe recibir la primera réplica de cualquier dato. También es responsable de cuidar la distribución de estas réplicas.
- Determinará qué nodo debe tener qué replicación en el clúster. Cada fila de datos debe identificarse de manera única. Esto se puede hacer utilizando una clave primaria o una clave de partición.
- El particionador es una función hash que ayuda a obtener un token de una clave primaria de cualquier fila. Cada nodo tiene asignado un valor num_token que se puede establecer como el particionador.
- El valor de token que se genera ayuda a determinar qué nodo recibe la réplica de las filas.
3. Factor de replicación
- Este factor determina el número total de réplicas presentes en el clúster. Si el factor de replicación es 1, solo hay una copia de cada fila en un nodo.
- Del mismo modo, si el factor de replicación es dos, se mantendrán dos copias donde cada copia esté presente en un nodo diferente. Como se mencionó anteriormente, no hay una arquitectura maestro-esclavo en Cassandra, cada copia es importante.
- El factor de replicación se define para cada centro de datos. Este factor debe ser mayor que uno pero no mayor que el número de nodos presentes en el clúster.
4. Snitch
- La estrategia de replicación que ayuda a conseguir el lugar donde se colocarán las réplicas para un grupo de máquinas en el centro de datos y el bastidor se conoce como Snitch.
- Hay una capa dinámica que ayuda en la supervisión y el rendimiento y ayuda a elegir la mejor réplica de la que se pueden leer los datos. Los snitches deben configurarse solo cuando se crea un clúster.
- Tiene valores predeterminados habilitados para la mayoría de las implementaciones. Los cambios de configuración se pueden realizar en el archivo Cassandra.yml donde está presente el umbral dinámico de snitch para cada nodo.
5. Merkle Tree
- Puede haber diferencias en los bloques de datos. Para encontrar las diferencias fácilmente, el árbol Merkle es un árbol hash que ayuda a hacer esto.
- Los nodos de hoja del árbol de hash contienen hashes de bloques de datos separados y los nodos principales tienen la información o también almacenan los hash de sus hijos.
- Al usar esta técnica, es más fácil encontrar diferencias entre los nodos que están presentes.
6. Mem Table
- Esta tabla tiene información sobre el caché cuyos datos aún no se han vaciado y residen en la memoria.
Conclusión
Cassandra es una base de datos NoSQL que es útil para procesar grandes cantidades de datos. No tiene una arquitectura típica maestro-esclavo y, por lo tanto, todos los nodos son igualmente importantes. Los nodos tienen réplicas en todo el clúster según el factor de replicación. Esto asegura la consistencia y durabilidad de los datos. Con todas estas características, está claro que Cassandra es muy útil para big data. Por lo tanto, Cassandra es duradera, rápida, ya que se distribuye y es confiable.
Artículos recomendados
Esta es una guía de la arquitectura Cassandra. Aquí discutimos la Introducción, la arquitectura de Cassandra, la estructura clave y los componentes clave de Cassandra. También puede consultar nuestros otros artículos sugeridos:
- Descripción general de la arquitectura de Kubernetes
- ¿Qué es la arquitectura de Big Data?
- Características agregadas a la arquitectura de AutoCAD
- Arquitectura de computación en la nube